





Authors:
Junhao Chen、Bowen Wang、Zhouqiang jiang、Yuta Nakashima
Paper:
https://arxiv.org/abs/2408.10573
Introduction
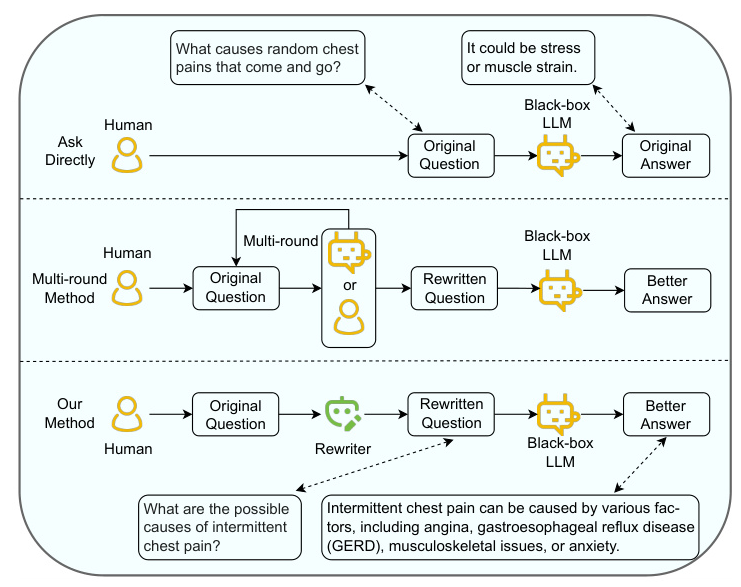
Large Language Models (LLMs) have revolutionized the field of question answering (QA) by leveraging extensive world knowledge from vast publicly available corpora. However, the effectiveness of LLMs in QA is often compromised by the vagueness of user questions. This paper addresses this issue by introducing a single-round instance-level prompt optimization technique known as the question rewriter. By enhancing the clarity of human questions for black-box LLMs, the question rewriter significantly improves the quality of generated answers. The rewriter is optimized using direct preference optimization based on feedback from automatic criteria for evaluating generated answers, eliminating the need for costly human annotations.
Related Work
Early work on prompt optimization primarily focused on white-box models. With the rise of black-box models like GPT-3 and Claude, subsequent research targeted these models, decomposing prompts into task-level instructions and instance-level inputs. Recent studies have shown that directly optimizing prompts at the instance level offers more flexibility and can lead to better responses. However, these methods often require multi-round interactions with humans or LLMs. This paper proposes a single-round instance-level prompt optimization method for long-form question answering (LFQA), which is closer to real-world QA scenarios.
Research Methodology
The proposed question rewriter aims to rewrite user questions to make them more understandable for LLMs, thereby generating better answers. The method assumes the presence of automatic criteria to evaluate generated answers, which are typically provided in LFQA datasets. These criteria are used to identify better and worse rewritten questions. The rewriter is trained using direct preference optimization (DPO), which does not require costly human interactions or a differentiable reward model.
Sampling Rewritten Questions
A pre-trained LLM is used to sample rewritten questions without fine-tuning, leveraging prompt engineering. Top-p sampling is employed to generate multiple rewritten questions for each original question.
Making Better and Worse Question Pairs
LFQA datasets provide methods for evaluating generated answers, such as factual comprehensiveness and precision. These automatic evaluation criteria are used to judge the goodness of rewritten questions. Better and worse question pairs are created by comparing the generated answers to the original and rewritten questions.
Optimizing Question Rewriter
The question rewriter is trained using DPO, which optimizes the rewriter based on the better and worse question pairs. The training process involves computing the average probability of tokens in the rewritten questions and using a loss function to optimize the rewriter.
Experimental Design
Dataset
Three distinct LFQA datasets equipped with automated evaluation criteria were used: K-QA, TruthfulQA, and OASST1QA. These datasets cover various domains, including medicine, health, and law, and provide criteria for evaluating the factual comprehensiveness, precision, truthfulness, and informativeness of answers.


LLMs
The base model for the question rewriter and the answer generation model is Llama3-8B-instruct. The generalizability of the rewriter was tested on multiple answer generation LLMs, including Mistral-7B-v0.2, Zephyr-7B-beta, Gemma-1.1-7B, GPT-3.5, and GPT-4o.
Hyperparameters
The DPO training was conducted with a dropout rate of 0.8, a training batch size of 32, and a testing batch size of 64. Top-p sampling was used to generate rewritten questions, with a cumulative probability set to 0.999 and a temperature of 1.
Device
The experiments were conducted on systems equipped with NVIDIA A100 GPUs. Due to the extensive length of the OASST1QA dataset, some samples were processed on a system with four NVIDIA A100-80GB-PCIe GPUs.
Baselines
The proposed method was compared with the original questions, the initial Llama3-8B-instruct rewriter, and Zero-Shot Chain-of-Thought (Zero-Shot CoT) prompting.
Results and Analysis
Performance Evaluation
The proposed method demonstrated superior performance across multiple datasets and LLMs. For the K-QA dataset, the method consistently achieved the highest factual comprehensiveness scores and the lowest factual contradiction scores. In the TruthfulQA dataset, the method increased the truthfulness score while maintaining informativeness. For the OASST1QA dataset, the method outperformed others in most cases.

Impact of N+ and N−
The performance of the question rewriter was evaluated with varying numbers of better and worse question pairs. The results indicated that the optimal values for these parameters depend on the dataset, with performance generally improving up to a certain point before declining due to overfitting.

Comparison with Task-level Prompt Optimization
The method was adapted to optimize task instructions and tested on the K-QA dataset. The results showed that instance-level optimization was more effective than task-level optimization, highlighting the challenges of consistently implementing effective task-level prompt optimization for LFQA.
Cross-Dataset Generalizability
The performance of rewriters trained on different datasets was evaluated across other datasets. Rewriters trained on more complex LFQA datasets with multiple evaluation criteria demonstrated better generalizability.
Attribute Analysis
A quantitative analysis of the attributes impacting the evaluation criteria of generated answers was conducted. The analysis revealed that attributes like non-leadingness, word choice, and tone significantly contributed to the quality of the generated answers.

Overall Conclusion
This paper proposes a single-round instance-level question optimization method for LFQA tasks, known as the question rewriter. The method employs direct preference optimization with automatic evaluation criteria, eliminating the need for costly human interactions. Experimental results demonstrated the effectiveness of the question rewriter in generating better questions and answers across multiple datasets and LLMs. Future work could explore domain-agnostic approaches to further enhance the generalizability of the question rewriter.

Code:
https://github.com/3244we/question-rewriter


