





Authors:
Yunxin Tang、Siyuan Tang、Jian Zhang、Hao Chen
Paper:
https://arxiv.org/abs/2408.10600
Breast Tumor Classification Using Self-Supervised Contrastive Learning from Ultrasound Videos
Introduction
Breast cancer is the most common cancer among women and the second leading cause of cancer-related deaths. Early detection through screening significantly reduces mortality and treatment costs. Ultrasonography is a widely used method for breast cancer detection due to its affordability, non-invasiveness, and real-time imaging capabilities. However, the interpretation of ultrasound images can be challenging and time-consuming for radiologists. Automatic diagnosis systems based on deep learning have the potential to alleviate this burden by improving diagnostic accuracy and reducing variability.
Despite their promise, deep learning models are typically data-hungry, requiring large amounts of labeled data for training. Acquiring such labeled data is expensive and requires expert knowledge. To address this issue, recent research has focused on self-supervised learning techniques, which can learn useful representations from unlabeled data. This study proposes a self-supervised contrastive learning framework for breast tumor classification using ultrasound videos, aiming to reduce the dependency on labeled data.
Related Work
Several studies have explored self-supervised learning techniques in medical imaging:
- Jiao et al. (2020) proposed a self-supervised learning approach for fetal ultrasound videos, training a model to learn anatomical structures by correcting the order of reshuffled video clips and predicting geometric transformations.
- Guo et al. (2021) developed a multitask framework combining benign/malignant classification with contrastive learning, achieving good performance on a breast ultrasound dataset.
- Kang et al. (2021) introduced a deblurring masked autoencoder for thyroid nodule classification, incorporating deblurring into the self-supervised pretraining task.
- Lin et al. (2021) compiled a breast ultrasound video dataset and developed CVA-Net to learn temporal information between video frames for lesion classification.
Building on these works, this study proposes a self-supervised contrastive learning framework that leverages a large dataset of breast ultrasound videos to learn effective representations for tumor classification.
Research Methodology
Overall Framework
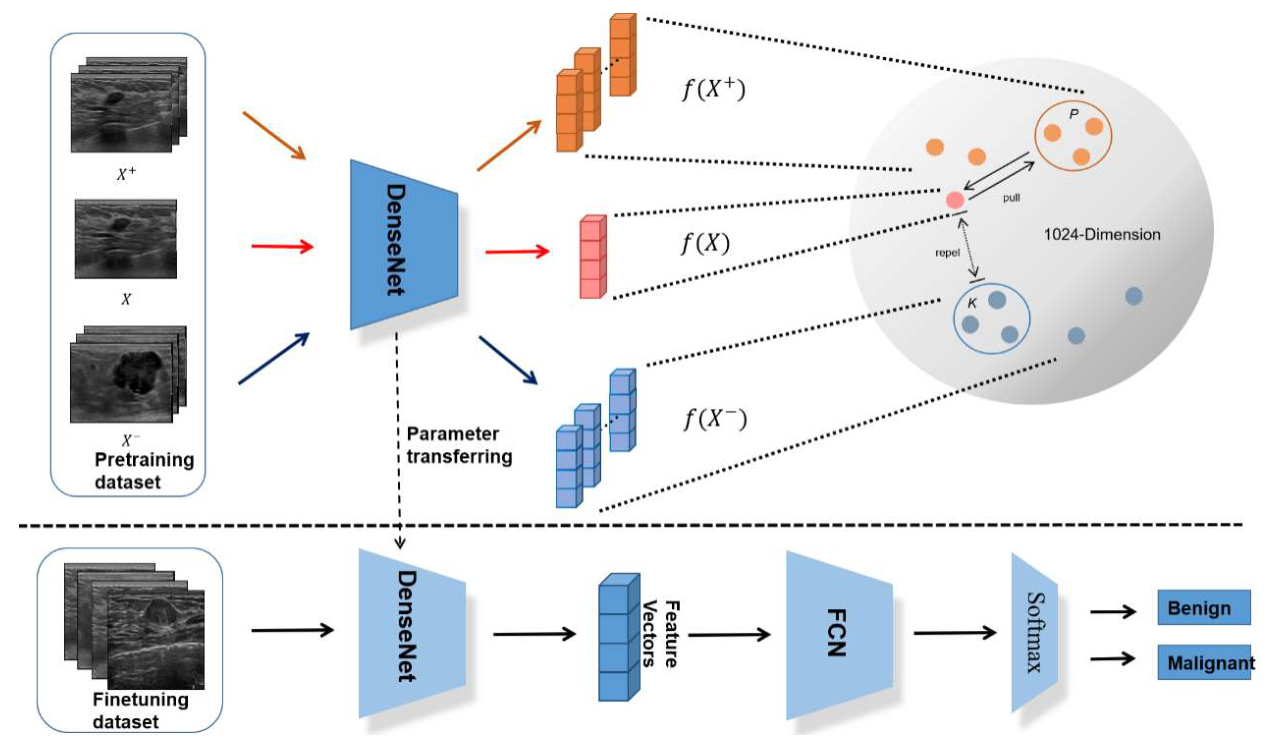
The proposed framework consists of two neural networks: a triplet network for self-supervised contrastive learning and a classification network for fine-tuning on the downstream benign/malignant classification task. The triplet network learns representations from video clips using anchor, positive, and negative samples. The loss function is designed to pull the anchor image closer to its positive partners while repelling it from negative partners in the feature space. The feature space dimension is set to 1,024, and different DenseNet architectures (DenseNet121, DenseNet161, DenseNet169, and DenseNet202) are used as the backbone.


Loss Functions
Two loss functions are evaluated in this study:
- InfoNCE Loss: A contrastive learning loss commonly used in multiclass classification problems.
- Hard Triplet Loss: A modified version of the classic triplet loss, biased towards hard negative and positive samples. This loss forces the network to discriminate between hard-to-recognize samples, improving lesion representations and convergence speed.
An L2 regularization term is added to the final loss, and a momentum-based stochastic gradient descent method with cosine annealing is used for optimization.
Experimental Design
Datasets
Two datasets are compiled for this study:
- Pretraining Dataset: Consists of 1,360 breast ultrasound videos from 200 patients, with 11,805 anchor images, 188,880 positive images, and dynamically generated negative images (1,310,355 per epoch).
- Finetuning Dataset: Includes 400 breast ultrasound images (175 benign and 225 malignant) from 66 patients, with no overlap with the pretraining dataset.

Data Augmentation and Image Enhancement
Data augmentation techniques such as small-angle rotation and left-right flipping are applied to the images. Mean normalization, fuzzy enhancement, and bilateral filtering are used to reduce noise and enhance the signal-to-noise ratio.
Model Training
The triplet network is pretrained for 200 epochs, and the model parameters corresponding to the lowest loss are transferred to the downstream classification network. During fine-tuning, most weights of the transferred DenseNet are frozen, except those in Dense Blocks 3 and 4. A fully connected layer and a softmax layer are added for the classification task, and a fivefold cross-validation strategy is used for evaluation.
Results and Analysis
Model Performance and Comparison
The proposed triplet network with hard triplet loss achieves the highest AUC (0.952) for the benign/malignant classification task, outperforming models pretrained on ImageNet and those using InfoNCE loss. The results confirm that better representations are learned when the network is forced to discriminate hard-to-recognize samples.

Comparison with Other SOTA Models
The proposed model is compared with three state-of-the-art models pretrained on ImageNet (MoCo-v2, BYOL, and SwAV). The triplet network with DenseNet169 as the backbone significantly outperforms these models, indicating that representations learned from natural images may not be suitable for breast ultrasound images.

Performance on Small Finetuning Datasets
The dependence of the pretrained model on the number of labeled data is evaluated using four small datasets (S80, S120, S175, and S190). The triplet network with hard triplet loss consistently achieves the highest AUC across all datasets, demonstrating its effectiveness in reducing the demand for labeled data.

Overall Conclusion
This study presents a self-supervised contrastive learning framework for breast tumor classification using ultrasound videos. The proposed triplet network with hard triplet loss achieves superior performance compared to state-of-the-art models pretrained on ImageNet and other contrastive learning techniques. The framework significantly reduces the dependency on labeled data, making it a competitive candidate for automatic breast ultrasound image diagnosis.
The results highlight the potential of self-supervised learning in medical imaging, paving the way for more efficient and accurate diagnostic systems that can alleviate the burden on radiologists and improve patient outcomes.

Acknowledgments
Hidden for peer review.
Conflicts of Interest
No conflicts of interest.


