





Authors:
Zhili Cheng、Zhitong Wang、Jinyi Hu、Shengding Hu、An Liu、Yuge Tu、Pengkai Li、Lei Shi、Zhiyuan Liu、Maosong Sun
Paper:
https://arxiv.org/abs/2404.18243
Introduction
In recent years, advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs) have showcased impressive capabilities in understanding and generating human-like text and realistic images. However, their application in embodied AI, where agents interact in physical or simulated environments, remains limited. This gap hinders the performance of complex real-life tasks in physical environments. Existing integrations often lack open-source access, which restricts collective progress in this field.
To address these challenges, researchers from Tsinghua University have introduced LEGENT, an open and scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale.
Related Work
Embodied Environment
Embodied environments have been extensively utilized in games and robotics, focusing primarily on visual AI and reinforcement learning. Platforms like AI2-THOR, Habitat, and iGibson have made significant strides in creating realistic and interactive environments. However, these platforms often fall short in accommodating the training of LMMs, which require diverse and large-scale data to integrate embodied capabilities.
LMMs-based Embodied Agent
Noteworthy studies have concentrated on developing embodied models capable of end-to-end operation. However, the datasets and models in these studies are not publicly available, limiting the open-source community’s ability to build upon these advancements.
Scene Generation
Scene generation has demonstrated significant effectiveness in training embodied agents. Recent studies leverage prior knowledge of LLMs to propose algorithms that generate diverse, high-quality scenes, enhancing the training process for embodied agents.
Agent Trajectory Generation
Research in agent trajectory generation focuses on crafting reward functions to guide small policy models. However, applying reward-based training to large foundation models incurs high costs and instability. Pioneering efforts in code generation for robotics and trajectory generation for imitation learning align with the approach of generating large-scale embodied trajectories for training LMMs.
Research Methodology
Scene Design
The design of scenes in LEGENT emphasizes interactivity and diversity, striving for a versatile and scalable environment that enriches the training of embodied agents for wide application.
- Realistic Physics: LEGENT provides a real-time simulation that closely mirrors real-world physics, supporting realistic effects like gravity, friction, and collision dynamics.
- Diverse Rendering: LEGENT integrates various rendering styles, allowing easy transitions between rendering styles to accommodate different requirements.
- Interactable Objects: Both agents and users can manipulate various fully interactable 3D objects, enabling actions such as picking up, transporting, positioning, and handing over these objects.
- Scalable Assets: LEGENT supports importing customized objects at runtime, including user-supplied 3D objects, objects from existing datasets, and those created by generative models.
Agent Design
The agent in LEGENT is designed to emulate human interactions and ensure compatibility with LMMs.
- Egocentric Observations: The agent is equipped with egocentric vision, captured by mounting a camera on the agent’s head.
- Language Interaction: Users and agents can communicate with each other in natural language, grounding language within the environment.
- Generalizable Actions: Agents can perform a range of actions, including navigation, object manipulation, and communication. Actions are expressed in a generalizable manner, targeting new environments, including real-world settings.
- Realistic Animation: LEGENT features precise humanoid animations using inverse kinematics and spatial algorithms, enabling lifelike movements.
Interface Design
LEGENT offers a user-friendly interface for researchers to integrate LLMs and LMMs with the embodied environment easily.
- Playable Interaction: The user interface is designed to be as intuitive as playing a video game, facilitating straightforward visual debugging and qualitative analysis.
- Simple Code: LEGENT is equipped with a Python toolkit to enable interaction between the agent and the environment, with concise code examples available in the documentation.
- Scene Generation Interface: The platform incorporates various scene-generation techniques, providing a straightforward JSON format for specifying a scene.
- Agent Trajectory Generation Interface: Users can create training datasets consisting of egocentric visual records and corresponding ground truth actions paired with task instructions or queries.
Experimental Design
Scene Generation
Scene generation offers agents diverse embodied experiences. LEGENT integrates two scene generation methods:
- Procedural Generation: Utilizes the procedural generation algorithm created by ProcTHOR, designed to create realistic indoor scenes at scale by integrating prior knowledge of object placement and spatial relationships.
- Language-Guided Generation: Implements methods in Holodeck, offering an LLM-powered interface to generate single or multi-room indoor scenes given any natural language query.
Task Generation
Tasks are expressed in language paired with specific scenes, contextualizing each task within the environment. Two strategies are employed:
- Task Generation for Given Scenes: Serializes generated scenes into detailed textual descriptions and presents them to LLMs with crafted instructions.
- Scene Generation for Given Tasks: Efficiently generates large-scale samples for specific tasks based on the scene generation algorithm.
Trajectory Generation
Trajectories for training embodied agents comprise continuous sequences of egocentric observations and actions. The main challenge lies in accurately determining ground-truth actions for each step. LEGENT uses LLMs and motion planners to label the ground truth actions, inspired by pioneering works in code generation for robotics.
Results and Analysis
Prototype Experiments
Prototype experiments were conducted to assess the utility of generated data on two embodied tasks: “Come Here” for navigation and “Where Is” for embodied question answering. Task complexity varied from navigating in one room to the more intricate two rooms. The results demonstrated several key observations:
- GPT-4V Performance: GPT-4V struggled in these tasks, reflecting a lack of embodied experience in mainstream LMMs.
- Training Data Impact: Increasing training data improved the model performance.
- Generalization: The navigational skills developed from the “Come Here” task in a two-room environment generalized well to the untrained task scenario, enhancing the model’s ability to navigate in two rooms for the embodied question answering task.
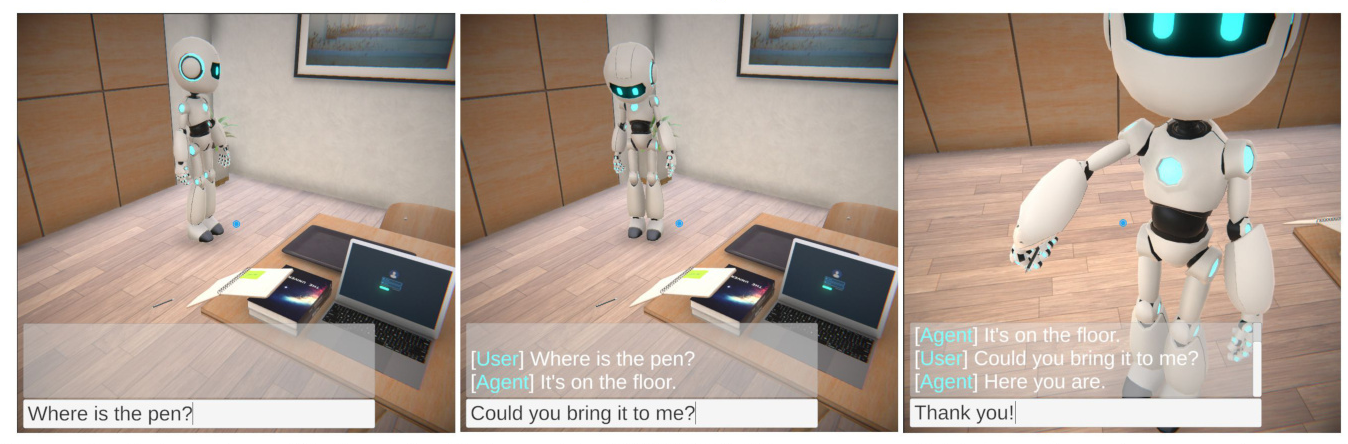
Demo of LEGENT
A demo video of LEGENT is available, showcasing the engagement with embodied agents in LEGENT, primarily leveraging LLMs and motion planners. With advancements in LMMs’ capability of egocentric perception and control, the demonstration is expected to evolve into a fully embodied experience, independent of any extra internal information.
Overall Conclusion
LEGENT represents a significant step forward in the development of embodied agents, focusing on integrating LMMs with scalable embodied training. By bridging the gap between embodied AI and LMM’s development, LEGENT aims to inspire further research in this field. Future releases will prioritize building a more diverse data generation pipeline, scaling model training, unifying humanoid animation with robotic control, and improving scene generation to support more diverse and realistic scenes.














