





Authors:
Sagar Uprety、Amit Kumar Jaiswal、Haiming Liu、Dawei Song
Paper:
https://arxiv.org/abs/2408.10711
Introduction
Large Language Models (LLMs) such as GPT-4 and the LLaMa family have significantly advanced the field of Artificial Intelligence (AI) by enhancing the ability to comprehend and generate natural language text. These models are increasingly being deployed in real-world scenarios, making decisions and taking actions based on their understanding of the context. However, ensuring that these decisions align with human values and user expectations is a complex challenge, as human values and decisions are often influenced by cognitive biases. This study investigates the alignment of LLMs with human judgments, specifically focusing on order bias in similarity judgments. By replicating a famous human study on order effects in similarity judgments with various popular LLMs, the study aims to understand the settings where LLMs exhibit human-like order effect bias and discuss the implications of these findings.
Related Work
Cognitive Science and LLMs
Research at the intersection of cognitive science and LLMs primarily focuses on two perspectives. One line of work aims to utilize LLMs to study cognitive models and theories on a large scale by replicating human behavior with synthetic data generated from LLMs. The other research direction concerns the application of LLMs in automation and augmentation, where it is essential that decisions and judgments by LLM-based agents align with human preferences and judgments.
Human-like Cognitive Biases in LLMs
Several studies have investigated the presence of human-like cognitive biases in LLMs. For instance, LLMs have been found to display variability in responses similar to human judgment variability when repeatedly prompted with the same query. Additionally, LLMs have been tested against popular tasks like the Wason selection task and the Conjunction fallacy, revealing human-like biases in some tasks. Other studies have found common cognitive biases such as anchoring, framing, and group attribution in LLMs like GPT-3.5-Turbo, GPT-4, Llama2 7B, and Llama2 13B. These biases can be mitigated to some extent using various strategies.
Research Methodology
Tversky and Gati’s Similarity Effects Study
The study by Tversky and Gati involved participants rating the similarity between pairs of 21 countries on a scale of 0 to 20. The participants were divided into two groups, with each group rating the similarity of the same country pairs but in different orders. The study found statistically significant differences in similarity scores based on the order of the countries, suggesting that human similarity judgments may not always follow the symmetry assumption. Tversky and Gati hypothesized that the similarity of two entities would be higher if the first entity is the less prominent one in the pair.
Hypothesis for LLMs
The hypothesis for this study is that LLMs will also exhibit human-like asymmetric judgments due to the change of context exhibited by changing the order of countries in a pair. Additionally, a novel variant of the experiment was conducted by prompting the LLMs with both orders of countries in the same prompt, akin to asking a human participant to rate the similarity of countries in both orders. It is hypothesized that LLMs should render the exact same score for the two different orders of the country pairs in such cases.
Experimental Design
Models and Settings
The study investigated order effects in similarity using eight LLMs: Mistral 7B, Llama2 7B, Llama2 13B, LLama2 70B, Llama3 8B, Llama3 70B, GPT-3.5, and GPT-4. For the open-source models, their non-quantized 16-bit versions were used with default values of top_p (0.9) and top_k (50) parameters, while the temperature parameter was varied. The different temperature parameters used were 0.001, 0.5, 1.0, and 1.5.
Experiment 1 – Single Pair Prompts
In the original study, participants were asked to “assess the degree to which country A is similar to country B.” The equivalent prompt for LLMs was “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, assess the degree to which {country_1} is similar to {country_2}?” Three variants of single pair prompts were used:
- Single Similar Degree (SSD): “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, assess the degree to which {country_1} is similar to {country_2}?”
- Single Similar To (SST): “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, is {country_1} similar to {country_2}?”
- Single Similar And (SSA): “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, how similar are {country_1} and {country_2}?”
Experiment 2 – Dual Pair Prompts
In this experimental setting, LLMs were prompted with both orders of the two countries in the same prompt, eliminating the context created by changing orders. The expected output was a JSON with two keys: score_1 and score_2. Three different wording styles were used:
- Dual Similar Degree (DSD):
- Question 1: “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, assess the degree to which {country_1} is similar to {country_2}?”
- Question 2: “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, assess the degree to which {country_2} is similar to {country_1}?”
- Dual Similar To (DST):
- Question 1: “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, is {country_1} similar to {country_2}?”
- Question 2: “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, is {country_2} similar to {country_1}?”
- Dual Similar And (DSA):
- Question 1: “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, how similar are {country_1} and {country_2}?”
- Question 2: “On a scale of 0 to 20, where 0 means no similarity and 20 means complete similarity, how similar are {country_2} and {country_1}?”
Results and Analysis
Single Pair Prompts
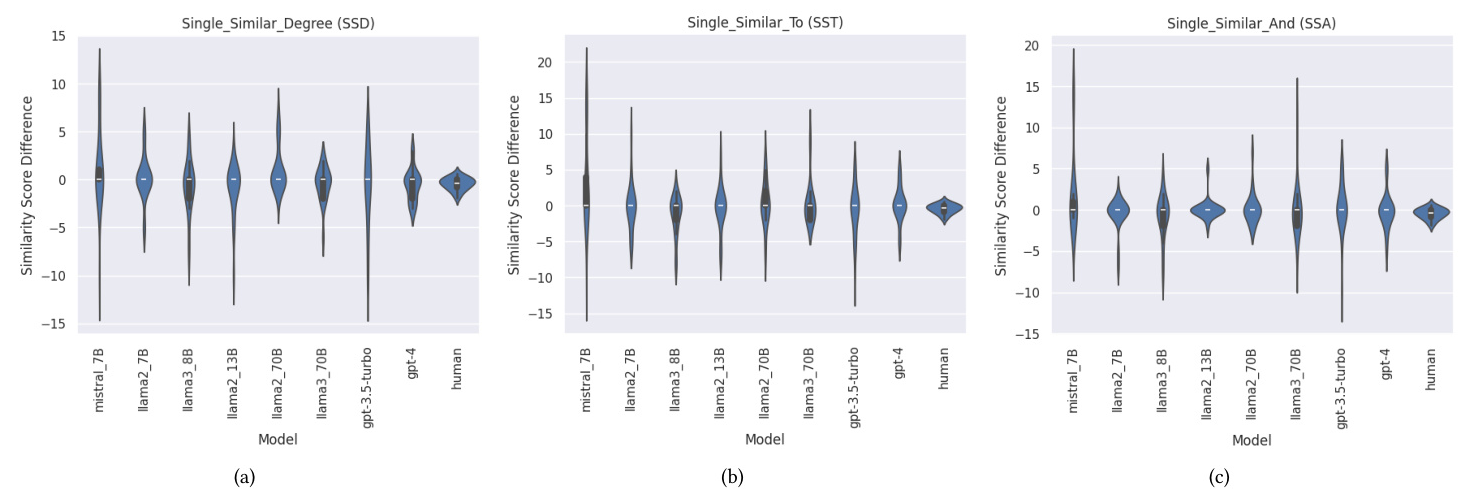
The study performed experiments for all 21 pairs of countries, for all 8 models, 4 temperature settings per model, and 3 different single-prompt styles, totaling 96 different instances of models-temperature-prompt settings for the set of 21 country pairs. The distribution of differences in scores for all country pairs for all models, temperature settings, and single prompt styles is shown in Figure 1. The human similarity score differences from Tversky and Gati’s study are also plotted for comparison.


Dual Pair Prompts
For the dual prompt setting, the hypothesis was that all similarity judgments should be symmetrical, as when deliberately shown both orders, humans should give the same rating to the country pairs. The similarity differences for dual prompt settings are plotted in Figure 3.

Statistical Analysis
An order effect was calculated when the mean difference between the similarity scores was statistically significant (𝛼< 0.05) based on a one-sided paired t-test. The direction being the increase in similarity score when the less prominent country is placed first in the pair. According to the second alignment criteria, the scores across the dual prompt styles should be symmetric for all models. Of the 96 different settings, only 9 settings met both criteria. Table 1 lists all these settings, including the t-statistic and p-value for each model-temperature-single prompt style setting.

Overall Conclusion
This study explored the alignment of LLM judgments with human judgments via similarity ratings to pairs of countries in different orders. The investigation involved studying the effect of context-driven asymmetry in human judgments using Tversky’s framework of similarity judgments. Out of the eight LLMs studied across different temperature settings and prompting styles, only Llama3 8B and GPT-4 models reported statistically significant order effects in line with human judgments. Even with these models, changing the temperature setting could lead to the disappearance of the effect. Future work aims to elicit and compare the reasoning generated by these models using different prompting approaches like Chain of Thought prompting. This will help understand the criteria used by LLMs to arrive at their similarity scores and whether and how this criteria differs for different orders of countries in the pair.


