





Authors:
Jianian Gong、Nachuan Duan、Ziheng Tao、Zhaohui Gong、Yuan Yuan、Minlie Huang
Paper:
https://arxiv.org/abs/2408.10495
Introduction
The rapid advancement of large language models (LLMs) such as GPT-4 has revolutionized the landscape of software engineering, positioning these models at the core of modern development practices. As we anticipate these models to evolve into the primary and trustworthy tools used in software development, ensuring the security of the code they produce becomes paramount. This paper presents a systematic investigation into LLMs’ inherent potential to generate code with fewer vulnerabilities. Specifically, the study focuses on GPT-3.5 and GPT-4’s capability to identify and repair vulnerabilities in the code generated by four popular LLMs, including themselves (GPT-3.5, GPT-4, Code Llama, and CodeGeeX2).
Related Work
Previous studies have revealed that although large language models are capable of generating functionally correct code, they are not free of security vulnerabilities. This is primarily because their training sets contain real-world insecure code. Therefore, raw LLM-generated source code cannot be trusted to be deployed in security-sensitive scenarios. The increasingly significant role of LLMs in software engineering, coupled with disturbing vulnerabilities in the code they generate, compels us to explore methods for producing safer code with LLMs.
Research Methodology
Research Questions
The study aims to answer the following research questions (RQs):
- RQ1: How do LLMs perform when generating Python code in security-sensitive scenarios?
- RQ2: How effective are LLMs in identifying LLM-generated code vulnerabilities?
- RQ3: How effective are LLMs in repairing LLM-generated code vulnerabilities?
- RQ4: How effective is an iterative strategy in improving LLMs’ repair capability?
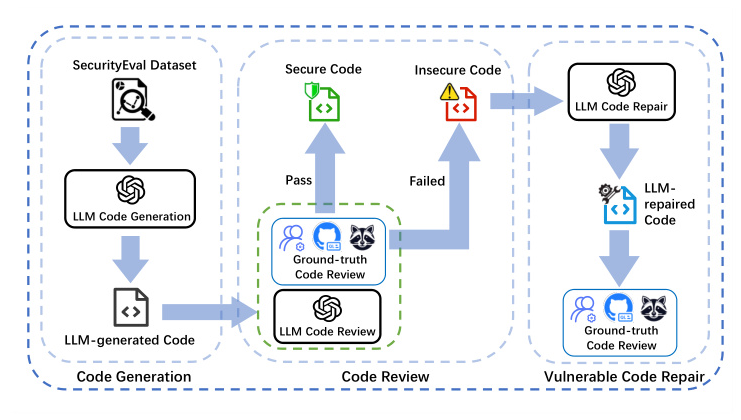
Methodology for RQ1~RQ3
The overall workflow of RQ1~RQ3 goes in a pipeline fashion. The procedure aims to assess LLMs’ end-to-end capability to generate secure code. In RQ1, the models are prompted to complete code generation tasks. The generated code is then reviewed to determine whether it contains specific CWE vulnerabilities. In RQ2, the models are prompted to inspect the generated code for vulnerabilities. In RQ3, the vulnerable code identified in RQ1 is provided to the models for repair.


Algorithm for RQ4
To exploit the potential of LLMs in producing safer code, an iterative repair algorithm is designed for RQ4. The algorithm takes code generation tasks as input, generates code, scans for vulnerabilities, and iteratively repairs the code until it is secure or the maximum number of iterations is reached.

Experimental Design
Dataset
SecurityEval is a dataset dedicated to measuring the security of machine learning-based code generation techniques. It contains 121 code generation tasks in Python, all exposed to the potential risk of a certain CWE. The dataset covers 69 CWEs and provides an example vulnerable solution for each task.

Studied Large Language Models
The study focuses on four LLMs: GPT-3.5, GPT-4, Code Llama, and CodeGeeX2. These models are chosen for their popularity and performance in code generation tasks.
Prompts and Parameters
The prompts used in the study are designed for code generation, vulnerability detection, and vulnerability repair. Default parameters of the models are used to balance creativity and reproducibility.
Experimental Platform
All LLMs are accessed through remote APIs. Semantic code analysis tools (CodeQL and Bandit) are run locally to review the generated and repaired code.
Results and Analysis
RQ1: How Do LLMs Perform When Generating Python Code in Security-Sensitive Scenarios?
The study reveals that all four models performed poorly in generating secure code, with an average of 76.2% of the generated code being insecure. This highlights a significant challenge in using current LLMs for secure code generation.

RQ2: How Effective Are LLMs in Identifying LLM-Generated Code Vulnerabilities?
GPT-3.5 achieves 43.6% accuracy, while GPT-4 achieves 74.6% accuracy in detecting vulnerabilities. However, both models have high false positive rates, indicating their unreliability in vulnerability detection.

RQ3: How Effective Are LLMs in Repairing LLM-Generated Code Vulnerabilities?
GPT-3.5 and GPT-4 can repair a range of LLM-generated insecure code when provided with a description of the CWE type. GPT-4 performs significantly better than GPT-3.5, with nearly twice the success rate of repair.

RQ4: How Effective Is an Iterative Strategy in Improving LLMs’ Repair Capability?
The iterative repair process significantly improves the success rates of repair. On average, GPT-3.5 successfully repaired 65.9% of the vulnerable code snippets it generated, while GPT-4 repaired 85.5% of its own generated vulnerable code.

Overall Conclusion
The study reveals several key findings:
- Large language models tend to generate insecure code in security-critical programming tasks due to a lack of scenario-relevant awareness of potential risks.
- Large language models such as GPT-3.5 and GPT-4 are not capable of accurately identifying vulnerabilities in the source code they produce.
- Advanced LLMs can achieve up to a 60% success rate in repairing insecure code generated by other LLMs but perform poorly when repairing self-produced code.
- A feedback-driven self-iterative repair approach significantly enhances the security of LLM-generated code.
While future large language models have the potential to produce secure code in an end-to-end fashion, current models require assistance from established tools like semantic code analysis engines to accurately fix vulnerable code.


