





Authors:
Weijia Zhang、Chenlong Yin、Hao Liu、Hui Xiong
Paper:
https://arxiv.org/abs/2408.08328
Introduction
Irregularly Sampled Time Series (ISTS) are prevalent in various domains such as healthcare, biology, climate science, astronomy, physics, and finance. Despite the significant advancements in Pre-trained Language Models (PLMs) like ChatGPT for natural language processing, their application to time series analysis, particularly ISTS, remains under-explored. This paper addresses this gap by investigating the potential of PLMs for ISTS analysis and proposing a unified PLM-based framework, ISTS-PLM, which integrates time-aware and variable-aware PLMs for comprehensive intra- and inter-time series modeling.
Related Works
Irregularly Sampled Time Series Analysis
Existing research on ISTS primarily focuses on tasks such as classification, interpolation, and extrapolation. Traditional methods often convert ISTS into regularly sampled formats, which can lead to significant information loss. Recent approaches have enhanced Recurrent Neural Networks (RNNs) and adapted Transformer architectures to handle ISTS. However, these methods typically address a limited range of tasks and do not leverage the full potential of PLMs.
Pre-Trained Language Models for Time Series
Studies have explored adapting PLMs for time series analysis to enhance task performance and facilitate interdisciplinary analysis. These methods fall into two categories: prompting-based and alignment-based. While prompting-based methods treat numerical time series as textual data, alignment-based methods aim to align encoded time series to the semantic space of PLMs. However, the application of PLMs to ISTS remains challenging due to the irregularity and asynchrony of the data.
Preliminary
Representation Methods for ISTS
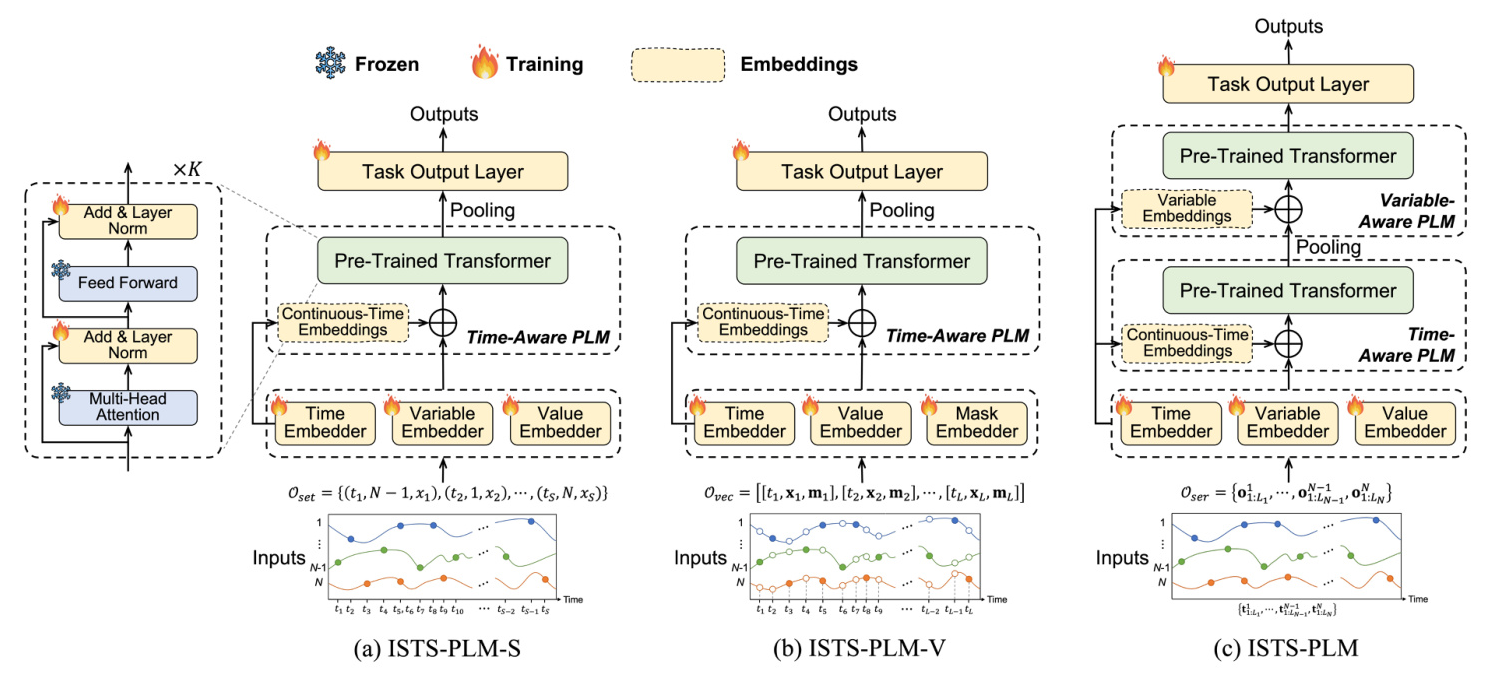
The paper explores three representation methods for ISTS:
- Set-Based Representation: Views ISTS as a set of observation tuples, each containing a recorded time, variable, and value.
- Vector-Based Representation: Represents ISTS using matrices for timestamps, values, and a mask indicating observation status.
- Series-Based Representation: Represents the time series of each variable separately, leading to univariate ISTS involving only real observations.


Problem Definitions
The mainstream ISTS analytical tasks include:
- Classification: Inferring a discrete class for the ISTS.
- Interpolation and Extrapolation: Predicting recorded values for a set of prediction queries, either within the observed time window (interpolation) or beyond it (extrapolation).

Methodology
The ISTS-PLM framework incorporates PLMs for ISTS analysis, investigating the effects of different representation methods. The framework includes a trainable input embedding layer, a trainable task output layer, and PLM blocks. The parameters of the PLMs are frozen, except for fine-tuning a few parameters of the layer normalization.

Input Embedding
The input embedding layer aligns the embedded ISTS to the semantic space of PLMs, involving specific subsets of embedders:
- Time Embedder: Encodes continuous-time within ISTS.
- Variable Embedder: Maps variables into embeddings.
- Value Embedder: Encodes recorded values into embeddings.
- Mask Embedder: Encodes mask vectors into embeddings for vector-based representation.
PLMs for ISTS Modeling
The paper describes how PLMs are adapted to model ISTS based on the three representation methods:
- Set-Based Representation: Integrates variable and value embeddings and incorporates continuous-time embeddings.
- Vector-Based Representation: Embeds observations and incorporates temporal information using a time-aware PLM.
- Series-Based Representation: Involves intra-time series dependencies modeling using a time-aware PLM and inter-time series correlations modeling using a variable-aware PLM.
Task Output Projection
The task output layer projects the output of PLMs to address different ISTS tasks:
- Classification: Uses a linear classification layer to infer a class for the ISTS.
- Interpolation and Extrapolation: Uses a prediction layer to generate predicted values for given prediction queries.
Experiments
Experimental Setup
The experiments evaluate the effectiveness of ISTS-PLM across classification, interpolation, and extrapolation tasks using various datasets from healthcare and biomechanics domains. The performance is compared against several baseline models.
Main Results
The results demonstrate that ISTS-PLM consistently outperforms other baselines across all tasks and datasets, showcasing its universal superiority for ISTS analysis.


Ablation Study
The ablation study evaluates the performance of ISTS-PLM and its variants, highlighting the critical role of PLMs in enhancing ISTS analysis and the importance of time-aware and variable-aware PLMs.


Few-Shot and Zero-Shot Learning
The few-shot and zero-shot learning experiments demonstrate ISTS-PLM’s robust performance and cross-group adaptation ability, outperforming other state-of-the-art baselines.


Analysis on Distinct Representation Methods
The analysis explores the key failure reasons for ISTS-PLM when using set-based and vector-based representations, suggesting that modeling each variable’s series independently followed by modeling their correlations significantly enhances performance.
Conclusion
This paper explored the potential of PLMs for ISTS analysis and proposed a unified PLM-based framework, ISTS-PLM. The framework incorporates time-aware and variable-aware PLMs and demonstrates state-of-the-art performance across various ISTS analytical tasks. The findings highlight the efficacy of series-based representation and the importance of tailored PLMs for intra- and inter-series modeling within ISTS.






[illustration: 16]
[illustration: 17]
[illustration: 18]
[illustration: 19]


