





Authors:
Yanjie Dong、Xiaoyi Fan、Fangxin Wang、Chengming Li、Victor C. M. Leung、Xiping Hu
Paper:
https://arxiv.org/abs/2408.10691
Introduction
Since the introduction of GPT-2 in 2019, large language models (LLMs) have evolved from specialized tools to versatile foundation models. These models exhibit impressive zero-shot capabilities, enabling them to perform tasks such as text generation, machine translation, and question answering without specific training for those tasks. However, fine-tuning these models on local datasets and deploying them efficiently remains a significant challenge due to their substantial computational and storage requirements.
The traditional fine-tuning techniques using first-order optimizers demand substantial GPU memory, often exceeding the capacity of mainstream hardware. This has led to the exploration of memory-efficient methods and model compression techniques to reduce energy consumption, operational costs, and environmental impact. This paper provides a comprehensive overview of prevalent memory-efficient fine-tuning methods and model compression techniques for deploying LLMs over network edges.
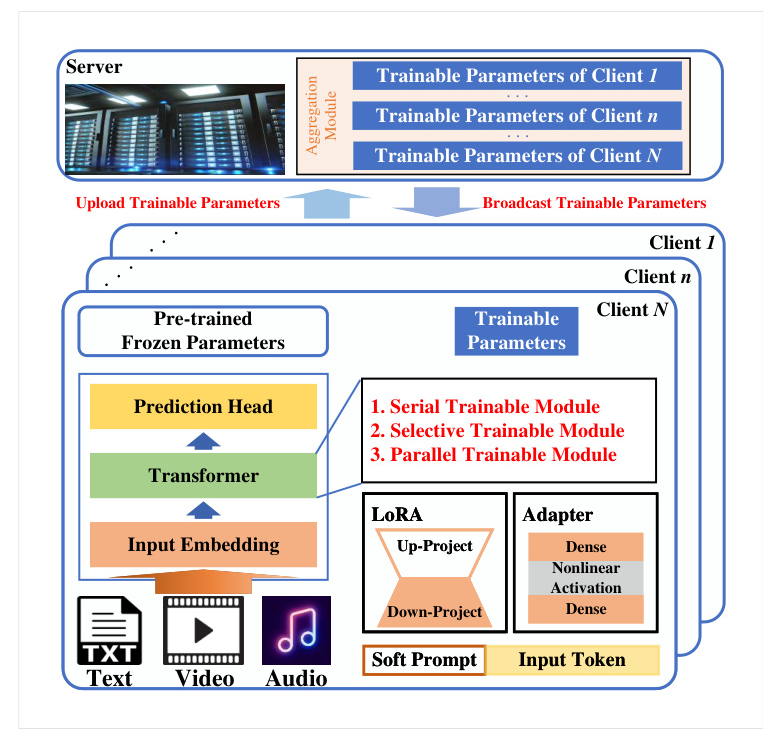
Parameter-Efficient Fine-Tuning in DLNoE
Parameter-Efficient Fine-Tuning (PEFT) techniques have emerged as critical methods for adapting LLMs to network edges with limited computational power and storage volume. These techniques modify or introduce only a small portion of the model weights, keeping the rest of the model frozen, thereby reducing computational and communication requirements.
Parallel PEFT in DLNoE
The Federated Instruction-Tuning (FedIT) framework introduces a parallel low-rank adaptation (LoRA) trainable module to all dense layers of the target LLM. This significantly reduces the number of trainable parameters, decreasing computational and communication overheads. FedIT also handles heterogeneous instruction data, enhancing the generalization capability of fine-tuned LLMs.
Serial PEFT in DLNoE
The Federated Parameter-Efficient Prompt Tuning with Adaptive Optimization (FedPepTAO) framework addresses the shortcomings of vanilla soft-prompt PEFT techniques. It selectively updates a subset of prompt parameters based on the eigenvalues of the Hessian matrix, optimizing communication efficiency without performance loss. The adaptive optimization technique handles client drift due to non-independent or non-identically distributed data.
Hybrid PEFT in DLNoE
The FedPETuning framework integrates multiple PEFT techniques (parallel, serial, and selective) into the DLNoE. It ensures that only lightweight weights are exchanged between clients and the server during training, addressing communication overhead and local computational resource constraints. The framework is adaptable to diverse DLNoE scenarios, maintaining performance while reducing communication overhead.


Memory-Efficient Full Fine-Tuning in DLNoE
When advanced system-on-chips cannot support the backward propagation (BP) operation, zeroth-order (ZO) optimizers are developed to estimate gradients using only function evaluations, avoiding the need for BP.
Memory-Efficient Full Fine-Tuning on a Single Client
The MeZO optimizer adapts the classical ZO-SGD to operate in-place, matching the memory footprint of inference. This allows fine-tuning of models with billions of parameters using the same memory required for inference. The MeZO can fine-tune a 30B model on a single 80GB GPU, significantly reducing memory requirements compared to traditional methods.
Communication and Memory Efficiency in DLNoE
The FedKSeed algorithm extends MeZO to the federated learning framework, reducing communication costs by allowing clients to exchange only a few random seeds and corresponding scalar gradients per iteration. This approach maintains data privacy while leveraging abundant client data.

Integration of PEFT and MEF2T
The FwdLLM framework integrates BP-free training with PEFT techniques, dynamically controlling global perturbation size and employing discriminative perturbation sampling. This balances model convergence rate and computational cost, enabling efficient and scalable fine-tuning on computation- and memory-constrained clients.
Case Study of MEF2T in DLNoE
A case study evaluates the impact of the number of seeds on model performance when using MEF2T in DLNoE. The results show that the number of seeds has little effect on Rouge-L F1 scores, motivating the use of a small number of seeds to expedite the fine-tuning process.

Compressing LLMs for Edge Devices
Deploying fine-tuned LLMs on edge devices requires model compression techniques to reduce memory requirements. Traditional methods like pruning, knowledge distillation, and quantization often require additional retraining to recover accuracy. Resource-efficient compression methods are needed to reduce data demand and retraining duration.
Compression-and-Train
The Generalized Knowledge Distillation (GKD) algorithm addresses distribution mismatch in traditional knowledge distillation methods. It uses reverse KL divergence or generalized Jensen-Shannon divergence and on-policy data generated by the student model, guided by teacher feedback. This approach improves model performance across diverse tasks.
Compression-Then-Train
The LLM-Pruner reduces the scale of LLMs based on gradient information, preserving the capability to handle various tasks without requiring the original training dataset and long retraining durations. It involves discovery, estimation, and recovery stages to effectively reduce model size and computational demands.
One-Shot Compression
One-shot model compression methods like OPTQ and SparseGPT achieve high accuracy and efficiency without retraining. OPTQ quantizes weights layer-by-layer, minimizing quantization error, while SparseGPT prunes neurons and adjusts remaining weights to minimize mean-squared error between original and pruned layers.
Conclusions and Future Research Directions
The demand for computational power and storage volume for LLMs necessitates memory-efficient fine-tuning methods and model compression to scale their accessibility to terminal clients. This paper provides an overview of recent advances in PEFT, MEF2T, and model compression, highlighting their main contributions. Future research directions include developing privacy-preserving fine-tuning algorithms and designing initializers for bottleneck modules to handle data heterogeneity.



