





Authors:
Moumita Bhattacharya、Vito Ostuni、Sudarshan Lamkhede
Paper:
https://arxiv.org/abs/2408.10394
Introduction
In the realm of digital services, search and recommendation systems are pivotal for enhancing user experience. Traditionally, these systems are developed independently, leading to increased complexity in maintenance and technical debt. This paper introduces a unified deep learning model, UniCoRn (Unified Contextual Recommender), designed to efficiently handle both search and recommendation tasks. By consolidating these models, the authors aim to reduce overhead and improve the reliability and effectiveness of machine learning systems.
Related Work
The complexity of maintaining separate models for search and recommendation tasks has been well-documented. Previous studies [4, 6] have highlighted the long-term costs and reduced reliability associated with this approach. Additionally, there is evidence suggesting that search and recommendation systems can benefit from each other [7]. This paper builds on these insights by proposing a unified model that leverages shared data and context to improve performance across both tasks.
Research Methodology
Model Unification
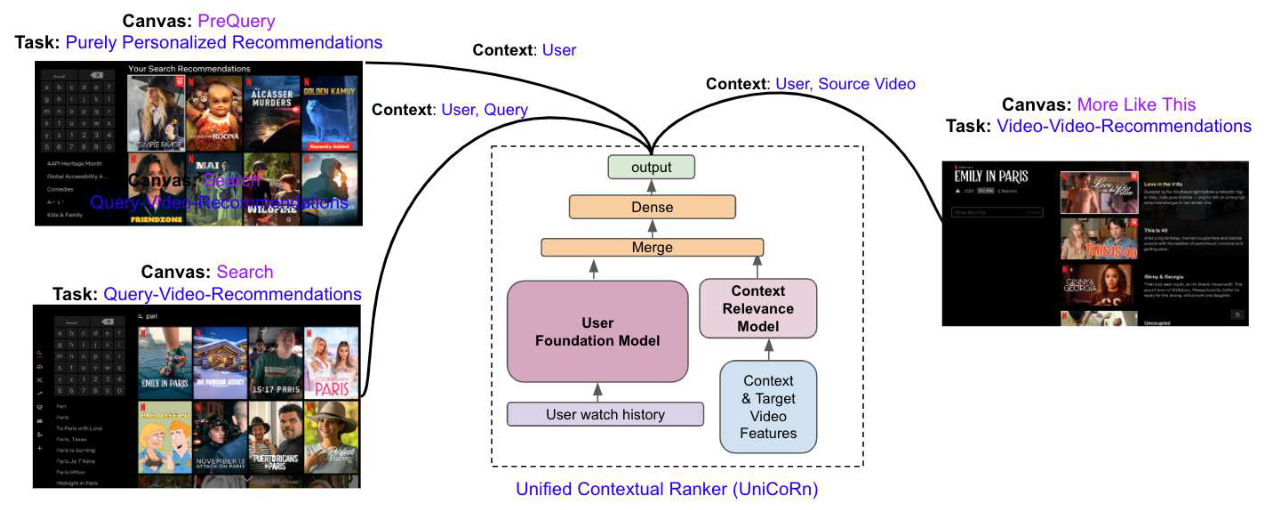
Prior to this research, Netflix employed several distinct models for various applications, such as query-driven searches and item-to-item recommendations. The authors embarked on a journey to unify these models, treating search and recommendation as two sides of the same coin. The unified model incorporates a broader context, including user ID, query, country, source entity ID, and task type. This approach allows the model to generate probability scores for positive engagement with an entity, facilitating both search and recommendation tasks.
Context Imputation
To address the issue of missing context in certain tasks, the authors developed heuristics for imputing missing values. For search tasks, missing context values were set to null, while for recommendation tasks, missing query contexts were imputed using tokens from the display names of entities. This imputation approach enhances cross-application learning and improves feature coverage.
Model Architecture
The model architecture includes several features, categorized into context-specific features (e.g., query length, source entity ID embedding) and context and target entity ID features (e.g., number of clicks for a given query). The deep learning model employs residual connections and feature crossing, using a binary cross-entropy loss function with an Adam optimizer. This architecture enables the model to generate ranked results for various contexts, such as search queries and personalized recommendations.


Experimental Design
Data Collection
The dataset used for training the model was gathered from user engagements across different tasks. This comprehensive dataset allowed the model to learn from a wide range of contexts, improving its ability to handle both search and recommendation tasks.
Training and Evaluation
The model was trained on this dataset, with features fed into the input layer and categorical features used to learn corresponding embedding layers. The training process involved several experiments and improvements, ultimately resulting in a single model that powers multiple applications within the Netflix product, including search, personalized pre-query canvas, and more.
Personalization
To incorporate personalization, the authors adopted an incremental approach. Initially, a semi-personalized model based on user clustering was developed, allowing for results caching. This was followed by a fully personalized model, which relied on separate recommendation model outputs as features. Finally, an end-to-end architecture was developed, incorporating pre-trained user and item representations fine-tuned with UniCoRn. These personalization approaches led to significant improvements in offline metrics for both search and recommendation tasks.
Results and Analysis
The unified model, UniCoRn, demonstrated either a lift or parity in performance across different tasks. Training a single model on a larger dataset and sharing data among tasks resulted in better performance compared to individual models. Key factors contributing to this success included the addition of task type as context, imputation of missing contexts, and feature crossing.
Personalization further enhanced the model’s performance, with a 7% lift for search tasks and a 10% lift for recommendation tasks. The authors successfully balanced relevance and personalization, ensuring that the model met strict latency requirements for instant results.
Overall Conclusion
This research showcases the potential of a unified model to handle both search and recommendation tasks effectively. By leveraging shared data and context, the UniCoRn model improves performance and reduces the complexity associated with maintaining separate models. The incorporation of personalization further enhances user experience, making this approach a promising solution for digital services.
Authors Bio
Moumita Bhattacharya and Vito Ostuni are research scientists at Netflix, specializing in search and recommendation algorithms. Sudarshan Lamkhede is an Engineering Manager at Netflix, leading the Foundation Model and Search Algorithms team.
Acknowledgments
The authors extend their gratitude to collaborators Roger Menezes, Gary Yeh, Manjesh Nilange, Jinning Zhong, Guru Tahasildar, Christoph Kofler, and Raveesh Bhalla, as well as internal reviewer Justin Basilico.
By unifying search and recommendation models, the authors have paved the way for more efficient and effective machine learning systems, demonstrating the benefits of shared data and context in improving performance across multiple tasks.


