





Authors:
Paper:
https://arxiv.org/abs/2408.10383
Introduction
Audio-image matching is a complex task that involves associating spoken descriptions with corresponding images. Unlike text-image matching, audio-image matching is less explored due to the intricacies of modeling audio and the limited availability of paired audio-image data. Speech carries rich information such as tone, timbre, stress patterns, and contextual cues, which can vary significantly among speakers and languages. This complexity, however, also means that speech can convey more information than text alone.
Recent advancements in multi-modal models have shown significant benefits for retrieval tasks. However, existing audio-image models have not achieved the same level of impact as text-image models. Current efforts in audio-image matching can be broadly categorized into pipeline models and End-to-End (E2E) models. Pipeline models, which rely on Automatic Speech Recognition (ASR) systems to transcribe speech into text, generally outperform E2E models. However, pipeline models may lose crucial non-textual information present in the raw audio.
In this study, we propose BrewCLIP, a novel bifurcated model that aims to capture both textual and non-textual information from speech to improve audio-image retrieval performance. BrewCLIP leverages strong pre-trained models, a prompting mechanism, and a bifurcated design to achieve state-of-the-art performance.
Related Work
Vision Language Models
Recent progress in vision-language models has been driven by powerful jointly-trained unimodal encoders. Text-visual learning has been the predominant focus, applied to tasks like image classification, text-image retrieval, and text-conditional image generation. However, audio-visual learning remains relatively under-explored, especially in terms of a unified framework for multiple tasks. Most efforts in this domain have concentrated on video-level tasks such as source separation, temporal synchronization, and audio-video matching.
Audio-Image Retrieval Task
Cross-modal retrieval is considered a gold standard for evaluating joint representation across different modalities. Image-speech matching, which involves associating spoken descriptions with corresponding images, requires models to effectively associate similar information from vastly different audio and image modalities. This task has immediate applications in content-based image retrieval, where spoken descriptions are used to retrieve relevant images.
End-to-End Model and Pipeline Model
Existing literature primarily tackles the image-speech retrieval task using either End-to-End (E2E) training or ASR-based pipeline models. E2E models directly associate raw audio with images, while pipeline models rely on ASR systems to convert raw audio into text, transforming the task into a transcription-image retrieval problem. Recent methods like FaST-VGS and SpeechCLIP have explored both approaches, with pipeline models generally achieving superior performance due to the robustness of ASR systems.
Prompting
Prompting has become a prevalent approach for few-shot fine-tuning of transformer-based models. It involves finding a set of tokens to prepend to a transformer’s input to improve its performance on a downstream task. Prompting has proven useful in both the NLP and visual domains and has been adapted for multi-modal tasks as well.
Research Methodology
Component Pretrained Models
BrewCLIP builds upon two powerful pre-trained models: Whisper and CLIP. Whisper is an ASR model that adopts an encoder-decoder transformer structure, achieving state-of-the-art performance for speech transcription. CLIP is a widely-used image/text encoder trained on a large dataset of image-text pairs, yielding highly generalizable encoders.
Task Definition
The audio-image matching task involves retrieving an associated instance from a given dataset based on a query of either modality (image or audio). The task can be evaluated in both zero-shot and self-supervised settings.
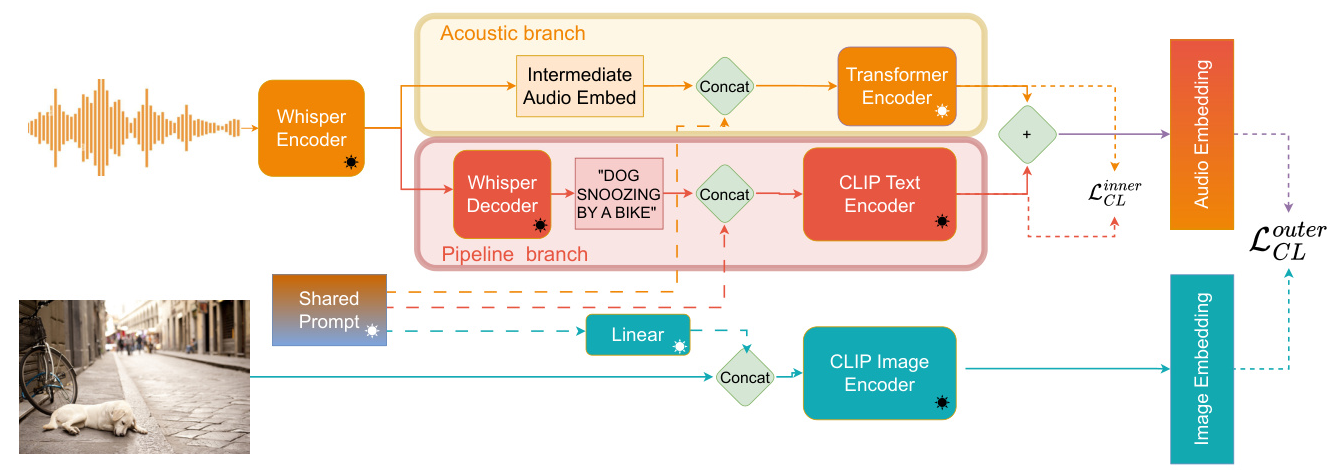
BrewCLIP: Bifurcated Whisper CLIP
BrewCLIP employs a bifurcated design capable of processing raw audio and its transcription in two distinct but parallel channels. This design aims to retain essential audio-specific information that might be lost during the transcription process while benefiting from the strengths of pre-trained text and image encoders.
Image Encoder
The image encoder tokenizes the raw image into patches, creating patch embeddings that are fed into the pre-trained CLIP image encoder to obtain the image representation.
Transcription-Based Textual Module
This module follows a typical pipeline approach, using Whisper to transcribe the audio and then feeding the transcription into the CLIP text encoder to obtain the textual feature.
Acoustic End-to-End Module
An additional End-to-End channel handles raw audio features to capture non-textual information. The intermediate audio embedding generated by Whisper is fed into a transformer encoder layer to obtain a broad acoustic representation, which is then fused with the textual feature.
Shared Prompting
A lightweight shared prompt design is used to encourage communication between different modalities. This involves concatenating prompts with the raw audio and textual embeddings and connecting them using a linear layer.
Loss Function
The model uses an InfoNCE loss to compute the similarity between audio and image representations. An inner-outer loss design is employed to regulate the learned acoustic embedding and facilitate the acquisition of non-textual information.
Experimental Design
Datasets
Experiments are conducted on both spontaneous and non-spontaneous spoken caption datasets: Flickr8k, SpokenCOCO, and Localized Narratives-COCO. Additionally, a Speech Emotion Recognition (SER) experiment is conducted using the RAVDESS dataset to test the model’s ability to capture non-textual information.
Evaluation Metrics
Performance is measured using top-K recall, which refers to whether the model retrieved the correct element as at least one of its first K guesses. Both image2speech and speech2image metrics are evaluated.
Results and Analysis
Comparison with State-of-the-Art
BrewCLIP surpasses existing state-of-the-art methods on the audio-image retrieval task, achieving higher scores even in zero-shot settings. The model performs particularly well on unscripted datasets like LN-COCO, where it significantly outperforms previous methods.
Hypothesis Validation
The pipeline-only model generally outperforms the E2E-only model, especially on scripted datasets. However, the full BrewCLIP model shows significant improvement on unscripted datasets, indicating that the E2E channel can compensate for transcription errors and capture non-textual information.
Speech Emotion Recognition
The SER experiment demonstrates that BrewCLIP can successfully capture mood information in utterances, supporting the hypothesis that the model can extract critical non-textual information.
Effect of Prompting
Shared prompting improves the model’s performance by establishing a connection between different modalities, enabling the model to comprehend long and detailed utterances.
Impact of Transcription Quality
The model’s performance is affected by the quality of transcriptions, with higher error rates leading to lower recall accuracy. The E2E channel helps mitigate this issue by providing additional audio-specific information.
Cross-Dataset Evaluation
BrewCLIP shows good generalizability across different datasets, with models trained on one dataset adapting well to others. However, models trained on unscripted datasets struggle with shorter, scripted sentences.
Overall Conclusion
BrewCLIP addresses the limitations of current pipeline-based approaches by retaining crucial audio-specific information through a bifurcated design. The model achieves state-of-the-art performance on audio-image retrieval tasks and demonstrates the importance of capturing non-textual information. Comprehensive experiments validate the effectiveness of the dual-channel architecture and highlight the potential for further improvements in audio-visual joint representation learning.
Limitations
The primary limitation of this study is the absence of a suitable dataset to directly demonstrate the model’s ability to capture shared non-textual connections between image-audio pairs. Additionally, the model faces constraints imposed by the pre-trained models used, such as the token limit of the CLIP text encoder and the center crop strategy of the CLIP image transformation.

Figure 1: Venn diagram illustrating our dual-channel design. Our text channel primarily focuses on capturing textual information, while the audio channel complements the textual information and facilitates the communication of non-textual information.


Figure 2: Detailed diagram of our proposed model. The acoustic channel is shaded in yellow and the transcription-based pipeline channel is shaded in red.

Table 1: Comparison between our proposed models and previous SotA methods on the audio-image bidirectional retrieval task.

Table 2: Comparison between different variations of our models (pipeline-only, E2E-only, and full model) on the audio-image retrieval task for SpokenCOCO, and LN-COCO.

Figure 3: Qualitative analysis of sample difference between LN-COCO and SpokenCOCO and their impacts on model performance.

Figure 4: Qualitative analysis of different variations of models on audio to image retrieval.

Table 3: SER Result on RAVDESS. Finetuned means only prompts and final transformer encoder layer in the audio channel are updated.

Figure 5: Failed case due to the Image Center Crop transform. The original image features a clock, a detail referenced in the spoken expression; however, the clock is cropped in the image.

Table 5: Cross-dataset Evaluation. Column denotes the dataset that the model is trained with and row denotes the dataset evaluated on.

Table 4: Comparison of using ASR output vs ground truth in our Zero-Shot models.


