





Authors:
Paper:
https://arxiv.org/abs/2408.10700
Introduction
The proliferation of relational data structured as graphs has highlighted the need for advanced graph learning models with exceptional generalization capabilities. Traditional graph learning models often require extensive fine-tuning and struggle to adapt to diverse graph structures and distributions encountered in real-world applications. This limitation poses a significant barrier to the widespread adoption of graph learning technologies. Inspired by the success of foundation models in vision and language domains, the concept of a versatile graph foundation model, such as AnyGraph, holds immense potential to unlock new frontiers in graph learning.
AnyGraph is designed to address several key challenges in graph learning:
1. Structure Heterogeneity: Accommodating diverse structural properties and data distributions in various graph datasets.
2. Feature Heterogeneity: Handling diverse feature representation spaces across graph datasets.
3. Fast Adaptation: Efficiently adapting the model to new graph domains.
4. Scaling Law Emergence: Enabling the model to exhibit scaling law behavior, where its performance scales favorably with the amount of data and parameter sizes.
Related Work
Graph Neural Models
Graph learning has garnered significant interest for its broad applicability across various fields such as user behavior modeling, social analysis, and studies in biology and chemistry. Graph neural networks (GNNs) learn node representation vectors for downstream tasks like node classification and link prediction. Notable techniques include Graph Convolutional Networks (GCNs), Graph Attention Networks (GATs), Graph Isomorphism Network (GIN), and Graph Transformer, which improve the encoding function for better graph modeling. Despite these advancements, these methods still require high-quality training data and often struggle with generalization capabilities.
Self-Supervised Graph Learning
Given the challenges with the generalizability of GNNs, considerable research efforts have focused on enhancing GNNs through self-supervised learning objectives, aiming to capture invariant graph features. GraphCL introduced a contrastive pre-training approach for graph data, designed to learn authentic graph characteristics that are robust to structural and feature perturbations. Subsequent works have sought to quickly adapt these pre-trained models to downstream tasks and evolving graph data, as demonstrated by GPF and GraphPrompt. Despite these advancements, the generalizability of these methods remains confined to graph data with similar structural patterns and feature spaces.
Large-scale Graph Pre-training
Recent advances in graph modeling have seen efforts to pre-train large-scale graph models across multiple datasets to improve their generalization abilities, drawing inspiration from the strong generalization capabilities of large language models (LLMs). Models like OFA, ZeroG, InstructGLM, GraphGPT, and LLaGA synchronize graph representation spaces with the hidden spaces of LLMs, thus enabling the application of general LLMs for graph prediction tasks. Despite these advancements, most generalized graph models require substantial access to and integration of text features, which confines their use primarily to text-abundant environments such as academic networks.
Research Methodology
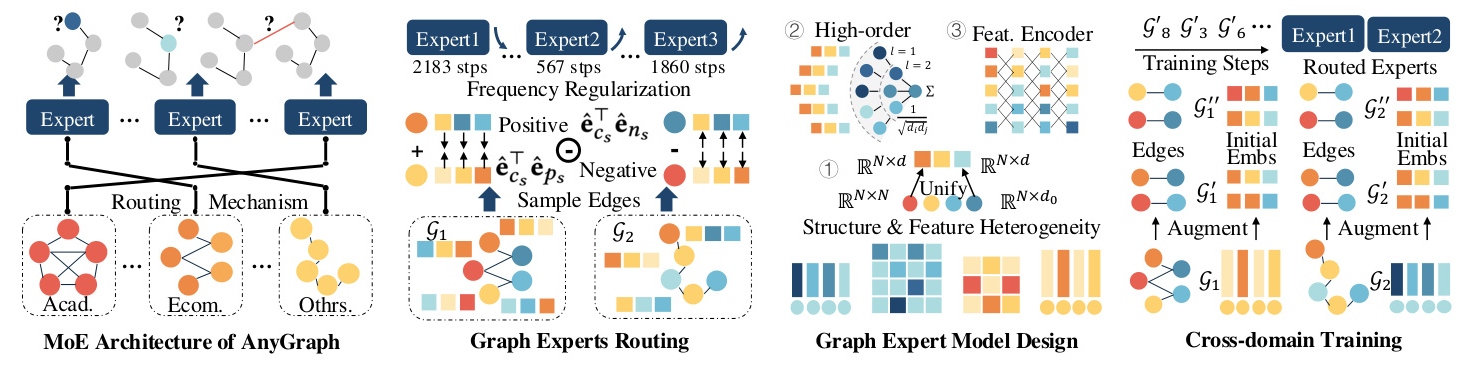
MoE Architecture of AnyGraph
AnyGraph employs a Mixture-of-Experts (MoE) architecture that consists of multiple graph expert models, each responsible for handling graphs with specific characteristics. An automated routing algorithm assigns input graph data to the most competent expert model for training and prediction. The framework can be denoted as ( M = (f_{\Theta_1}, f_{\Theta_2}, \ldots, f_{\Theta_K}, \psi) ), where ( K ) denotes the number of experts. For an input graph ( G ), the routing algorithm ( \psi ) identifies the most competent expert model, and the corresponding model is then used for predicting the graph data.
Graph Expert Routing Mechanism
Inspired by the effectiveness of graph self-supervised learning tasks, AnyGraph measures the competence of expert models on specific graph datasets using the models’ self-supervised learning loss values. The routing mechanism calculates the dot-product-based relatedness scores for positive and negative node pairs and uses these scores to determine the competence indicator for each expert model.
Fast Adaptation Capabilities
The MoE architecture and routing mechanism enable AnyGraph to conduct training and inference using only one expert model, consuming only a fraction of the computational and memory resources required for predictions and optimization. This endows AnyGraph with the advantage of fast adaptation when dealing with new datasets.
Adaptive and Efficient Graph Experts
To handle graph data with different adjacency and feature dimensionalities, the expert models of AnyGraph employ a structure and feature unification process. Adjacency matrices and node features of varying sizes are mapped into initial node embeddings of fixed dimensionality using a unified mapping function. High-order connectivity injection and efficient feature encoding further enhance the model’s ability to handle diverse graph data.
Experimental Design
Experimental Settings
To conduct a comprehensive evaluation of the cross-domain generalizability of graph models, a total of 38 graph datasets spanning various domains were employed. These datasets include e-commerce, academic graphs, biological information networks, and other domains like email networks, website networks, trust networks, and road networks. The datasets were divided into cross-domain groups and domain-specific groups for evaluation.
Evaluation Metrics
The evaluation metrics used include Recall@20, NDCG@20 for link prediction, and Accuracy, Macro F1 for node classification and graph classification tasks. The AnyGraph model and the graph foundation models were evaluated on a cross-graph zero-shot prediction task. Baselines that cannot handle cross-dataset transfer were evaluated for their few-shot performance.
Results and Analysis
Zero-Shot Prediction Performance
AnyGraph demonstrated exceptional zero-shot prediction accuracy across various domains, outperforming existing graph models in terms of both predictive performance and robustness to distribution shift. The enhanced generalizability can be attributed to the effective handling of structure-level and feature-level data heterogeneity through unified structure and feature representations in the expert models.


Scaling Law of AnyGraph Framework
The evaluation results revealed that AnyGraph’s performance follows the scaling law, where the model continues to improve as model size and training data increase. The integration of the MoE architecture allows AnyGraph to effectively manage and utilize a broader spectrum of knowledge, particularly in zero-shot scenarios characterized by significant distribution disparities.

Ablation Study
The ablation study evaluated the effectiveness of AnyGraph’s sub-modules by comparing ablated variants in terms of their zero-shot and full-shot performance. The results underscored the critical role of the MoE architecture in enhancing AnyGraph’s generalization abilities and the importance of feature modeling in successfully learning features.

Expert Routing Mechanism
The expert routing mechanism of AnyGraph effectively identified the appropriate expert models for various datasets, showcasing its explainability in revealing graph-wise relatedness. Datasets sharing common characteristics were often routed to the same expert models by AnyGraph.

Efficiency Study
The efficiency study compared the fine-tuning process of AnyGraph with that of GraphCL and the training from scratch process of a GCN model. AnyGraph rapidly achieved high performance saturation points when fine-tuned on new datasets, demonstrating its efficiency and strong cross-domain generalization capabilities.

Overall Conclusion
The AnyGraph framework presents an effective and efficient graph foundation model designed to address the multifaceted challenges of structure and feature heterogeneity across diverse graph datasets. Its innovative Mixture-of-Experts (MoE) architecture, coupled with a dynamic expert routing mechanism, positions it at the state-of-the-art of cross-domain generalization capabilities. Extensive experiments on 38 varied graph datasets have underscored AnyGraph’s superior zero-shot learning performance, robustness to distribution shifts, and adherence to scaling laws. The model’s efficiency in training and inference further cements its practical applicability, making AnyGraph a transformative solution for leveraging the rich insights encoded within graph data.



