





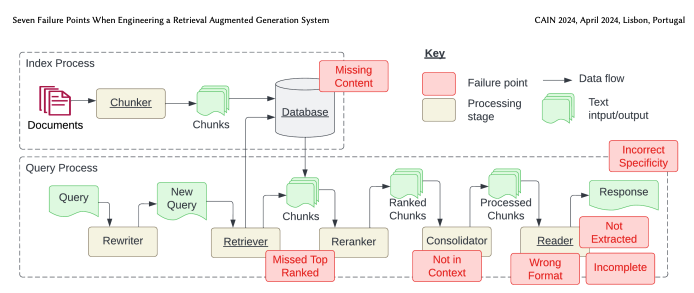
1. Abstract
The paper explores the complexities and challenges of engineering Retrieval Augmented Generation (RAG) systems, which leverage large language models (LLMs) to generate answers by retrieving relevant information from a data store. By presenting a mixed-methods approach that combines empirical experiments and case studies, the authors provide valuable insights into the limitations and failure points of RAG systems. They identify seven key failure points, including missing content, missed top-ranked documents, context limitations, extraction failures, format errors, incorrect specificity, and incomplete answers. The paper emphasizes the importance of continuous calibration, configuration, and testing for RAG systems, highlighting their evolving nature. Additionally, the authors propose research directions focusing on chunking and embeddings, RAG vs. fine-tuning, and testing and monitoring of RAG systems.
2. Paper Overview
a. Research Methodology
The paper employs a mixed-methods approach to investigate RAG systems comprehensively. The empirical experiment utilizes the BioASQ dataset, containing scientific documents, questions, and answers. The case studies involve the implementation of RAG systems in research, education, and biomedical domains, providing practical insights and lessons learned.
Innovations and Improvements:
- Empirical investigation into RAG system failures.
- Comprehensive catalog of failure points.
- Practical insights from real-world case studies.
- Guidance for developing robust RAG systems.
Problems Addressed: - Identifying and addressing the challenges and failure points in RAG systems.
- Providing practical insights and lessons learned from real-world case studies.
- Guiding the development of robust and reliable RAG systems.
b. Experiment Process
The empirical experiment involves indexing documents from the BioASQ dataset and using GPT-4 to generate answers for the questions. The generated answers are evaluated using OpenAI evals and manual inspection to identify patterns and failure points.
Dataset: - BioASQ dataset: Contains 4,017 scientific documents and 1,000 question-answer pairs.
Experiment Results and Significance:
The experiment reveals seven failure points in RAG systems, providing valuable insights into the limitations and challenges of these systems. The findings highlight the importance of careful design and continuous calibration to ensure the accuracy and reliability of RAG systems.
c. Paper Strengths - Empirical investigation into RAG system failures.
- Comprehensive catalog of failure points.
- Practical insights from real-world case studies.
- Guidance for developing robust RAG systems.
Potential Impact and Applications: - Improved understanding of RAG system limitations.
- Enhanced design and development of RAG systems.
- More accurate and reliable answers generated by RAG systems.
3. Summary
a. Contributions
- The paper presents a comprehensive analysis of the challenges and failure points in RAG systems, offering valuable insights for practitioners and researchers.
- The empirical experiment and case studies provide practical evidence and lessons learned, guiding the development of robust and reliable RAG systems.
- The identified failure points and research directions contribute to the advancement of the field and the realization of the full potential of RAG systems.
b. Key Innovations - Empirical investigation into RAG system failures.
- Comprehensive catalog of failure points.
- Practical insights from real-world case studies.
- Guidance for developing robust RAG systems.
c. Future Research Directions - Further investigation of chunking and embedding techniques for RAG systems.
- Comparison of RAG vs. fine-tuning approaches.
- Development of testing and monitoring frameworks for RAG systems.
- Exploration of new applications and use cases for RAG systems.


