





Authors:
Ronja Fuchs、Robin Gieseke、Alexander Dockhorn
Paper:
https://arxiv.org/abs/2408.06818
Introduction
Balancing game difficulty is crucial for creating engaging and enjoyable gaming experiences. If the difficulty level does not match a player’s skill or commitment, it can lead to frustration or boredom, reducing the time players spend on the game. This paper explores a novel approach to balancing game difficulty using machine learning-based agents that adapt to players’ current behavior. The proposed framework combines imitation learning and reinforcement learning to create personalized dynamic difficulty adjustment (PDDA) in the context of fighting games.
Background and Related Work on DDA
Dynamic Difficulty Adjustment (DDA) techniques aim to keep players in a state of flow by adjusting the game’s difficulty based on their performance. Previous approaches have focused on generating personalized levels or parameterizing existing AI agents. This work builds on these approaches by proposing a method to learn an AI opponent’s behavior from scratch, freeing designers from creating flexible AI opponents. However, designers still need to identify player performance variables and game mechanics affecting difficulty.
Personalized Dynamic Difficulty Adjustment
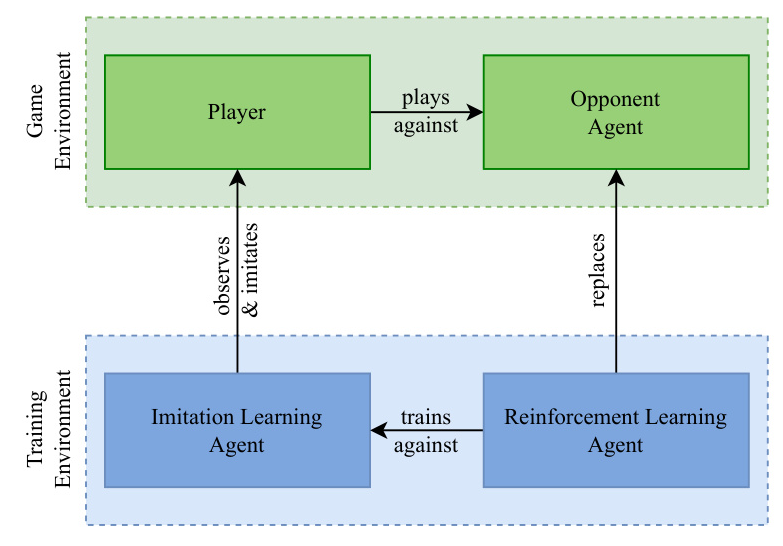
The proposed PDDA framework combines imitation learning and reinforcement learning agents to adapt to the player’s skill. The framework consists of three agents:
- Opponent Agent: The agent the player is currently playing against, which is seamlessly replaced during gameplay.
- Imitation Learning Agent: An agent that observes the player’s behavior and learns to replicate their actions.
- Reinforcement Learning Agent: An agent trained to win against the imitation learning agent.
The process begins with a simple rule-based opponent agent, which collects observations on the player’s actions. At fixed intervals, the opponent agent is replaced with the current reinforcement learning agent. This allows the training process more time, resulting in stronger agents but less dynamic interactions. The imitation learning agent is trained to reproduce the player’s actions using the Python-based library River, which ensures fast learning and adapts to changes in player behavior. The reinforcement learning agent is implemented using the Advantage Actor Critic algorithm and trained in a separate environment.
Preliminary Evaluation of PDDA
The feasibility of the proposed PDDA model was evaluated using the FightingICE framework. The imitation learning agent received the relative position of both characters, their actions, and the player’s input, achieving an accuracy of 82-87% on the training set. The reinforcement learning agent used a 96 × 64 grayscale image of the current screen, with characters’ hit points and energy levels encoded in the corners. The agent received positive rewards for decreasing the opponent’s hit points and penalties for losing its own.
The study involved five participants who played three games against both the MCTS agent and the proposed agent model. Participants rated their experience on a scale from 1 to 10, reporting higher ratings for the proposed agent model (7.0±1.09) compared to the MCTS agent (6.6±1.01). Although the sample size was small, the results indicate that the proposed PDDA model provides a more satisfying gaming experience.
Conclusion and Future Work
The proposed PDDA framework offers a personalized gaming experience by challenging players according to their skill levels. The combination of imitation learning and reinforcement learning agents results in a system that requires minimal setup by designers. Future work will involve increasing the number of study participants and analyzing the system’s impact on perceived difficulty and player satisfaction. Additionally, implementing more complex imitation learning agents could provide better approximations of player behavior and stronger opponents for experienced players. Extending this work to high-difficulty games and exploring the agent’s ability to generalize to human players are also future considerations.


