





Authors:
Shuang Luo、Yinchuan Li、Shunyu Liu、Xu Zhang、Yunfeng Shao、Chao Wu
Paper:
https://arxiv.org/abs/2408.06920
Introduction
Generative Flow Networks (GFlowNets) have emerged as a promising alternative to traditional reinforcement learning (RL) for exploratory control tasks. Unlike RL, which focuses on maximizing cumulative rewards for a single optimal sequence, GFlowNets generate diverse trajectories with probabilities proportional to their rewards. However, the individual-flow matching constraint in GFlowNets limits their application in multi-agent systems, particularly in continuous joint-control problems. This paper introduces a novel method called Multi-Agent generative Continuous Flow Networks (MACFN) to address this limitation.
Related Work
Generative Flow Networks
GFlowNets aim to generate diverse candidates in an active learning fashion, sampling trajectories from a distribution proportional to their rewards. Recent advancements have extended GFlowNets to continuous structures, but they remain limited to single-agent tasks. Efforts to adapt GFlowNets for multi-agent systems (MAS) have been constrained to discrete spaces.
Cooperative Multi-Agent Reinforcement Learning
Cooperative Multi-Agent Reinforcement Learning (MARL) enables autonomous agents to tackle various tasks collaboratively. However, learning joint policies for MAS remains challenging due to computation complexity, communication constraints, and non-stationarity. Centralized Training with Decentralized Execution (CTDE) has emerged as a hybrid paradigm to address these challenges.
Preliminaries
Dec-POMDP
A fully cooperative multi-agent sequential decision-making problem can be modeled as a Decentralized Partially Observable Markov Decision Process (Dec-POMDP). This framework defines the global state space, joint action space, partial observations, state transition function, and global reward function shared by all agents.
GFlowNets
GFlowNets construct the set of complete trajectories as a Directed Acyclic Graph (DAG). The flow matching conditions ensure that the flow incoming to a state matches the outgoing flow. For continuous control tasks, the state flow is calculated as the integral of all trajectory flows passing through the state.
Methodology
MACFN: Theoretical Formulation
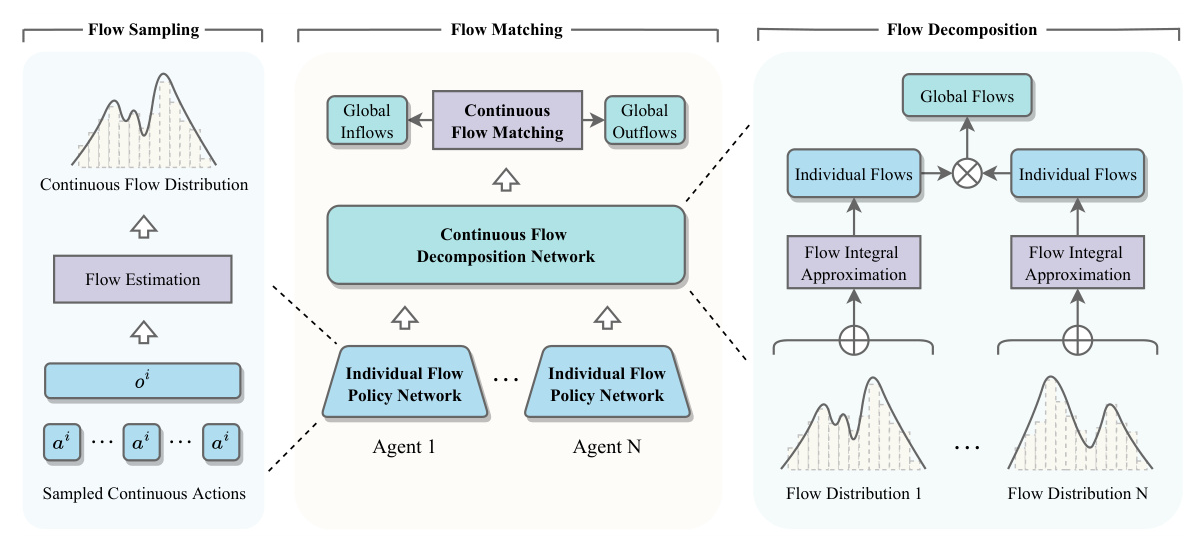
MACFN enables multiple agents to learn individual-flow-based policies in a centralized global-flow-based matching manner. The joint edge flow is decomposed into individual edge flows for each agent. The consistency between individual and joint policies is maintained, ensuring that agents can make decisions based solely on local observations.
Flow Matching and Decomposition
The joint continuous flow matching condition ensures the existence of a distinct Markovian flow. The continuous flow-matching loss function is used to train the flow network. A sampling-based approach approximates the integrals over inflows and outflows in continuous flow matching.
Training Framework
The training framework adopts the CTDE paradigm. Each agent learns its individual-flow-based policy by optimizing the global-flow-based matching loss. The framework consists of three steps: flow sampling, flow decomposition, and flow matching.


Experiments
Environments
Experiments were conducted on several multi-agent cooperative environments with sparse rewards, including the Multi-Agent Particle Environment (MPE) and Multi-Agent MuJoCo (MAMuJoCo). These environments test the effectiveness of MACFN in various scenarios, such as Robot-Navigation-Sparse, Food-Collection-Sparse, and Predator-Prey-Sparse.

Settings
MACFN was compared with various baseline methods, including Independent DDPG (IDDPG), MADDPG, COVDN, COMIX, and FACMAC. The experiments were run using the Python MARL framework (PyMARL). The performance metrics included average test return and the number of distinctive trajectories.
Results
MACFN demonstrated superior performance in terms of average test return and exploration capability compared to the baselines. The results showed that MACFN could efficiently search for valuable trajectories and discover diverse cooperation patterns.

Conclusion
This work introduces MACFN, a novel method for multi-agent continuous control using GFlowNets. MACFN enables decentralized individual-flow-based policies through centralized global-flow-based matching. The experimental results demonstrate that MACFN significantly enhances exploration capability and outperforms state-of-the-art MARL algorithms. Future work will focus on improving MACFN under dynamic multi-agent settings and considering more complex transition functions.
Acknowledgments
This work was supported by various national and provincial research projects and foundations. The authors acknowledge the support and contributions from their respective institutions and funding bodies.
This blog post provides a detailed overview of the paper “Multi-Agent Continuous Control with Generative Flow Networks,” highlighting the key concepts, methodologies, and experimental results. For more information, refer to the published version of the paper available at DOI link.








