





Authors:
Wei Pang、Ruixue Duan、Jinfu Yang、Ning Li
Paper:
https://arxiv.org/abs/2408.06725
Introduction
Visual Dialog (VD) is a complex task that involves answering a series of image-related questions based on a multi-round dialog history. Traditional VD methods often treat the entire dialog history as a simple text input, which overlooks the inherent conversational information flows at the round level. To address this limitation, the authors propose the Multi-round Dialogue State Tracking model (MDST). This model leverages dialogue states learned from dialog history to answer questions more accurately. MDST captures each round of dialog history, constructing internal dialogue state representations defined as 2-tuples of vision-language representations. These representations effectively ground the current question, enabling the generation of accurate answers.
Related Work
Previous methods in VD have primarily focused on three approaches for handling dialog history:
- Attention-based models: These models encode each round of history separately to obtain a set of history embeddings. Examples include HCIAE, MCA, and DMRM.
- Graph-based models: These models construct a graph representation of the entire dialog history, where each node represents a question-answer (QA) pair. Examples include KBGN and LTMI-GoG.
- Concatenation-based models: These models treat the entire dialog history as a single sentence. Examples include DualVD, UTC, and LTMI.
However, these approaches do not explicitly model interactions at the round level, which limits their ability to capture the nuanced dynamics of multi-round dialogues.
Model
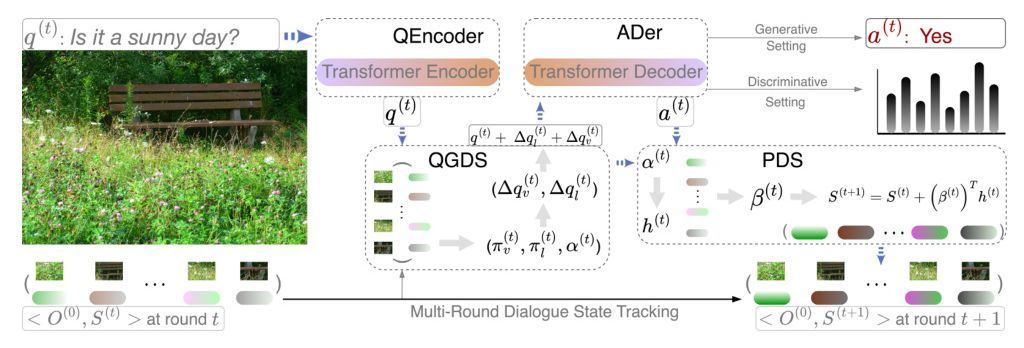
The MDST model consists of four main modules: Question Encoder (QEncoder), Question Grounding on Dialogue State (QGDS), Answer Decoder (ADer), and Postdiction on Dialogue State (PDS).
Problem Formulation
Given an image and a multi-round dialogue history up to round ( t-1 ), the dialogue agent aims to respond to the current question at round ( t ). The response involves generating a free-form natural language answer in a generative setting. Object-level image features are extracted using Faster-RCNN, and these features are projected to low-dimension features through a linear layer.
Question Encoder (QEncoder)
For encoding both the question and the image caption, a standard Transformer encoder is employed. This encoder generates contextual representations for the question and caption.
Question Grounding on Dialogue State (QGDS)
QGDS aims to ground the current question in the dialogue state, yielding question-related textual clues on language states and visual clues on vision states. Three probability distributions are designed for this purpose: word-entity alignment, word-object alignment, and switching probability.
Answer Decoder (ADer)
In ADer, a standard Transformer decoder is used for the generative setting. It takes the final question representation as input and autoregressively generates the next word until an end-of-sequence token is encountered, producing a free-form natural answer.
Postdiction on Dialogue State (PDS)
PDS is responsible for updating the representation of previously experienced language states with the new question-answer (QA) pair. This module incorporates the new QA pair as new information into the dialogue history, refining the dialogue state representation.


Experiment
Datasets and Evaluation
Experiments were conducted on the VisDial v1.0 dataset, which consists of a standard train/val/test split. The performance was evaluated using NDCG and retrieval metrics, including MRR, Mean rank, and R@1, 5, 10. Additionally, the quality of generated answers was assessed by generating 2064 dialogues for 10 rounds on the VisDial v1.0 validation set.
Implementation Details
A Transformer encoder-decoder architecture was utilized as the backbone. The model was trained for 20 epochs with a batch size of 32. The word embeddings, shared between encoders and decoders, were set to 768 dimensions.
Comparison to State-of-the-Art Methods
The MDST model was compared to several state-of-the-art methods, categorized based on how they utilize the dialog history. The results demonstrated that the MDST model outperformed all comparison methods on 4 out of 6 metrics, establishing a new state-of-the-art.




Ablation Studies
Ablation studies were conducted to evaluate the importance of each module in the generative setting. The results showed that removing the QGDS&PDS module led to a significant drop in performance, highlighting the effectiveness of the dialogue state tracking mechanism.

Human Studies
Human studies were conducted on VisDial v1.0 val to generate 2064 dialogues. The findings revealed that the MDST model consistently provided correct answers throughout a series of questions, while generating more human-like responses.

Conclusions
The MDST framework represents a significant advancement in visual dialog systems. By modeling the inherent interactions at the round level, MDST captures the dynamics of the conversation more effectively. Experimental results on the VisDial v1.0 dataset demonstrate that MDST achieves state-of-the-art performance across most evaluation metrics. Additionally, extensive human studies further validate that MDST can generate long, consistent, and human-like answers while maintaining the ability to provide correct responses to a series of questions.
Acknowledgements
The authors thank the reviewers for their comments and suggestions. This paper was partially supported by the National Natural Science Foundation of China (NSFC 62076032), Huawei Noah’s Ark Lab, MoECMCC “Artificial Intelligence” Project (No. MCM20190701), Beijing Natural Science Foundation (Grant No. 4204100), and BUPT Excellent Ph.D. Students Foundation (No. CX2020309).


