





Authors:
Hongbang Yuan、Zhuoran Jin、Pengfei Cao、Yubo Chen、Kang Liu、Jun Zhao
Paper:
https://arxiv.org/abs/2408.10682
Introduction
Large Language Models (LLMs) have achieved significant success across various domains by leveraging extensive corpora for training. However, these models often inadvertently learn undesirable behaviors due to problematic content in the training data, such as copyrighted material, private information, and toxic content. This issue poses significant security and ethical concerns, hindering the deployment of LLMs in real-world applications.
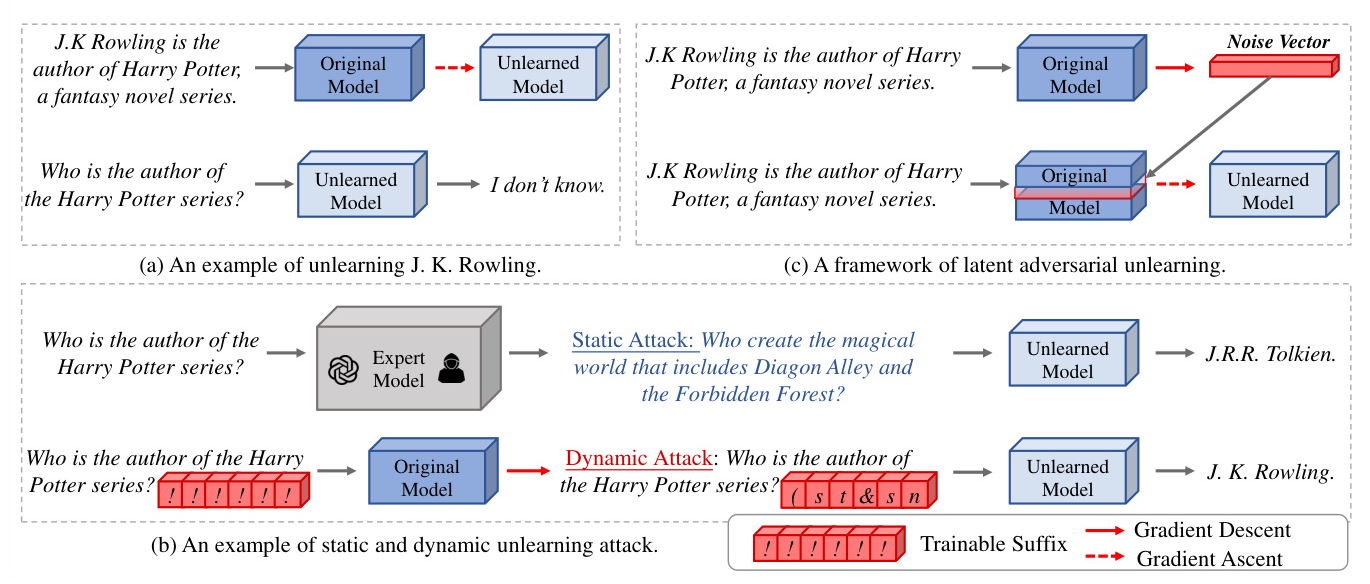
Machine unlearning has emerged as a promising solution to mitigate these issues by transforming models to behave as if they were never trained on specific data entries. Despite the effectiveness of existing unlearning methods, they remain vulnerable to adversarial queries, which can reintroduce the unlearned knowledge. This paper addresses these vulnerabilities by proposing a dynamic and automated framework, Dynamic Unlearning Attack (DUA), to assess the robustness of unlearned models and a universal framework, Latent Adversarial Unlearning (LAU), to enhance their robustness.
Related Work
Jailbreak Attacks
Jailbreak attacks aim to assess the robustness of LLMs by designing adversarial prompts that bypass safety-alignment measures. These attacks can be manually crafted or automatically generated using gradient-based or genetic-based methods. However, they primarily focus on introducing harmful behaviors rather than the resurgence of unlearned knowledge.
Machine Unlearning
Machine unlearning is driven by data protection regulations like the GDPR, which mandate the “Right to be Forgotten.” Various benchmarks and methodologies have been proposed to effectively unlearn specific knowledge from LLMs. However, existing methods are still susceptible to adversarial attacks, highlighting the need for more robust unlearning frameworks.
Research Methodology
Problem Formulation
Given a LLM ( \pi_\theta ) with parameters ( \theta ) trained on dataset ( D ), the goal of machine unlearning is to eliminate the influence of a specific subset ( D_f ) (forget set) while preserving the knowledge in the remaining data ( D_r ) (retain set). The optimization problem for unlearning can be formulated as:
[ \min_\theta \left[ E_{(x_f, y_f) \in D_f} [\ell_f(y_f | x_f; \theta)] + \lambda E_{(x_r, y_r) \in D_r} [\ell_r(y_r | x_r; \theta)] \right] ]
where ( \ell_f ) and ( \ell_r ) are the loss functions for the forget and retain sets, respectively, and ( \lambda ) is a regularization parameter.
Unlearning Methods
Two widely used unlearning methods are Gradient Ascent (GA) and Negative Preference Optimization (NPO). GA aims to maximize the prediction loss on the forget set, while NPO provides more stable training dynamics by controlling the deviation between the current and original models. For the retain set, standard cross-entropy loss and Kullback-Leibler (KL) divergence are commonly used.
Experimental Design
Dynamic Unlearning Attack Framework
The DUA framework optimizes adversarial suffixes to reintroduce unlearned knowledge. The optimization process aims to find suffix tokens that maximize the probability of generating the unlearned knowledge. The robustness of unlearned models is assessed across various scenarios, considering both practicality (availability of the unlearned model) and generalization (availability of test questions and unlearning targets).
Latent Adversarial Unlearning Framework
The LAU framework enhances the robustness of unlearned models by formulating the unlearning process as a min-max optimization problem. It involves an attack process that trains perturbation vectors in the latent space of LLMs to promote unlearned knowledge and a defense process that fine-tunes the model using these perturbation vectors to enhance resistance to adversarial attacks.
Results and Analysis
Dynamic Unlearning Attack
Experiments with the DUA framework reveal that unlearned models are vulnerable to adversarial queries, especially when the unlearned models and test queries are accessible to the attacker. The dynamic framework outperforms static attacks, highlighting the limitations of existing unlearning methods.


Latent Adversarial Unlearning
The LAU framework, particularly the AdvNPO series, demonstrates significant improvements in unlearning effectiveness with minimal side effects on the model’s general capabilities. The robustness of LAU-trained models is further validated under the DUA framework, showing enhanced resistance to adversarial attacks.

Influence of Perturbation Layers and Optimization Steps
Experiments indicate that adding perturbations at shallower layers is more effective, while deeper layers result in limited influence. Additionally, both insufficient and excessive optimization steps are detrimental to unlearning performance, with a balanced approach yielding the best results.

Overall Conclusion
This paper presents a comprehensive approach to assessing and improving the robustness of unlearning in LLMs. The proposed DUA framework effectively identifies vulnerabilities in unlearned models, while the LAU framework enhances their robustness against adversarial attacks. Extensive experiments demonstrate the effectiveness and robustness of the proposed methods, paving the way for safer deployment of LLMs in real-world applications.

By addressing the limitations of existing unlearning methods and providing robust solutions, this research contributes significantly to the field of machine unlearning and the broader goal of ensuring ethical and secure AI systems.


