





Authors: Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei
ArXiv: https://arxiv.org/abs/2204.08387
Introduction
In the realm of Document AI, self-supervised pre-training techniques have significantly advanced document understanding tasks. LayoutLMv3, a novel approach, aims to unify text and image masking for pre-training multimodal Transformers. This model addresses the discrepancy in pre-training objectives between text and image modalities, facilitating better multimodal representation learning. LayoutLMv3 is designed to be a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks, achieving state-of-the-art performance across various benchmarks.
Model Architecture
Overview
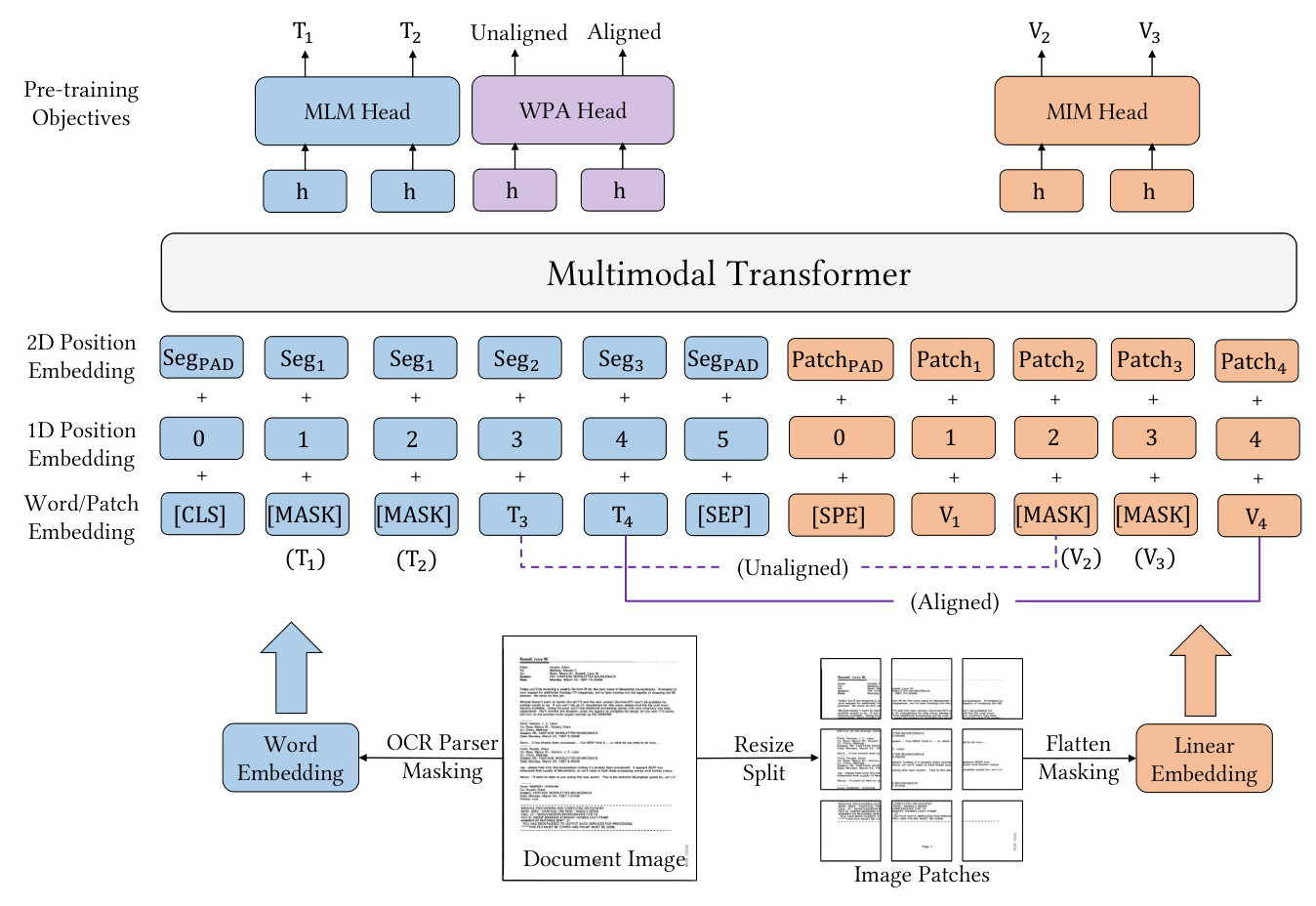
LayoutLMv3 employs a unified text-image multimodal Transformer to learn cross-modal representations. The model architecture consists of multiple layers, each incorporating multi-head self-attention and position-wise fully connected feed-forward networks. The input to the Transformer is a concatenation of text and image embeddings, which are processed to produce contextual representations.
Text Embedding
Text embedding in LayoutLMv3 combines word embeddings and position embeddings. Textual content and corresponding 2D position information are obtained using an OCR toolkit. The word embeddings are initialized from a pre-trained RoBERTa model, while position embeddings include both 1D and 2D layout positions. Segment-level layout positions are used, where words in a segment share the same 2D position, enhancing semantic coherence.
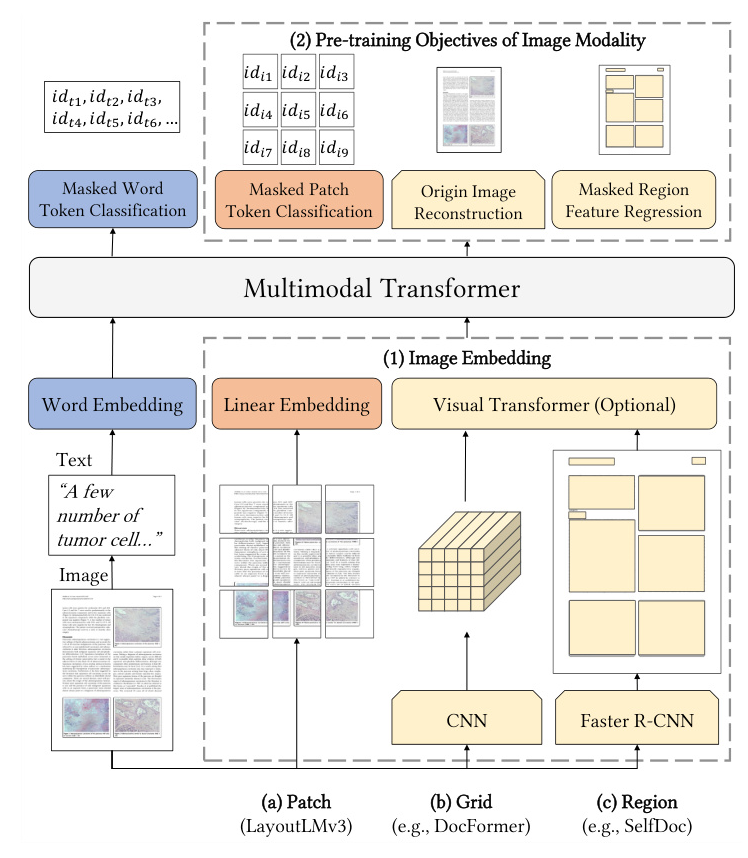
Image Embedding
Unlike previous models that rely on CNNs or object detectors for image embeddings, LayoutLMv3 uses linear projection features of image patches. This approach reduces computational bottlenecks and eliminates the need for region supervision. Document images are resized, split into uniform patches, and linearly projected into vectors, which are then fed into the Transformer.

Pre-training Objectives
LayoutLMv3 is pre-trained using three main objectives: Masked Language Modeling (MLM), Masked Image Modeling (MIM), and Word-Patch Alignment (WPA).
Masked Language Modeling (MLM)
nspired by BERT, MLM involves masking 30% of text tokens and predicting the original tokens based on contextual representations. This objective helps the model learn the correspondence between layout information and text/image context.
Masked Image Modeling (MIM)
MIM encourages the model to interpret visual content by masking 40% of image tokens and reconstructing them based on surrounding text and image tokens. This objective helps the model learn high-level layout structures rather than noisy details.
Word-Patch Alignment (WPA)
WPA aims to predict whether the corresponding image patches of a text word are masked, facilitating fine-grained alignment between text and image modalities. This objective enhances cross-modal representation learning.

Experiments
Model Configurations
LayoutLMv3 is evaluated in both base and large model sizes. The base model uses a 12-layer Transformer encoder, while the large model uses a 24-layer encoder. Text sequences are tokenized with Byte-Pair Encoding (BPE), and image patches are linearly projected. Distributed and mixed-precision training techniques are employed to optimize memory usage and training speed.
Pre-training
LayoutLMv3 is pre-trained on the IIT-CDIP dataset, containing approximately 11 million document images. The model is initialized from pre-trained RoBERTa weights, and the image tokenizer is initialized from a pre-trained DiT model. The pre-training process involves the Adam optimizer with specific learning rates and batch sizes for the base and large models.
Fine-tuning on Multimodal Tasks
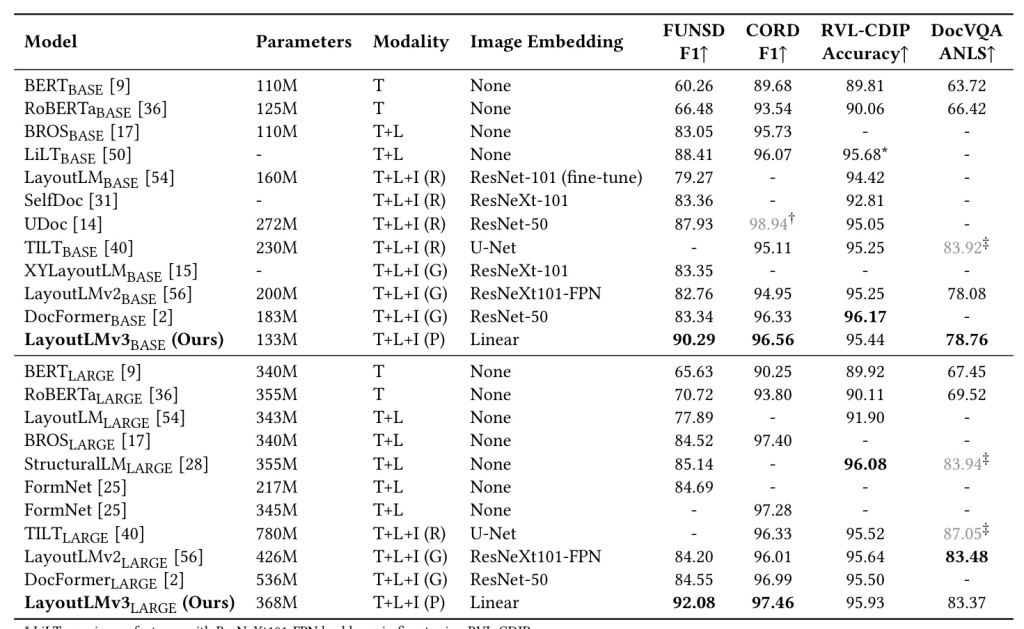
LayoutLMv3 is fine-tuned on various multimodal tasks, including form and receipt understanding, document image classification, and document visual question answering. The model achieves state-of-the-art performance across these benchmarks, demonstrating its effectiveness for both text-centric and image-centric tasks.

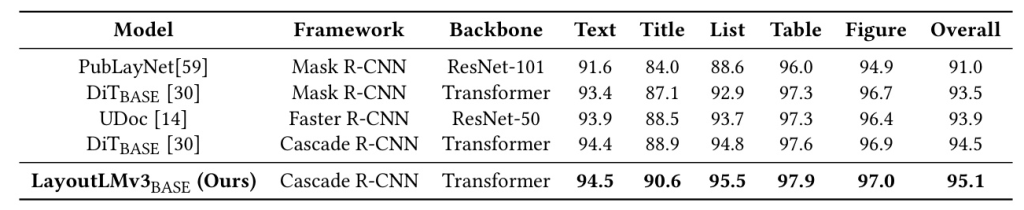
Fine-tuning on a Vision Task
To showcase the generality of LayoutLMv3, it is fine-tuned on a document layout analysis task using the PubLayNet dataset. The model integrates with the Cascade R-CNN detector and achieves superior performance compared to other models, highlighting its capability in vision tasks.

Ablation Study
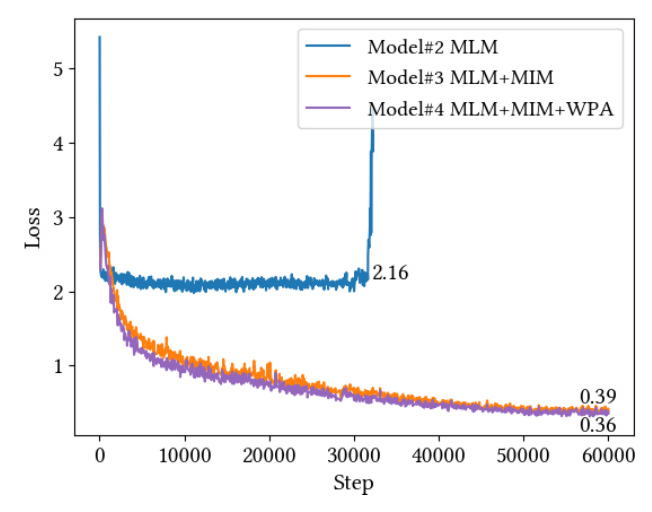
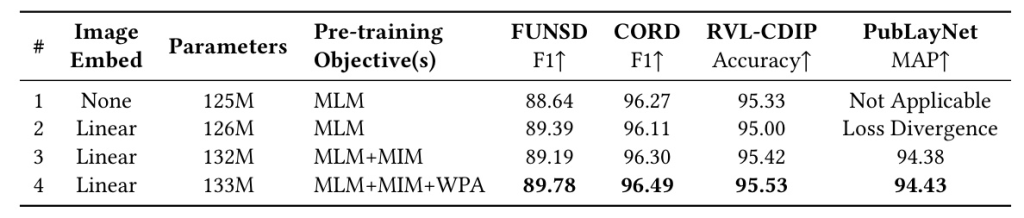
An ablation study is conducted to evaluate the impact of different image embeddings and pre-training objectives. The study reveals that incorporating linear image embeddings and the MIM objective significantly improves performance on both text-centric and image-centric tasks. The WPA objective further enhances cross-modal representation learning.

Related Work
LayoutLMv3 builds on previous advancements in multimodal pre-training techniques, such as LayoutLM, DocFormer, and ViLT. It distinguishes itself by using linear image embeddings without relying on CNNs, reducing computational complexity and improving efficiency.
Conclusion and Future Work
LayoutLMv3 represents a significant advancement in pre-training multimodal Transformers for Document AI. Its unified architecture and pre-training objectives enable superior performance across various tasks. Future research will focus on scaling up pre-trained models and exploring few-shot and zero-shot learning capabilities to address real-world business scenarios.

Appendix: LayoutLMv3 in Chinese
To demonstrate the versatility of LayoutLMv3, a Chinese version of the model is pre-trained and fine-tuned on the EPHOIE dataset for visual information extraction. The model achieves state-of-the-art performance, highlighting its effectiveness across different languages.


Datasets:
Related Papers
- Multimodal Masked Autoencoders Learn Transferable Representations
- UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
- Seeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
- UNITER: UNiversal Image-TExt Representation Learning
- Masked Vision and Language Modeling for Multi-modal Representation Learning
- SimVTP: Simple Video Text Pre-training with Masked Autoencoders
- MLIM: Vision-and-Language Model Pre-training with Masked Language and Image Modeling
- StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
- CLIPPO: Image-and-Language Understanding from Pixels Only
Related Videos



