





Authors:
Kyle Moore、Jesse Roberts、Thao Pham、Douglas Fisher
Paper:
https://arxiv.org/abs/2408.08651
Introduction
In the realm of cognitive reasoning, Kahneman’s “Thinking Fast and Slow” introduces two distinct modes of thinking: System 1 (heuristic) and System 2 (deliberative). This dichotomy is useful for understanding the relationship between behavior and computation, especially in the context of Large Language Models (LLMs). LLMs can exhibit both System 1 and System 2 behaviors, with Counterfactual (CF) prompting typically used to achieve the former. This study investigates the impact of biases on answer choice preferences in the Massive Multi-Task Language Understanding (MMLU) task and introduces novel methods to mitigate these biases.
Background
MMLU
The Massive Multitask Language Understanding (MMLU) task is a multiple-choice question answering (MCQA) benchmark with 14,042 questions across 57 subjects. Each question has four answer choices, with one designated as correct. MMLU is used to measure a model’s natural language understanding and factual knowledge.
Cloze Prompting
Cloze testing is a prompting strategy where the probability of each option is measured given a shared context. The chosen option is the one with the highest probability. This method is used to evaluate tasks where LLMs must select from a set of options.
Counterfactual Prompting
Counterfactual (CF) prompting uses a separate query for each option and a shared canary completion for evaluation. This method aims to mitigate base rate probability (BRP) effects while maintaining task semantics. However, prior work has shown that CF evaluation may degrade performance on some tasks.
Chain-of-Thought
Chain-of-Thought (CoT) is a prompting strategy where the language model generates freely from a task definition before providing a final answer. It approximates System-2-like processing and has been shown to improve model performance on various benchmarks. However, CoT may not always traverse the most useful path in semantic space, leading to biases.
Base-Rate Probability Effects
LLMs predict the most likely next token given all tokens in the preceding context. Tokens also have an intrinsic probability called the base-rate probability (BRP). Differences in BRP between tokens can affect models’ overt behavior and performance on downstream tasks.
LLama-3.1 Token Base-Rate Probability
BRPs for the LLaMa 3.1 model were obtained by evaluating the probability of each answer choice in the context of an MCQA task. The results indicate a BRP preference ordering of A ⪰D ≻B ⪰C. Even small relative BRP differences are highly predictive of overt behavior.


Counterfactual CoT
CF prompting weakly mitigates BRP effects on overt behavior but fails to eliminate them entirely. We hypothesize that a more deliberative, System-2-like evaluation will eliminate the BRP effect. To evaluate this, we propose a novel adaptation of CF methods to include CoT reasoning.
Methods: CF+CoT
We evaluated the LLaMa 3.1 8B model for its susceptibility to BRP effects under CF+CoT reasoning using the MMLU benchmark. The model was presented with the question and answer choices using a conversational prompt template. CoT reasoning was elicited by using the sentence “Let’s think step by step.”
Results: CF+CoT
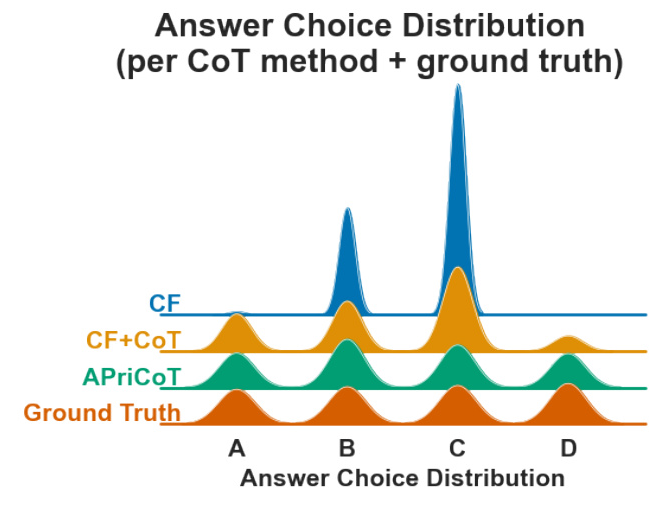
The answer choice distribution for CF+CoT shows a strong preference for one answer choice over others, magnifying the BRP effect. This suggests that CF+CoT answers are more frequently impacted by the prior expectation of the model, likely due to a confirmation bias-like effect.

Discussion: CF+CoT
CoT facilitates traversal of a Bayes net of related concepts, but this can lead to confirmation bias if the direction of traversal is biased. APriCoT improves upon this by agnostically providing directions of traversal and requiring the model to evaluate the coherence of the paths.

Counterfactual APriCoT
To address the shortcomings of CF+CoT, we propose Agnostically Primed Chain-of-Thought (APriCoT). APriCoT differs from CF+CoT by eliciting CoT in combination with one of the candidate answer choices and evaluating each answer choice independently.
Methods: APriCoT
APriCoT was evaluated on the same MMLU question set as CF+CoT. The model was allowed to generate up to 100 tokens of CoT reasoning, and the probability of the canary token “Yes” was evaluated given the contexts.
Results: APriCoT
APriCoT shows a well-balanced answer distribution that closely matches the ground truth answers. It significantly reduces BRP effects and improves model performance on the MMLU task.

Conclusion
This study demonstrates that mitigating bias in LLMs requires a System-2-like process. While CF+CoT exacerbates BRP effects, APriCoT effectively reduces these biases and improves overall accuracy. APriCoT offers a practical solution for developing more robust and fair language models.
Future Work
Future work should investigate whether APriCoT is appropriate for more complex reasoning tasks and whether it yields similar improvements for other evaluation techniques. Additionally, methods that do not require pre-defined options, such as dynamic option generation, should be explored.
Limitations
All experiments were performed exclusively on the LLaMa 3.1 model. Due to resource constraints, only the 8 billion parameter model was evaluated. Future work should investigate whether the results transfer across model families or persist with increased model size.
Technical Details
All experiments were performed with 100 hours on a Google Colab NVIDIA A100 GPU. All code and data relevant to this work are available open source at [GITHUB-LINK-REDACTED] to accommodate replication.


