





Authors:
Angus Nicolson、Yarin Gal、J. Alison Noble
Paper:
https://arxiv.org/abs/2408.08652
TextCAVs: Debugging Vision Models Using Text
Introduction
Deep learning models are increasingly used in healthcare, where errors can have severe consequences. Interpretability, the ability to explain a model in human-understandable terms, is crucial for creating safer models. Concept-based interpretability methods, which use high-level human-interpretable concepts, are particularly useful. Traditional methods require labeled data for these concepts, which is expensive in medical domains. This paper introduces TextCAVs, a novel method that uses vision-language models like CLIP to create Concept Activation Vectors (CAVs) using text descriptions instead of image examples. This approach reduces the cost and allows for interactive model debugging.
Related Work
Kim et al. introduced Testing with Concept Activation Vectors (TCAVs), which use probe datasets of concept examples to create CAVs. These CAVs are then compared with model gradients to measure sensitivity to a concept. Various methods have been developed to automate finding concepts, but they often lack inherent meaning and require visual presence in the dataset. TextCAVs, on the other hand, use text descriptions, providing inherent meaning without needing labeled data for each concept.
CLIP models have shown strong performance in vision-language tasks, allowing for comparisons between text and images and enabling zero-shot classification. Some adaptations have been made for the biomedical space, such as BioViL and BiomedCLIP. TextCAVs leverage these models but perform inference using the target model, without restricting its architecture or training method.
TextCAVs
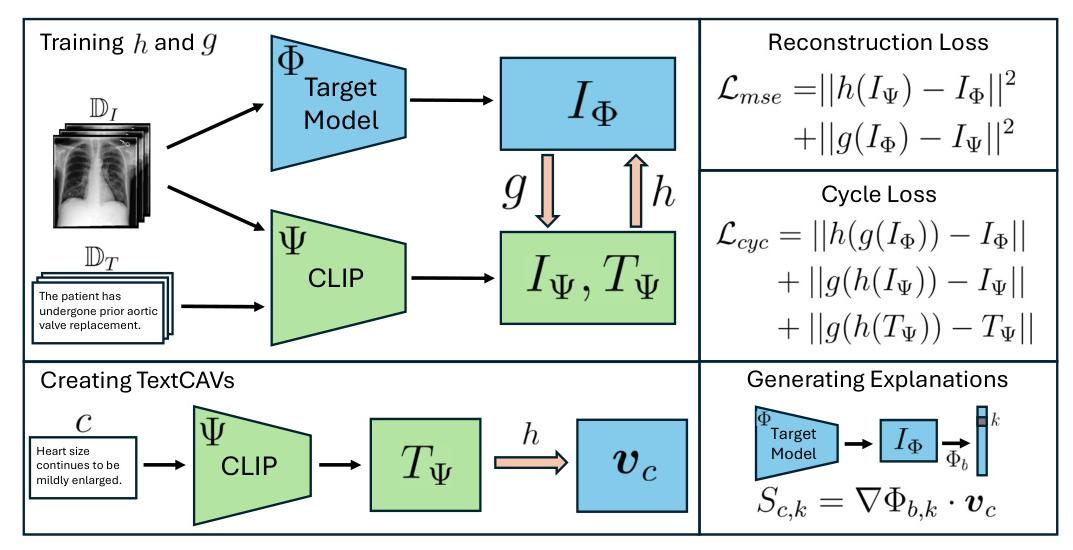
TextCAVs involve training two linear layers, ( h ) and ( g ), to convert features between a target model ( \Phi ) and a CLIP-like vision-language model ( \Psi ). The loss function includes reconstruction loss and cycle loss to ensure feature consistency. Once trained, ( h ) is used to obtain a concept vector in the target model’s activation space. The model’s sensitivity to a concept is measured using the directional derivative.
Training Details
For training, features are extracted from an image dataset ( D_I ) and a text dataset ( D_T ). The reconstruction loss is the mean squared error between the image features and converted features. The cycle loss ensures that features remain consistent when converted back to their original space.
Generating Explanations
Once ( h ) is trained, TextCAVs can generate explanations using only text descriptions. The model’s sensitivity to a concept for a specific class is calculated using the directional derivative. This allows for fast feedback and interactive debugging, enabling users to test new hypotheses quickly.


Experiments
ImageNet
TextCAVs achieved 3rd place at the Secure and Trustworthy Machine Learning Conference (SaTML) interpretability competition, detecting trojans in vision models trained on ImageNet. The method was used to identify all four secret trojans, demonstrating its potential for interactive debugging. For this experiment, a ResNet-50 model trained on ImageNet was used.
Training Details
20% of the ImageNet training dataset was used to train ( h ) and ( g ) for 20 epochs. The target model was a ResNet-50 with default weights from the TorchVision package in PyTorch. The vision-language model was a pretrained ViT-B/16 CLIP model.
Concepts
A large language model (LLM) was used to obtain a list of concepts. Prompts were used to generate concepts related to each ImageNet class. Basic filtering was applied to remove plurals, articles, and multi-word concepts. Similar concepts were further filtered using text embeddings from ( \Psi ).
Results
The top-10 concepts for a selection of ImageNet classes were shown to be relevant, indicating that TextCAVs can produce reliable explanations.

MIMIC-CXR
TextCAVs were also tested on the MIMIC-CXR dataset to produce meaningful explanations for a model trained on chest X-rays. Additionally, the method was used to discover bias in a model trained on a biased version of the dataset.
Training Details
Both ( h ) and ( g ), and the target model ( \Phi ), were trained using the MIMIC-CXR training set. The target model was a ResNet-50 pretrained on ImageNet and fine-tuned for 5-way multi-label classification of chest X-rays. The BiomedCLIP model was used as ( \Psi ).
Concepts
Clinical reports associated with the MIMIC-CXR dataset were used as a source of concepts. Sentences from the “FINDINGS” and “IMPRESSION” sections of the reports were extracted to obtain a variety of concepts.
Biased Data
A dataset bias was induced by removing participants with a positive label for Atelectasis and a negative label for Support Devices. This created a biased training set where all participants with Atelectasis also had a Support Device.
Metrics
The top-50 sentences for each class were labeled for relevance, and a concept relevance score (CRS) was calculated. This score represents the proportion of concepts related to the class.
Results
Two models were compared: one trained on the standard MIMIC-CXR dataset and the other on the biased version. The standard model achieved a mean AUC of 0.83, while the biased model achieved 0.81. The biased model showed higher performance on a biased test set, indicating the presence of bias.


The top-5 sentences for the standard model were relevant to their respective classes, while the biased model’s top-5 sentences for Atelectasis referred to Support Devices, indicating bias. The CRS values further confirmed the presence of bias.

Conclusion
TextCAVs is an interpretability method that uses text descriptions to measure a model’s sensitivity to concepts. It produces reasonable explanations for models trained on both natural images and chest X-rays. The method was shown to be effective in debugging models, particularly in detecting dataset bias. Future work will focus on exploring the sources of noise in the explanations and studying interactive debugging.

Code:
https://github.com/angusnicolson/textcavs


