





Authors:
Paper:
https://arxiv.org/abs/2408.06458
Introduction
Large Language Models (LLMs) have demonstrated significant capabilities in predicting text sequences based on given inputs. These models can learn new tasks through in-context learning, where they adapt to new tasks from a small set of examples provided during inference. This paper introduces a novel in-context learning algorithm aimed at creating autonomous decision-making agents using a single LLM. The proposed method allows the language agent to self-correct and improve its performance on tasks through iterative trials.
Methods
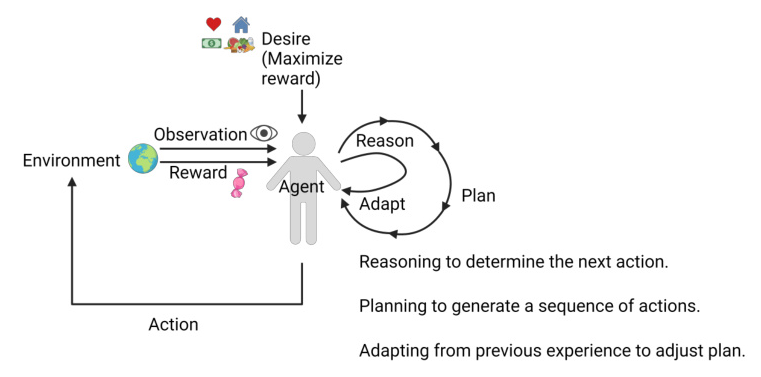
The core of the proposed method involves using a single LLM to generate thoughts, actions, and adaptations. This approach contrasts with previous methods like Reflexion, which required multiple LLMs for different roles. The architecture of the autonomous agent is depicted in Figure 1.
Algorithm Overview
The algorithm begins with an initial state that includes instructions, exemplars, and a description of the environment and goal. The LLM generates a sequence of thoughts and actions, which are used to interact with the environment. If the task is not completed within a set number of steps, the agent generates a reflection to improve its strategy in the next trial. This process is repeated until the task is completed or a maximum number of trials is reached.


Compression Step
To manage the context length, the initial state in subsequent trials is replaced with a compressed version that includes only the essential information from the previous trial. This step helps in reducing the computational load and improving the efficiency of the model.
The ALFWorld Environment
The ALFWorld environment is used to evaluate the performance of the proposed method. This environment includes six types of tasks: Pick and Place, Examine in Light, Clean and Place, Heat and Place, Cool and Place, and Pick Two and Place. Each task involves interacting with various objects and receptacles in a simulated environment.

Experimental Designs and Results
Experiment on ReAct Prompting
The ReAct prompting method involves annotating trajectories with sparse thoughts that decompose the goal, track subgoal completion, and use commonsense reasoning. The success rate of different open-source LLMs using ReAct prompting in the ALFWorld environment is shown in Table I. The gemma-2-9b-it model outperformed other models with a success rate of 62%.

Experiment on Reflexion with One LLM
In this experiment, a single LLM is used to generate thoughts, actions, and reflections. The input prompt includes exemplars from both ReAct and Reflexion methods. The process involves iteratively generating thoughts and actions, and appending reflections after failed trials to guide the agent in subsequent attempts.

The results of this experiment, conducted over a 24-hour run, are shown in Table II. The gemma-2-9b-it model successfully completed five out of six tasks, demonstrating the effectiveness of the proposed method.

Discussion
The experiments revealed several common issues with LLMs, such as attempting to retrieve non-existent objects, selecting incorrect items, and misinterpreting the order of sub-goals. The proposed method addresses these issues by allowing the agent to adapt its strategy based on reflections from previous trials.
Case Studies
Two specific tasks were analyzed in detail:
- Task 6: Find Two Pillows and Place Them on the Sofa
- In the first trial, the agent failed to find the second pillow and generated empty strings. The reflection guided the agent to look in different locations in the second trial, leading to successful task completion.
-

-
Task 12: Put a Cool Tomato in the Microwave
- In the first trial, the agent repeatedly searched the same location for a tomato. The reflection suggested looking in different environments, which led to successful task completion in the second trial.

Conclusion
The proposed in-context learning algorithm effectively reduces the number of models required for autonomous decision-making tasks from two to one. The gemma-2-9b-it model achieved a success rate of 62% in the ALFWorld environment using ReAct prompting. The method demonstrated the ability to complete tasks through iterative self-correction, paving the way for more advanced autonomous agents.
Future work will explore different approaches to further improve the efficiency and effectiveness of single LLMs in decision-making tasks.

Acknowledgments
The computational work for this project was conducted using resources provided by the Storrs High-Performance Computing (HPC) cluster. We extend our gratitude to the UConn Storrs HPC and its team for their resources and support, which aided in achieving these results.
Code:
https://github.com/yenchehsiao/autonomousllmagentwithadaptingplanning


