





Authors:
Jintao Cheng、Xingming Chen、Jinxin Liang、Xiaoyu Tang、Xieyuanli Chen、Dachuan Li
Paper:
https://arxiv.org/abs/2408.10602
Introduction
The accurate identification of moving objects in 3D point cloud data is a critical task for autonomous driving and robotics. This task, known as Moving Object Segmentation (MOS), involves distinguishing moving objects from static entities in the environment. Traditional methods for MOS can be broadly classified into 3D voxel-based and 2D projection-based approaches. However, these methods face significant challenges, such as high computational demands and information loss during 3D-to-2D projection. To address these issues, the paper proposes a novel multi-view MOS model (MV-MOS) that fuses motion-semantic features from different 2D representations of point clouds.
Related Work
Non-Learning-Based Methods
Non-learning-based methods for MOS, such as occupancy map methods and visibility-based theories, do not require complex data preprocessing or long training times. However, their segmentation accuracy is generally lower compared to deep learning-based methods.
Learning-Based Methods
State-of-the-art learning-based methods include:
– Cylinder3D: Uses cylindrical voxelization and sparse 3D convolution.
– InsMOS and 4DMOS: Introduce time series into 3D space and use 4D convolution.
– LMNet: Uses 2D projection in the range view to construct residual maps.
– MotionSeg3D and MF-MOS: Built upon 2D representations and incorporate semantic branches.
– MotionBEV: Uses the BEV perspective for 2D projection.
These methods, while effective, still face challenges such as high computational burden and information loss in single-view 2D representations.
Research Methodology
Data Preprocessing
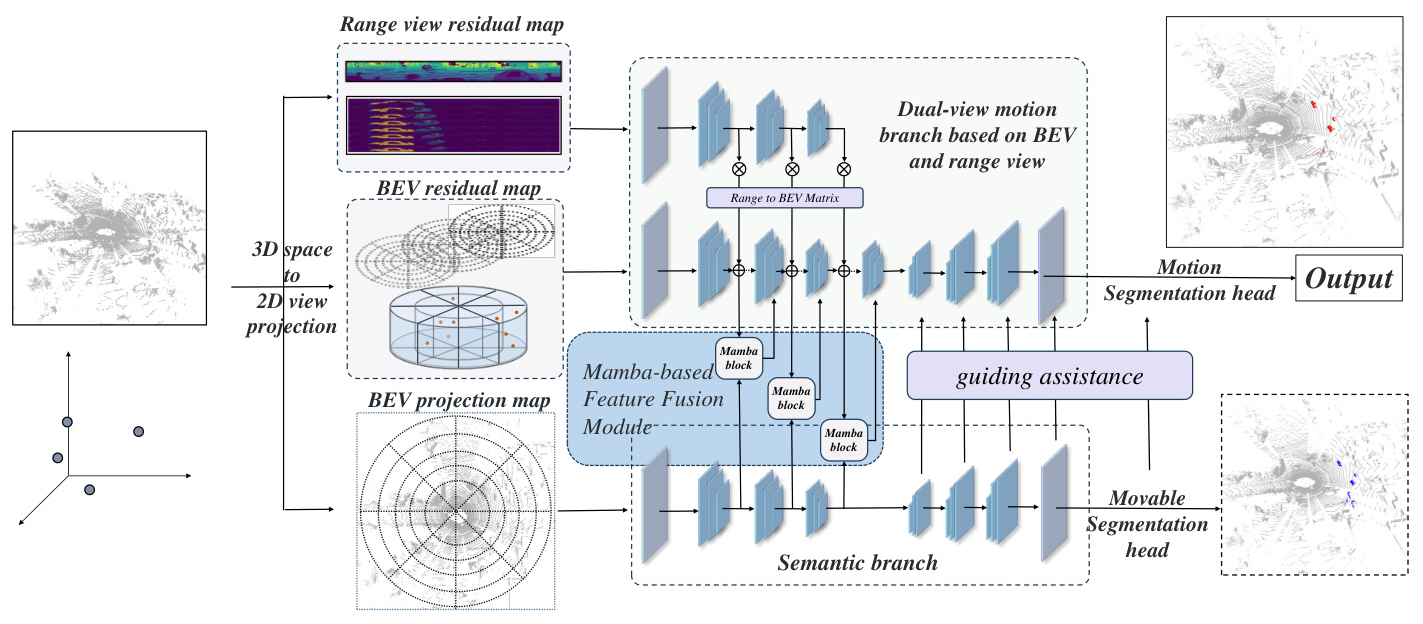
The original LiDAR point cloud data is transformed into range view and BEV presentations to derive the projected mappings. The range view and BEV residual maps are constructed using specific formulas to capture motion information from different perspectives.
Network Structure
The proposed MV-MOS model features a dual-view and multi-branch structure:
1. Motion Branch: Combines motion features from BEV and range view representations.
2. Semantic Branch: Provides supplementary semantic features and guides the motion branch.
3. Mamba-Based Feature Fusion Module: Fuses semantic and motion features to generate synthesized features for accurate segmentation.


Experimental Design
Experiment Setup
The MV-MOS model is trained and evaluated on the SemanticKITTI dataset, which includes semantic labels for various objects in real-world driving scenarios. The experiments are conducted using NVIDIA RTX 4090 and Tesla V100 GPUs, with specific training parameters such as learning rate, batch size, and optimizer settings.
Evaluation Metrics
The Intersection over Union (IoU) metric is used to quantify the performance of the proposed approach in all experiments.
Results and Analysis
Evaluation Results and Comparisons
The proposed MV-MOS model achieves the highest accuracy of 78.5% on the validation set and 80.6% on the test set of the SemanticKITTI-MOS benchmark, outperforming state-of-the-art models.

Ablation Studies
Ablation experiments demonstrate the effectiveness of the individual structures and modules in the MV-MOS model. The results show that the combination of the semantic branch, BR-Motion-Branch, and Mamba Block significantly improves segmentation accuracy.

Qualitative Analysis
Qualitative analysis through visualization shows that the MV-MOS model correctly infers more points and provides more complete segmentation of objects compared to other models.

Computational Efficiency
The MV-MOS model demonstrates competitive inference time, making it suitable for real-time processing in practical applications.
Overall Conclusion
The MV-MOS model introduces a novel approach to 3D moving object segmentation by effectively fusing motion and semantic features from multiple 2D representations. The dual-view and multi-branch structure, combined with the Mamba-based feature fusion module, enhances the model’s capability to capture rich and complementary information. Comprehensive experiments validate the effectiveness and generalization of the proposed model, making it a promising solution for autonomous driving and robotics applications.


