





Authors:
Ritwik Mishra、Sreeram Vennam、Rajiv Ratn Shah、Ponnurangam Kumaraguru
Paper:
https://arxiv.org/abs/2408.10604
Introduction
In the realm of Question Answering (QA) systems, most existing datasets focus on factoid-based short-context questions, predominantly in high-resource languages. However, there is a significant gap when it comes to non-factoid questions, especially in low-resource languages. This study introduces MuNfQuAD, a multilingual QA dataset designed to address this gap by focusing on non-factoid questions. The dataset leverages interrogative subheadings from BBC news articles as questions and the corresponding paragraphs as silver answers, encompassing over 370K QA pairs across 38 languages.
Related Work
Existing QA Datasets
Several QA datasets have been developed over the years, primarily focusing on factoid questions:
– WikiQA: Extracted questions from Bing query logs and matched them with Wikipedia articles.
– SQuAD: A benchmark dataset where crowdworkers generated questions based on Wikipedia passages.
– Natural Questions: The largest factoid-based dataset, including long and short answers with Wikipedia articles as context.
Multilingual QA Datasets
Efforts in multilingual QA datasets include:
– bAbI: Contained factoid-based questions in English and Hindi.
– XQA: Gathered questions from Wikipedia’s “Did you know?” boxes.
– MLQA: Generated questions from English Wikipedia articles and translated them into multiple languages.
– TyDi QA: Focused on natural questions in multiple languages, encouraging curiosity-driven questions.
MuNfQuAD stands out by providing a large-scale multilingual dataset specifically for non-factoid questions, filling a critical gap in existing resources.
Research Methodology
Data Collection
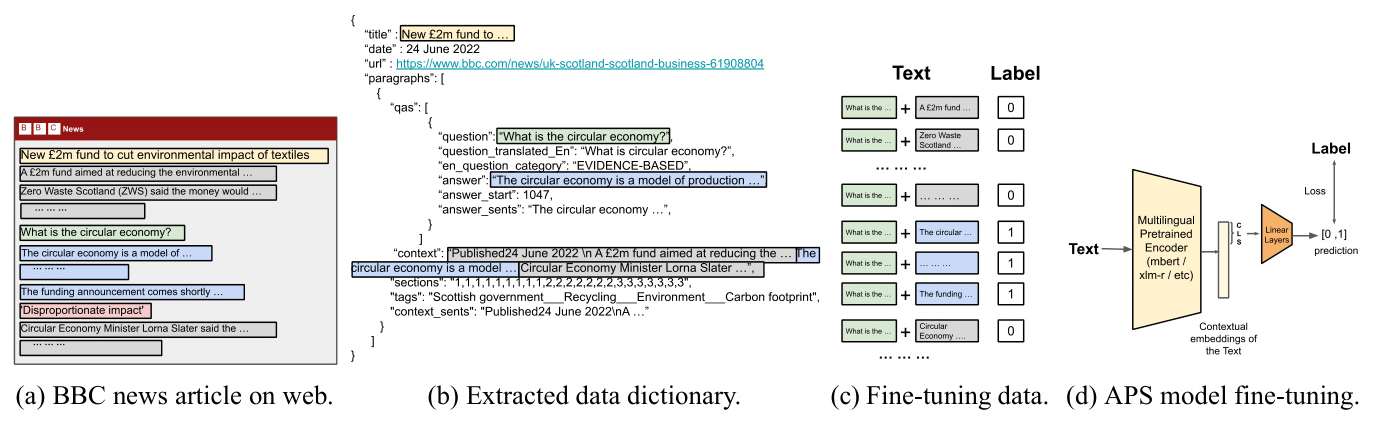
The dataset was curated by scraping BBC news articles in multiple languages. The process involved:
1. Scraping Articles: Using Python libraries to scrape articles from the BBC website and the Wayback Machine.
2. Identifying Questions: Extracting interrogative subheadings as questions.
3. Extracting Answers: Using the paragraphs following the interrogative subheadings as silver answers.
Silver Labels
The dataset relies on the hypothesis that paragraphs succeeding an interrogative subheading contain the answer, referred to as silver labels. This approach has been validated in other domains like legal and medical text classification.
Experimental Design
Dataset Statistics
MuNfQuAD comprises over 329,000 unique QA pairs, making it the largest multilingual QA dataset to date. The dataset includes:
– 38 languages: Covering a wide range of low-resource languages.
– Diverse Content: Articles predominantly from the Asiatic subcontinent.
Answer Paragraph Selection (APS) Model
The APS model is designed to identify paragraphs that answer a given question. The model architecture includes:
1. Input: Concatenation of a question and a candidate paragraph.
2. Output: Probability score indicating the likelihood of the paragraph being an answer.
3. Training: Fine-tuning multilingual pretrained encoders like XLM-Roberta and mBERT.
Baselines
Baseline models include:
– Sentence Transformers: Using vector embeddings to calculate cosine similarity between questions and paragraphs.
– TF-IDF Vectorizer: Training on the dataset to derive confidence scores based on word overlap.
Results and Analysis
Model Performance
The APS model fine-tuned with the XLM-V encoder demonstrated the highest macro F1 and Label-1 F1 scores, outperforming baseline models. The model achieved:
– Accuracy: 80%
– Macro F1: 72%
– Label-1 F1: 56%
Evaluation on Golden Set
A subset of the dataset was manually annotated to create a golden set. The evaluation revealed:
– Success Rate: 98% of questions could be answered using their silver answers.
– Model Generalization: The APS model effectively generalized to certain languages within the golden set.
Large Language Models (LLMs)
Experiments with LLMs like ChatGPT and BLOOM showed that while LLMs can be used as APS models, they require substantial computational resources and may not outperform fine-tuned APS models.
Overall Conclusion
MuNfQuAD addresses a significant gap in multilingual QA datasets by focusing on non-factoid questions. The dataset, along with the fine-tuned APS model, provides a valuable resource for developing and evaluating QA systems in low-resource languages. Future work includes exploring generative techniques for QA and developing multilingual answer span extractors.
Illustrations
Data Collection and Model Fine-Tuning

Figure 1: An illustration depicting the data collection process and fine-tuning of the APS model.

Multilingual QA Dataset Statistics

Table 1: Attributes of different multilingual QA datasets.
MuNfQuAD Statistics

Table 2: Overview of MuNfQuAD statistics.
Frequent Entities in Questions

Table 4: Most frequent entities found in translated English MuNfQuAD questions.
Frequent N-grams in Questions

Table 3: Most frequent n-grams in translated English MuNfQuAD questions.
Model Performance on Golden Set

Table 6: Performance of silver labels and best performing APS model on the golden set.
Comparative Performance of APS Models

Table 5: Comparative performance of various models on the MuNfQuAD Test Set for APS task.
Question Category Distribution

Figure 2: Distribution of question categories in MuNfQuAD and NLQuAD.
MuNfQuAD represents a significant advancement in the field of multilingual QA, providing a robust dataset and model for non-factoid questions across a diverse range of languages.


