





Authors:
Yihao Hou、Christoph Bert、Ahmed Gomaa、Godehard Lahmer、Daniel Hoefler、Thomas Weissmann、Raphaela Voigt、Philipp Schubert、Charlotte Schmitter、Alina Depardon、Sabine Semrau、Andreas Maier、Rainer Fietkau、Yixing Huang、Florian Putz
Paper:
https://arxiv.org/abs/2408.10715
Introduction
In the rapidly evolving field of artificial intelligence (AI), large language models (LLMs) have shown significant promise across various domains, including medicine. However, the integration of these models into clinical practice, particularly for tasks such as generating physician letters, presents unique challenges. This study, conducted by Yihao Hou and colleagues, investigates the fine-tuning of LLaMA-3, a large language model, for generating physician letters in radiation oncology while preserving patient privacy. The primary goal is to enhance efficiency in clinical documentation without compromising data security.
Related Work
Advancements in Large Language Models
Recent advancements in neural network architectures, such as Transformers, and training strategies like supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF), have significantly improved the capabilities of LLMs. Models like ChatGPT, Gemini, LLaMA, and PaLM have revolutionized various applications, including medical domains.
LLMs in Radiation Oncology
LLMs have demonstrated specialized medical expertise, including in radiation oncology. Studies have benchmarked LLM performance using standard exams and real clinical cases, showing promise in tasks such as medical education, research facilitation, and patient care. However, the risk of generating convincing but false responses remains a concern.
Data Privacy Concerns
Data privacy is a critical issue in clinical settings, especially under regulations like the EU General Data Protection Regulation (GDPR). Proprietary AI models often require data sharing with external providers, raising security concerns. Open-source LLMs like LLaMA, which can be deployed locally, offer a solution by eliminating the need for data sharing and ensuring patient data safety.
Research Methodology
Dataset Construction
The study utilized two types of texts: patient case summary reports and physician letters. A comprehensive dataset of physician letters from the Department of Radiation Oncology at University Hospital Erlangen, Germany, spanning from 2010 to 2023, was collected. For fine-tuning, 560 cases were formatted in a question-and-answer style, and 14,479 letters were used, with all private information anonymized.
Model Fine-Tuning
Base Models
The LLaMA-2 and LLaMA-3 models, released by Meta, were used as pretrained base models. Due to limited computational resources, the 13B LLaMA-2 model and the 8B LLaMA-3 model were selected for fine-tuning.
Low-Rank Adaptation of LLMs
Parameter-efficient fine-tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA), were employed to fine-tune the models efficiently. LoRA reduces computational requirements by adding low-rank matrices to the pretrained model parameters. The quantized LoRA (QLoRA) algorithm further enhances efficiency by converting models into low-precision formats and using paged optimizers to manage memory spikes during training.
Experimental Design
Training Details
The base LLaMA models were fine-tuned using QLoRA on two NVIDIA A6000 GPUs. The input sequences for patient case summarization and physician letter generation were set to 1500 and 2000 tokens, respectively. The LoRA rank was set to 32, with a scaling factor of 64 and a dropout rate of 0.05. The models were fine-tuned for 500 and 15,000 iteration steps, respectively, with the 8-bit paged Adamw optimizer.
Evaluation Metrics
The performance of the fine-tuned models was evaluated using ROUGE scores and a multidimensional expert rating by five physicians. ROUGE scores measure the similarity between model-generated text and reference text, while the expert rating assessed correctness, comprehensiveness, clinic-specific style, and practicality on a 4-point scale.
Results and Analysis
Summary Report Generation Task
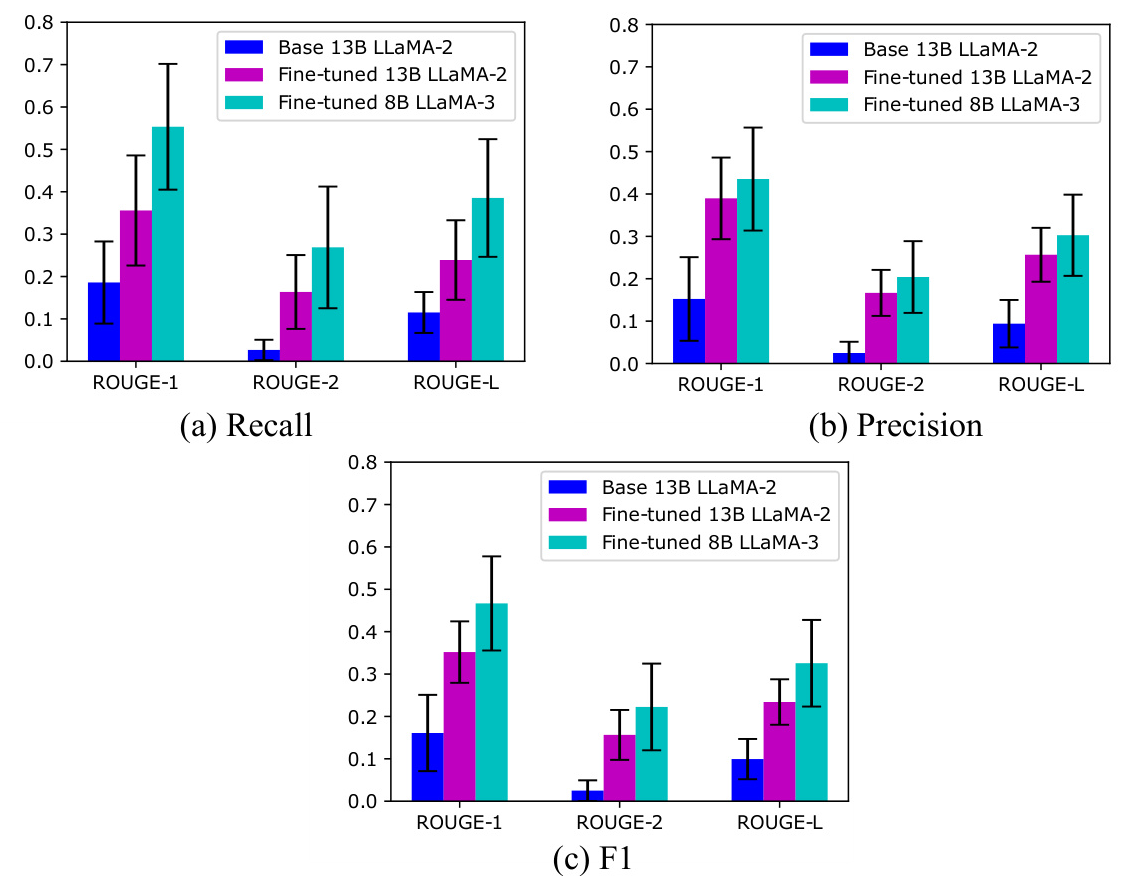
The fine-tuned LLaMA-2 and LLaMA-3 models provided relevant summaries of patient cases, with significant improvements in ROUGE scores compared to the base models. The fine-tuned 8B LLaMA-3 model outperformed the 13B LLaMA-2 model, despite having fewer parameters.


Physician Letter Generation
The fine-tuned 8B LLaMA-3 model was used for generating physician letters. The generated letters were evaluated by five physicians, receiving average scores of 2.96, 2.84, 3.29, and 3.44 for correctness, comprehensiveness, clinic-specific style, and practicality, respectively. The model successfully learned institution-specific styles and content, as demonstrated in the case examples.


Case Analysis
Case #1
The model correctly generated salutations, diagnosis, treatment history, and recommended treatment, demonstrating its ability to learn from local fine-tuning.


Case #2 and Case #9
The model showed limitations in generating detailed content beyond the provided input data, highlighting the need for careful physician review and correction.



Overall Conclusion
The study demonstrates that fine-tuning a local LLaMA-3 model using QLoRA is an efficient method for generating physician letters in radiation oncology while preserving data privacy. The fine-tuned model effectively learned institution-specific information and provided substantial practical value in assisting physicians with letter generation. However, careful review and correction by physicians remain essential to ensure accuracy and completeness. This approach offers a promising solution for integrating AI into clinical practice, enhancing efficiency, and maintaining patient data security.



