





Authors:
Binbin Ding、Penghui Yang、Zeqing Ge、Shengjun Huang
Paper:
https://arxiv.org/abs/2408.08655
Introduction
Federated Learning (FL) is a distributed machine learning framework that allows multiple clients to collaboratively train models while preserving data privacy. However, this decentralized nature also opens up vulnerabilities, particularly to backdoor attacks. These attacks embed malicious behaviors into the model, which remain dormant under normal conditions but activate when specific triggers are present. This paper introduces a novel defense mechanism called Flipping Weight Updates of Low-Activation Input Neurons (FLAIN) to mitigate such backdoor attacks.
Related Work
Backdoor Attacks in FL
Backdoor attacks manipulate models to make specific predictions by embedding triggers within samples. These triggers can be numerical, semantic, or even imperceptible. Strategies like decomposing a global trigger into localized variants across multiple malicious clients enhance attack stealth.
Mid-Training Defenses in FL
Mid-training defenses aim to identify and filter out malicious updates by scrutinizing discrepancies among the submitted data. Algorithms like Krum, Trimmed Mean, and Bulyan focus on minimizing the influence of outliers. However, these methods struggle in non-IID data scenarios, where the variability in data distribution can amplify discrepancies among benign updates.
Post-Training Defenses in FL
Post-training defenses eliminate the need to identify update discrepancies across clients. Techniques like pruning low-activation neurons have shown effectiveness in mitigating backdoor attacks while preserving overall model performance. However, pruning can degrade model performance when backdoor and benign behaviors rely on the same neurons.
Problem Setup
Federated Learning
In a FL system with (N) clients, each client (k) has a local dataset (D_k). The server manages client participation in each training round, with the global training objective defined as:
[ w^* = \arg \min_w \sum_{k=1}^N \lambda_k f(w, D_k) ]
where (w^*) denotes the optimal global model parameters, and (\lambda_k) indicates the weight of the loss for client (k).


Threat Model
The server lacks access to local training data and processes, making it vulnerable to backdoor attacks. Malicious attackers can perform white-box attacks, having access to both the training data and model parameters of compromised clients. The backdoored model is engineered to predict a specific class for samples embedded with triggers.
Defense Model
Defender’s Capabilities
The server maintains a small auxiliary dataset to compute the activation inputs of the fully connected layer and evaluate performance variations in the model.
Defender’s Goals
The defender aims to reduce the model’s accuracy on trigger samples while maintaining its performance on clean data.
Methodology
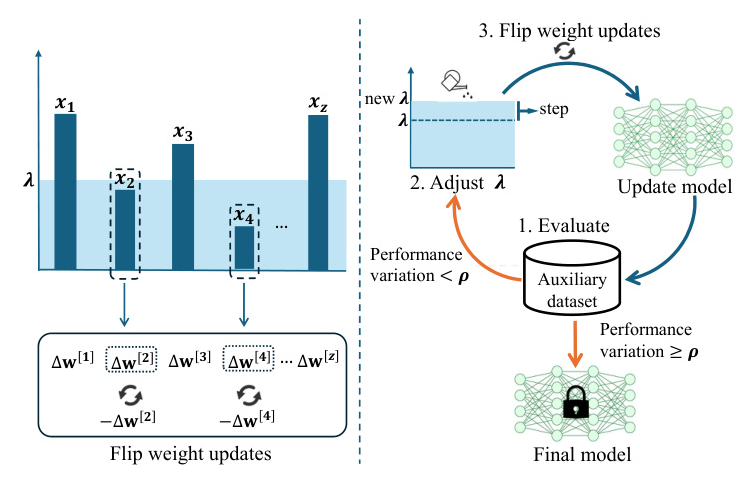
Flipping
FLAIN focuses on low-activation input neurons in the fully connected layer. Instead of pruning, FLAIN modifies these weights by flipping the updates obtained during global training. The process involves:
- Initializing the global model parameters and recording the initial weights.
- Completing global training and computing the weight updates.
- Using an auxiliary dataset to assess the model’s performance and retrieve the activation input vector.
- Setting a threshold (\lambda) and flipping the updates for neurons with activation inputs below (\lambda).

Adaptive Threshold
The threshold (\lambda) determines the tradeoff between clearing backdoors and maintaining performance on clean data. The server incrementally increases (\lambda) until the performance drop exceeds a predefined threshold (\rho).

Performance Evaluation
Experiment Setup
The experiments use the Adam optimizer with a learning rate of 0.001. Evaluation metrics include Attack Success Rate (ASR) and Natural Accuracy (ACC). Various datasets like MNIST, Fashion-MNIST, EMNIST, and CIFAR-10 are used.
Experiment Results
Attack Tasks under IID
FLAIN, Pruning, and RLR effectively reduce the ASR to near 0 for certain tasks on MNIST, FMNIST, and EMNIST, with negligible impact on ACC. However, their performances vary significantly on CIFAR-10.

Attack Tasks under non-IID
Under non-IID data distribution conditions, FLAIN and Pruning outperform RLR, maintaining higher ACC and achieving lower ASR in the evaluated tasks.

Different Pixel Backdoor Patterns
FLAIN maintains an average ACC reduction of only about 3.2% across various backdoor patterns, while keeping the ASR limited to approximately 0.8%.

Impact of Varying PDR
FLAIN effectively keeps the ASR at a minimal level while preserving the model’s performance on the main task across different PDR settings.

Diverse MCR Settings
FLAIN demonstrates stable defense performance across various MCR settings, with the maximum reduction in ACC not exceeding 2% and the ASR kept below 2%.




Conclusion
FLAIN is a backdoor defense method that flips the weight updates of low-activation input neurons. The adaptive threshold balances the tradeoff between eliminating backdoors and maintaining performance on clean data. FLAIN exhibits superior adaptability compared to direct pruning methods across a broader range of attack scenarios, including non-IID data distribution and high MCR settings. Future work will explore further enhancements to FLAIN, including its application in data-free scenarios and more complex models.


