





Abstract
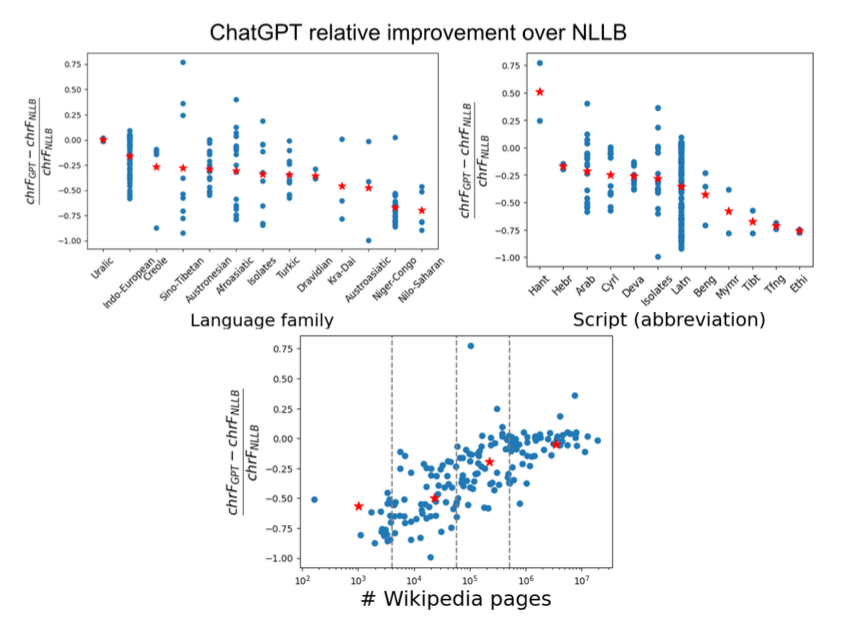
This paper investigates the capabilities of large language models (LLMs) like ChatGPT in performing machine translation (MT) tasks across a wide range of languages. Using the FLORES-200 benchmark, the authors compare the performance of ChatGPT with traditional MT models like NLLB, as well as commercial systems like Google Translate and the more advanced GPT-4. The results reveal that while ChatGPT demonstrates competitive performance for high-resource languages (HRLs), it consistently falls short for low-resource languages (LRLs), underperforming traditional MT models in 84.1% of the languages evaluated. The study also highlights the limited effectiveness of few-shot prompts for improving LLM MT performance and identifies key language features that correlate with LLM effectiveness, suggesting that LLMs are particularly challenged by LRLs and African languages. Additionally, the paper conducts a cost comparison across MT systems, demonstrating the economic considerations involved in using LLMs for MT.
Paper Flyer
a. Research Method
The authors employ a comprehensive experimental approach, leveraging the FLORES-200 benchmark dataset, which encompasses 204 language varieties. They evaluate ChatGPT’s MT performance using both zero-shot and five-shot prompts, and compare it with various baselines including NLLB, Google Translate, and GPT-4. The study focuses on English-to-X translation directions to ensure fair evaluation due to potential biases introduced by training on English data.
b. Experimental Process
The authors conducted experiments on the 1012 devtest sentences from the FLORES-200 dataset. They queried the OpenAI API for ChatGPT and GPT-4 translations, while obtaining NLLB and Google Translate results from publicly available sources. The evaluation metrics used were spBLEU and chrF2++, which are standard metrics for MT performance.
c. Major Strengths
- Wide Coverage: The study covers a diverse range of 204 languages, including 168 LRLs, providing valuable insights into LLM MT capabilities across different language families and resource levels.
- Comparative Analysis: By comparing ChatGPT with traditional MT models and commercial systems, the authors provide a comprehensive understanding of the strengths and weaknesses of LLMs in MT.
- Cost Analysis: The inclusion of cost comparisons across MT systems helps users make informed decisions based on their specific needs and budget constraints.
- Feature Analysis: The identification of key language features that influence LLM effectiveness provides valuable guidance for future research and development.
Paper Summary
a. Contributions
The paper makes several key contributions:
- Benchmarking LLM MT Performance: Provides a benchmark for LLM MT performance across a wide range of languages, filling a gap in existing research.
- Resource Limitations of LLMs: Demonstrates that LLMs struggle with LRLs, highlighting the need for specialized models for these languages.
- Effectiveness of Few-shot Prompts: Shows that few-shot prompts offer limited improvements, questioning their cost-effectiveness.
- Language Feature Analysis: Identifies key language features that influence LLM effectiveness, guiding future research and development.
- Cost Comparison: Provides cost estimates for different MT systems, aiding users in making informed decisions.
b. Innovations and Impact
The study’s main innovation lies in its comprehensive and comparative analysis of LLM MT performance across a wide range of languages. The findings have significant implications for the development of LLM-based MT systems, particularly for LRLs. The paper’s insights can guide future research on improving LLM performance for LRLs and developing more effective few-shot prompting techniques. Additionally, the cost analysis and feature analysis provide valuable information for users and researchers in making informed decisions about the use of LLMs for MT.
c. Future Research Directions - X-to-ENG Translation: Expanding the study to include X-to-ENG translation directions to assess potential biases introduced by training on English data.
- Human Evaluation: Conducting human evaluations of LLM MT outputs to assess factors like fluency, accuracy, and bias.
- Specialized Models: Investigating the development of smaller, specialized LLM models for LRLs and under-resourced languages.
- Prompt Engineering: Exploring more effective few-shot prompting techniques for LLM MT.
- Bias Analysis: Investigating the implicit biases present in LLMs and developing strategies for mitigating them.
View PDF:https://arxiv.org/pdf/2309.07423


