





Authors:
Wenxuan Xie、Gaochen Wu、Bowen Zhou
Paper:
https://arxiv.org/abs/2408.07930
Introduction
Text-to-SQL is a challenging task that involves generating SQL queries from natural language questions. This task is crucial for retrieving database values without human intervention. There are two main categories of approaches for Text-to-SQL: In-Context Learning (ICL) and Supervised Fine-Tuning. While earlier work has achieved human-level performance on simpler datasets like Spider, there remains a significant gap on more complex datasets such as BIRD. To address these challenges, the authors propose MAG-SQL, a multi-agent generative approach that incorporates soft schema linking and iterative Sub-SQL refinement.
Methodology
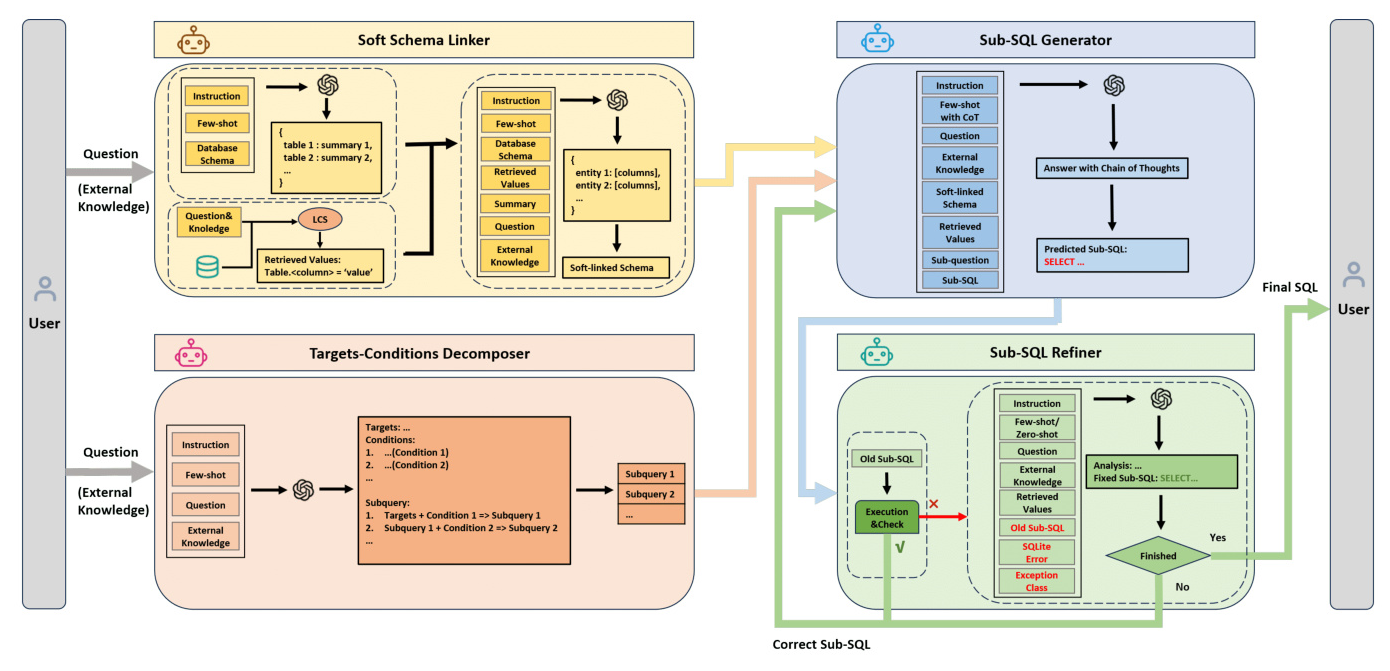
The MAG-SQL framework consists of four agents: Soft Schema Linker, Targets-Conditions Decomposer, Sub-SQL Generator, and Sub-SQL Refiner. These agents work together to generate accurate SQL queries from natural language questions.
Soft Schema Linker
The Soft Schema Linker is responsible for filtering the large database schema and providing relevant information for SQL generation. This task is divided into five parts:
-
Schema Representation: The database schema is serialized into a list, where each item is a tuple representing a column’s information, including name, data type, description, and value examples.
-
Table Summarization: LLMs summarize the information stored in each table, which helps in selecting the most relevant table and columns based on the natural language question.
-
Value Retrieval: The longest common substring (LCS) algorithm retrieves question-related values from the database, which helps in selecting the correct columns when values of TEXT type appear in the question.
-
Entity-based Schema Linking: This step involves extracting entities from the question, analyzing their relevance based on the table summary and database schema, and finding the most relevant columns for each entity.
-
Soft Schema Construction: This approach keeps the entire schema but adds additional detailed descriptions for selected columns, reducing the length of the prompt while allowing access to the entire database schema.


Targets-Conditions Decomposer
The Targets-Conditions Decomposer breaks down complex questions into a series of sub-questions. This method ensures consistent granularity in question decomposition by dividing queries into targets and conditions. Each sub-question is obtained by adding a condition to the previous sub-question, except for the first one, which is composed of targets and the first condition.

Sub-SQL Generator
The Sub-SQL Generator predicts Sub-SQL for the current sub-question based on the previous sub-question and Sub-SQL. This design allows the generator to add only one condition at a time, reducing the difficulty of reasoning. The Chain of Thoughts (CoT) prompting method is used to help LLMs understand and utilize various pieces of information in the prompt.

Sub-SQL Refiner
The Sub-SQL Refiner corrects the Sub-SQL based on feedback obtained after executing the Sub-SQL. If the Sub-SQL can be executed successfully, the Refiner checks for null values. If not, the Sub-SQL is corrected based on error information and re-tested until it is correct or the maximum number of corrections is reached.

Experiments
Experimental Setup
The authors evaluated MAG-SQL on the BIRD and Spider datasets using GPT-3.5 and GPT-4 as the backbone of all agents. The BIRD dataset includes 95 large-scale real databases with dirty values, while the Spider dataset is a large-scale, complex, and cross-domain dataset widely used as a benchmark for Text-to-SQL.
Metrics
- Execution Accuracy (EX): Measures the correctness of the execution result of the predicted SQL.
- Valid Efficiency Score (VES): Measures the efficiency of a valid SQL query based on execution time.
Results and Analysis
BIRD Results
MAG-SQL achieved significant performance gains on the BIRD dataset, with an execution accuracy of 61.08% using GPT-4, compared to 57.56% for MAC-SQL and 46.35% for vanilla GPT-4.

Spider Results
MAG-SQL also demonstrated generalizability on the Spider dataset, achieving an 11.9% improvement over GPT-4 (zero-shot).

Ablation Study
The ablation study showed that each agent in MAG-SQL is important for performance enhancement. Removing any agent resulted in decreased accuracy across all difficulty levels.

The components of the Soft Schema Linker, including Table Summarization and Value Retrieval, also played a positive role in schema linking.

Conclusion
MAG-SQL is a novel multi-agent generative approach for efficient Text-to-SQL, comprising four LLM-based agents that provide new ideas for schema-linking, question decomposition, SQL generation, and SQL correction. The approach achieves better performance on the BIRD dataset than all previous work at the time of writing and demonstrates the potential of LLMs in Text-to-SQL tasks.
Limitations
Despite significant improvements, there is still a gap compared to human performance. The authors identify three main limitations:
- Single closed-source backbone: Using open-source domain-specific LLMs could further improve results.
- Fixed Workflow: A more flexible multi-agent system that can autonomously plan tasks and dynamically invoke various tools is needed.
- Unstable Output: The probability-based output of LLMs can be inconsistent, and a better solution to this problem could lead to significant breakthroughs.
By addressing these limitations, future work can further enhance the performance and robustness of Text-to-SQL systems.


