





1. Full Summary
This paper introduces KOSMOS-2.5, a multimodal literate model designed for machine reading of text-intensive images. It addresses the limitations of existing models by incorporating two transcription tasks into a unified architecture: generating spatially-aware text blocks and producing structured markdown-formatted text. KOSMOS-2.5 leverages a shared Transformer architecture, task-specific prompts, and flexible text representations to achieve this.
The model is pre-trained on a diverse corpus of text-intensive images, including scanned documents, academic papers, PowerPoint slides, and web screenshots. This data is processed and filtered using various techniques to ensure quality and diversity. KOSMOS-2.5 demonstrates strong performance on text recognition and image-to-markdown generation tasks, outperforming existing models like Google Document OCR and Nougat.
2. Paper Skimming
a. Research Methodology
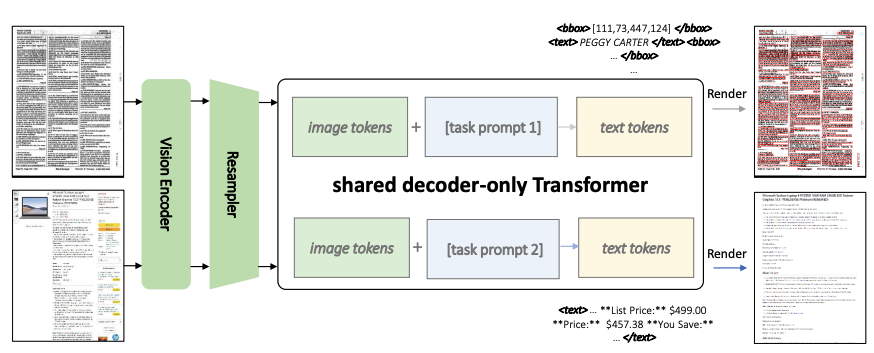
KOSMOS-2.5 utilizes a decoder-only architecture, consisting of a pre-trained vision encoder, a resampler module, and a language decoder. The vision encoder processes the input image, and the resampler module reduces the size of image embeddings. The language decoder generates the output text sequence based on the image and task-specific prompts.
The key innovation lies in incorporating two transcription tasks into a single model, enabling it to generate spatially-aware text blocks and structured markdown-formatted text. This eliminates the need for separate models and complex pipelines for different tasks.
b. Experiment Process
The model is pre-trained on a diverse corpus of text-intensive images, with text representations including text lines with bounding boxes and plain markdown texts. The data is processed and filtered to ensure quality and diversity.
The model is evaluated on text recognition and image-to-markdown generation tasks using benchmark datasets like FUNSD, SROIE, CORD, and README. It is compared with existing models like Google Document OCR and Nougat, demonstrating significant performance improvements.
c. Key Advantages
- Unified Architecture: Integrates two transcription tasks into a single model, simplifying the application interface and eliminating the need for complex pipelines.
- Flexible Text Representations: Handles both spatially-aware text blocks and markdown-formatted text, making it versatile for various document analysis tasks.
- Strong Performance: Outperforms existing models on text recognition and image-to-markdown generation tasks, demonstrating its effectiveness and robustness.
- Potential for Future Scaling: Sets the stage for future scaling of multimodal large language models.
3. Paper Conclusion
a. Contributions- Introduces a decoder-only architecture for text image understanding, incorporating two transcription tasks into a unified model.
- Simplifies the application interface by integrating generative multimodal language modeling, eliminating the need for complex pipelines.
- Demonstrates impressive multimodal literate capabilities, setting the stage for future scaling of multimodal large language models.
b. Key Innovations and Impact - Shifts the paradigm in text image understanding from encoder-only/encoder-decoder models to decoder-only models.
- Enables generative multimodal language modeling for text-intensive images, streamlining the application interface and simplifying downstream task training.
- Paves the way for the future scaling of multimodal large language models, opening up new possibilities for various real-world applications.
c. Future Research Directions- Fine-grained control of document elements’ positions using natural language instructions.
- Handling multi-page documents and long context windows.
- Augmenting the pre-training with textual data to transform it into a general-purpose MLLM.
- Exploring the potential of KOSMOS-2.5 for other text-intensive image understanding tasks, such as information extraction, layout detection and analysis, visual question answering, screenshot understanding, and UI automation.
Links to papers:https://arxiv.org/pdf/2309.11419


