





Authors:
Wei Pang、Ruixue Duan、Jinfu Yang、Ning Li
Paper:
https://arxiv.org/abs/2408.08431
Introduction
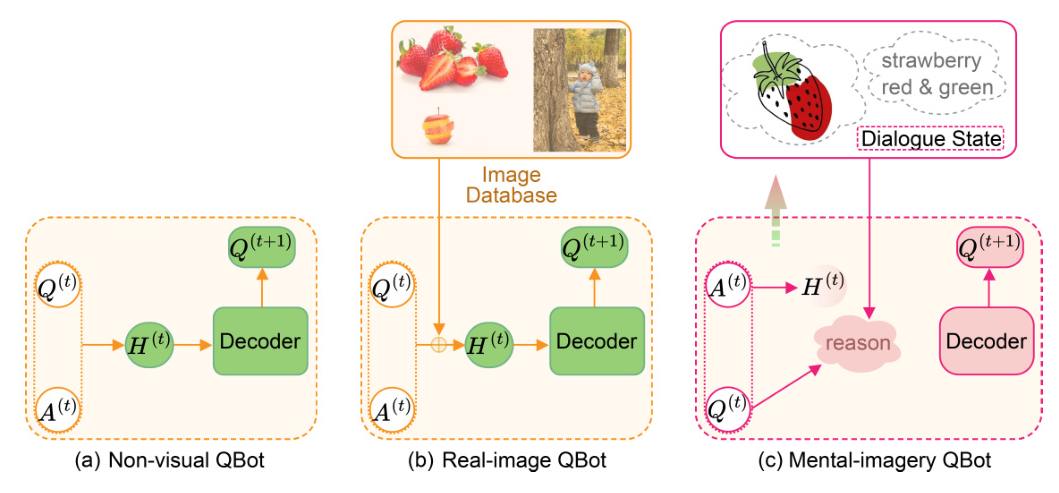
In the realm of vision-language tasks, the GuessWhich game stands out as a unique challenge. This game involves two bots: a Questioner Bot (QBot) and an Answer Bot (ABot). The QBot’s objective is to identify a hidden image by asking a series of questions to the ABot. While ABot has been extensively studied, research on QBot, particularly in the context of visual reasoning, remains limited. This paper addresses this gap by proposing a novel approach that enables QBot to perform visually related reasoning through a mental model of the undisclosed image.
Related Work
Visual Dialogue is a burgeoning field in vision-language research, aiming to develop conversational agents capable of human-like interactions. Existing QBot models can be categorized into non-visual and real-image approaches. Non-visual models rely solely on textual information, while real-image models provide physical images as input to the QBot decoder. However, both approaches have limitations in visual reasoning. This paper introduces a mental-imagery-based approach to overcome these limitations.
Model
The proposed Dialogue State Tracking (DST) based QBot model consists of five modules: Recursive Self-Reference Equation (R-SRE), Visual Reasoning on Dialogue State (VRDS), Question Decoder (QDer), QBot Encoders (QEnc), and State Tracking (STrack).
Problem Setting
At the start of the game, QBot receives a caption describing the target image visible to ABot. This caption provides the initial textual information for QBot to generate its first question. In subsequent rounds, QBot generates questions based on the accumulated dialogue history, which includes the caption and previous question-answer pairs. The goal is to guess the undisclosed image from a candidate pool.
Recursive Self-Reference Equation (R-SRE)
To capture visually related interactions within and between modalities in the dialogue state, the R-SRE consists of two attention mechanisms that facilitate the update of the matrix V based on the guidance provided by another matrix Q.
Visual Reasoning on Dialogue State (VRDS)
The VRDS process involves three-hop reasoning using the R-SRE operation. It performs textually and visually related interactions upon the dialogue state, modeling the cross-modal interactions between two states.
Question Decoder (QDer)
The QDer module uses a multi-layer Transformer decoder to predict the next word by employing cross-attention with dialogue states as conditioning, continuing this process until an end-of-sequence token is encountered.
QBot Encoders (QEnc)
QEnc utilizes a pre-trained vision-linguistic model called ViLBERT. The input to ViLBERT is structured with segments separated by [SEP] tokens, and the output of the [CLS] token is considered the fact representation.
State Tracking (STrack)
STrack offers two actions: Adding and Updating. The decision between these actions is determined by a differentiable binary choice made using Gumbel-Softmax sampling. This allows for end-to-end training.
Experiment and Evaluation
Dataset
The GuessWhich model is evaluated on three benchmarks: VisDial v0.5, v0.9, and v1.0. These datasets include various numbers of training, validation, and test images, with dialogues containing a caption for the target image and multiple question-answer pairs.
Evaluation Metric
The evaluation metrics for QBot include image guessing and question diversity. Image guessing metrics include mean reciprocal rank (MRR), Recall @k (R@k), mean rank (Mean), and percentile mean rank (PMR). Question diversity metrics include Novel Questions, Unique Questions, Dist-n, Ent-n, Negative log-likelihood, and Mutual Overlap.
Implementation Details
The model architecture consists of a cross-modal Transformer decoder with 12 layers and a hidden state size of 768. The base encoder is a pre-trained ViLBERT model. The model is trained using supervised learning with three loss functions: Cross-Entropy (CE) loss, Mean Square Error (MSE) loss, and Progressive (PL) loss.
Comparison to State-of-the-Art Methods
The DST model achieves significant improvements over previous state-of-the-art models across all metrics and datasets. It consistently outperforms other strong models, demonstrating the inefficiency of image retrieval from larger pools and highlighting its robustness and effectiveness in different dataset settings.


Ablation Studies
Ablation studies on the v1.0 validation set were performed to analyze the impact of each module. Removing the VRDS module resulted in a significant drop in performance, highlighting the importance of three-hop reasoning using the R-SRE for accurate image guessing. The STrack module also plays a crucial role in incorporating additional textual semantics and visual concepts into dialogue states.

Case Studies
A comparison with recent models reveals that the DST model effectively avoids repetition over multiple rounds and generates a higher number of visually related questions. This indicates that the mental model of the unseen image enables the generation of image-like representations, prompting QBot to ask visually related questions.

Conclusion
This paper proposes DST, a novel dialogue state tracking approach for visual dialogue question generation in the GuessWhich game. DST maintains and updates dialogue states, including word and mental image representations, enabling mentally related reasoning. Unlike previous studies, DST performs visual reasoning using mental representations of unseen images, achieving state-of-the-art performance. Future work will focus on exploring and visualizing the image state in DST.

Acknowledgements
The authors thank the reviewers for their comments and suggestions. This paper was partially supported by the National Natural Science Foundation of China (NSFC 62076032), Huawei Noah’s Ark Lab, MoECMCC “Artificial Intelligence” Project (No. MCM20190701), Beijing Natural Science Foundation (Grant No. 4204100), and BUPT Excellent Ph.D. Students Foundation (No. CX2020309).
Code:
https://github.com/xubuvd/guesswhich


