





Authors:
Paper:
https://arxiv.org/abs/2408.08632
Introduction
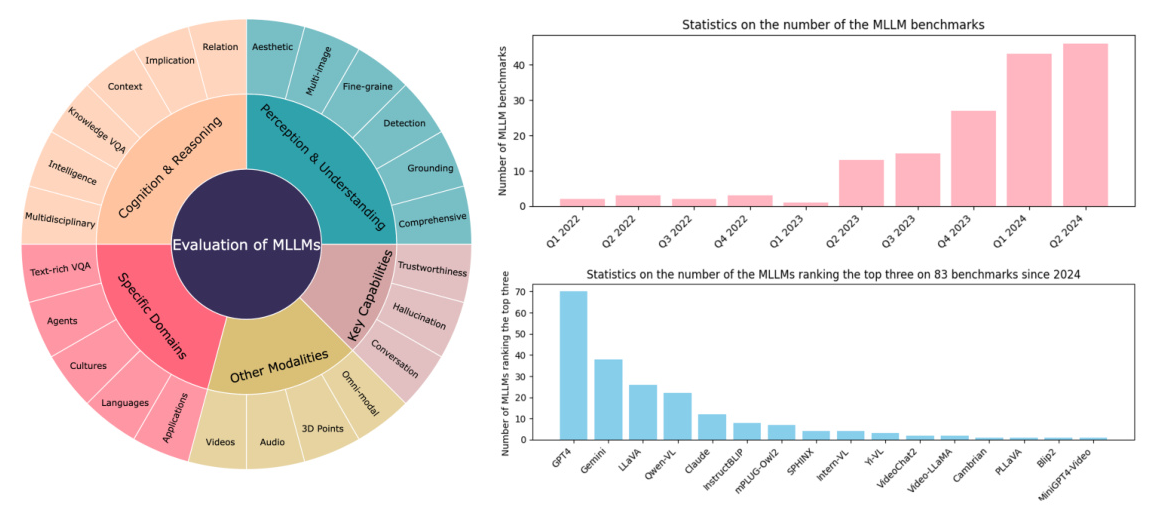
Multimodal Large Language Models (MLLMs) have become a focal point in both academia and industry due to their exceptional performance in various applications such as visual question answering, visual perception, understanding, and reasoning. This paper provides a comprehensive review of 180 benchmarks and evaluations for MLLMs, focusing on five key areas: perception and understanding, cognition and reasoning, specific domains, key capabilities, and other modalities. The paper also discusses the limitations of current evaluation methods and explores promising future directions.
Preliminaries
The paper compares several common MLLMs, including GPT-4, Gemini, LLaVA, Qwen-VL, Claude, InstructBLIP, mPLUG-Owl2, SPHINX, Intern-VL, Yi-VL, VideoChat2, Video-LLaMA, Cambrian-1, PLLaVA, Blip2, and MiniGPT4-Video. The standard MLLM framework consists of three main modules: a visual encoder, a pre-trained language model, and a visual-language projector. The architecture and training process are illustrated in Figure 3.
MLLM Architecture
- Vision Encoder: Compresses the original image into compact patch features.
- Vision-Language Projector: Maps visual patch embeddings into the text feature space.
- Large Language Model: Manages multimodal signals and performs reasoning.
MLLM Training
- Pre-training: Aligns different modalities within the embedding space using large-scale text-paired data.
- Instruction-tuning: Fine-tunes the models on specific tasks using task-specific instructions.
Perception and Understanding
This section evaluates the fundamental abilities of MLLMs in visual information processing, including object identification, scene context understanding, and response to image content questions.
Comprehensive Evaluation
Several benchmarks like LLaVA-Bench, OwlEval, MME, MMBench, Open-VQA, TouchStone, and SEED-Bench have been proposed to evaluate MLLMs comprehensively.
Fine-grained Perception
- Visual Grounding and Object Detection: Benchmarks like Flickr30k Entities, Visual7W, CODE, and V*Bench focus on detailed grounding and contextual object detection.
- Fine-grained Identification and Recognition: Benchmarks like GVT-bench, MagnifierBench, MMVP, CV-Bench, P2GB, and VisualCoT evaluate detailed visual perception.
- Nuanced Vision-language Alignment: Benchmarks like Winoground, VALSE, VLChecklist, ARO, Eqben, and SPEC assess the alignment of visual and textual information.
Image Understanding
- Multi-image Understanding: Benchmarks like Mementos, MileBench, MuirBench, MMIU, and COMPBENCH evaluate the understanding of relationships among multiple images.
- Implication Understanding: Benchmarks like II-Bench, ImplicitAVE, and FABA-Bench assess higher-order perceptual abilities and emotional perception.
- Image Quality and Aesthetics Perception: Benchmarks like Q-Bench, Q-Bench+, AesBench, UNIAA, and DesignProbe evaluate image quality and aesthetics.
Cognition and Reasoning
This section focuses on the advanced processing and complex inference capabilities of MLLMs.
General Reasoning
- Visual Relation: Benchmarks like VSR, What’s Up, CRPE, MMRel, GSR-BENCH, and SpatialRGBT-Bench evaluate the understanding of spatial relationships.
- Context-related Reasoning: Benchmarks like CODIS, CFMM, and VL-ICL Bench assess the use of contextual knowledge.
- Vision-Indispensable Reasoning: Benchmarks like VQAv2, CLEVR, GQA, and MMStar evaluate the reliance on visual data.
Knowledge-based Reasoning
- Knowledge-based Visual Question Answering: Benchmarks like KB-VQA, FVQA, OK-VQA, A-OKVQA, and SOK-Bench evaluate the use of external knowledge.
- Knowledge Editing: Benchmarks like MMEdit, MIKE, VLKEB, and MC-MKE evaluate the accuracy and consistency in updating knowledge content.
Intelligence & Cognition
- Intelligent Question Answering: Benchmarks like RAVEN, MARVEL, VCog-Bench, and M3GIA evaluate abstract visual reasoning.
- Mathematical Question Answering: Benchmarks like Geometry3K, MathVista, Math-V, MathVerse, NPHardEval4V, and MATHCHECK-GEO evaluate mathematical reasoning.
- Multidisciplinary Question Answering: Benchmarks like ScienceQA, M3Exam, SceMQA, MMMU, CMMMU, CMMU, and MULTI evaluate the integration of diverse knowledge.
Specific Domains
This section evaluates MLLMs’ capabilities in specific tasks and applications.
Text-rich VQA
- Text-oriented Question Answering: Benchmarks like TextVQA, TextCaps, OCRBench, P2GB, and SEED-Bench-2-Plus evaluate text recognition and scene text-centric visual question answering.
- Document-oriented Question Answering: Benchmarks like InfographicVQA, SPDocVQA, MP-DocVQA, DUDE, and MM-NIAH evaluate document understanding.
- Chart-oriented Question Answering: Benchmarks like ChartQA, SciGraphQA, MMC, ChartBench, ChartX, CharXiv, and CHOPINLLM evaluate chart understanding.
- Html-oriented Question Answering: Benchmarks like Web2Code, VisualWebBench, and Plot2Code evaluate web page understanding.
Decision-making Agents
- Embodied Decision-making: Benchmarks like OpenEQA, PCA-EVAL, EgoPlan-Bench, and VisualAgentBench evaluate decision-making in complex environments.
- Mobile Agency: Benchmarks like Mobile-Eval, Ferret-UI, and CRAB evaluate mobile app navigation and task completion.
Diverse Cultures and Languages
Benchmarks like CMMU, CMMMU, MULTI, Henna, LaVy-Bench, MTVQA, and CVQA evaluate MLLMs’ understanding of diverse languages and cultures.
Other Applications
- Geography and Remote Sensing: Benchmarks like LHRS-Bench and ChartingNewTerritories evaluate geographic information extraction.
- Medicine: Benchmarks like Asclepius, M3D-Bench, and GMAI-MMBench evaluate medical knowledge integration.
- Industry: Benchmarks like DesignQA and MMRo evaluate industrial design and manufacturing applications.
- Society: Benchmarks like VizWiz, MM-SOC, and TransportationGames evaluate social needs and transportation-related tasks.
- Autonomous Driving: Benchmarks like NuScenes-QA and DriveLM-Data evaluate autonomous driving scenarios.
Key Capabilities
This section evaluates dialogue capabilities, hallucination, and trustworthiness.
Conversation Abilities
- Long-context Capabilities: Benchmarks like MileBench, MMNeedle, and MLVU evaluate long-context understanding.
- Instruction Adherence: Benchmarks like Demon, VisIT-Bench, CoIN, and MIA-Bench evaluate instruction-following capabilities.
Hallucination
Benchmarks like CHAIR, POPE, GAVIE, M-HalDetect, MMHAL-BENCH, MHaluBench, MRHalBench, VideoHallucer, HaELM, AMBER, VHTest, and HallusionBench evaluate hallucination in MLLMs.
Trustworthiness
- Robustness: Benchmarks like BenchLMM, MMR, MAD-Bench, MM-SAP, VQAv2-IDK, and MM-SPUBENCH evaluate robustness.
- Safety: Benchmarks like MM-SafetyBench, JailBreakV, MMUBench, SHIELD, MultiTrust, and RTVLM evaluate safety and trustworthiness.
Other Modalities
This section evaluates MLLMs’ capabilities in handling video, audio, and 3D point clouds.
Videos
- Temporal Perception: Benchmarks like TimeIT, MVBench, Perception Test, VilMA, VITATECS, TempCompass, OsCaR, and ADLMCQ evaluate temporal understanding.
- Long Video Understanding: Benchmarks like Egoschema, MovieChat-1k, MLVU, and Event-Bench evaluate long-video understanding.
- Comprehensive Evaluation: Benchmarks like Video-Bench, AutoEval-Video, Video-MME, MMWorld, and WorldNet evaluate overall video understanding.
Audio
Benchmarks like Dynamic-SUPERB, MuChoMusic, and AIR-Bench evaluate audio understanding.
3D Scenes
Benchmarks like ScanQA, LAMM, ScanReason, SpatialRGPT, and M3DBench evaluate 3D scene understanding.
Omnimodal
Benchmarks like MusicAVQA, AVQA, MCUB, and MMT-Bench evaluate the ability to handle multiple modalities simultaneously.
Conclusion
Evaluation is crucial for the advancement of AGI models, ensuring they meet desired standards of accuracy, robustness, and fairness. This study provides a comprehensive overview of MLLM evaluations and benchmarks, categorizing them into perception and understanding, cognition and reasoning, specific domains, key capabilities, and other modalities. The aim is to enhance the understanding of MLLMs, elucidate their strengths and limitations, and provide insights into future progression.
For more details, please visit the GitHub repository: Evaluation-Multimodal-LLMs-Survey.






Code:
https://github.com/swordlidev/evaluation-multimodal-llms-survey
Datasets:
CLEVR、GQA、OK-VQA、TextVQA、ScienceQA、VizWiz、MMBench、MM-Vet、Flickr30K Entities、A-OKVQA、ChartQA、Visual7W、RAVEN、SEED-Bench、TextCaps、LLaVA-Bench、Winoground、MathVista、EQA、EgoSchema、VSR、MVBench、InfographicVQA、MUSIC-AVQA、Geometry3K、VALSE、Q-Bench、MMVP、M3Exam、MMStar、Video-MME、DUDE、MMNeedle、VisIT-Bench、BenchLMM、HallusionBench、MM-SafetyBench、AesBench、MP-DocVQA、SciGraphQA、NPHardEval4V、M3GIA、CharXiv、MULTI、VLKEB、CV-Bench


