





Authors:
Yihang Wang、Xu Huang、Bowen Tian、Yixing Fan、Jiafeng Guo
Paper:
https://arxiv.org/abs/2408.10497
Introduction
In recent years, the rapid development of generative large language models (LLMs) has revolutionized many traditional technologies. These models, such as ChatGPT, have demonstrated remarkable success in various industrial tasks by leveraging rich contextual information. Techniques like In-Context Learning (ICL), Retrieval-Augmented Generation (RAG), and the use of agents have been instrumental in enabling these models to understand and generate contextually relevant content, addressing complex problems through multi-turn dialogues.
However, as tasks become increasingly complex, the required context length for ICL also grows, leading to two significant challenges:
1. Higher inference costs, especially when using closed-source APIs.
2. Introduction of task-irrelevant information, exacerbating the “lost in the middle” problem, where the model’s performance deteriorates as it struggles to maintain focus on the most relevant parts of the context.
To mitigate these challenges, context compression has emerged as a promising approach. This strategy leverages the inherent redundancy and repetition in natural language, aiming to distill the context to its most informative elements while minimizing the loss of crucial information.
Related Work
Attention Mechanism
The Attention Mechanism, introduced by Vaswani et al. (2017), is crucial in today’s machine learning landscape. It is widely used in various fields, including image generation, image recognition, and language processing. The attention mechanism transforms an input sequence into query (Q), key (K), and value (V) matrices through linear projections, and the attention matrix is computed as follows:
[ A = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) ]
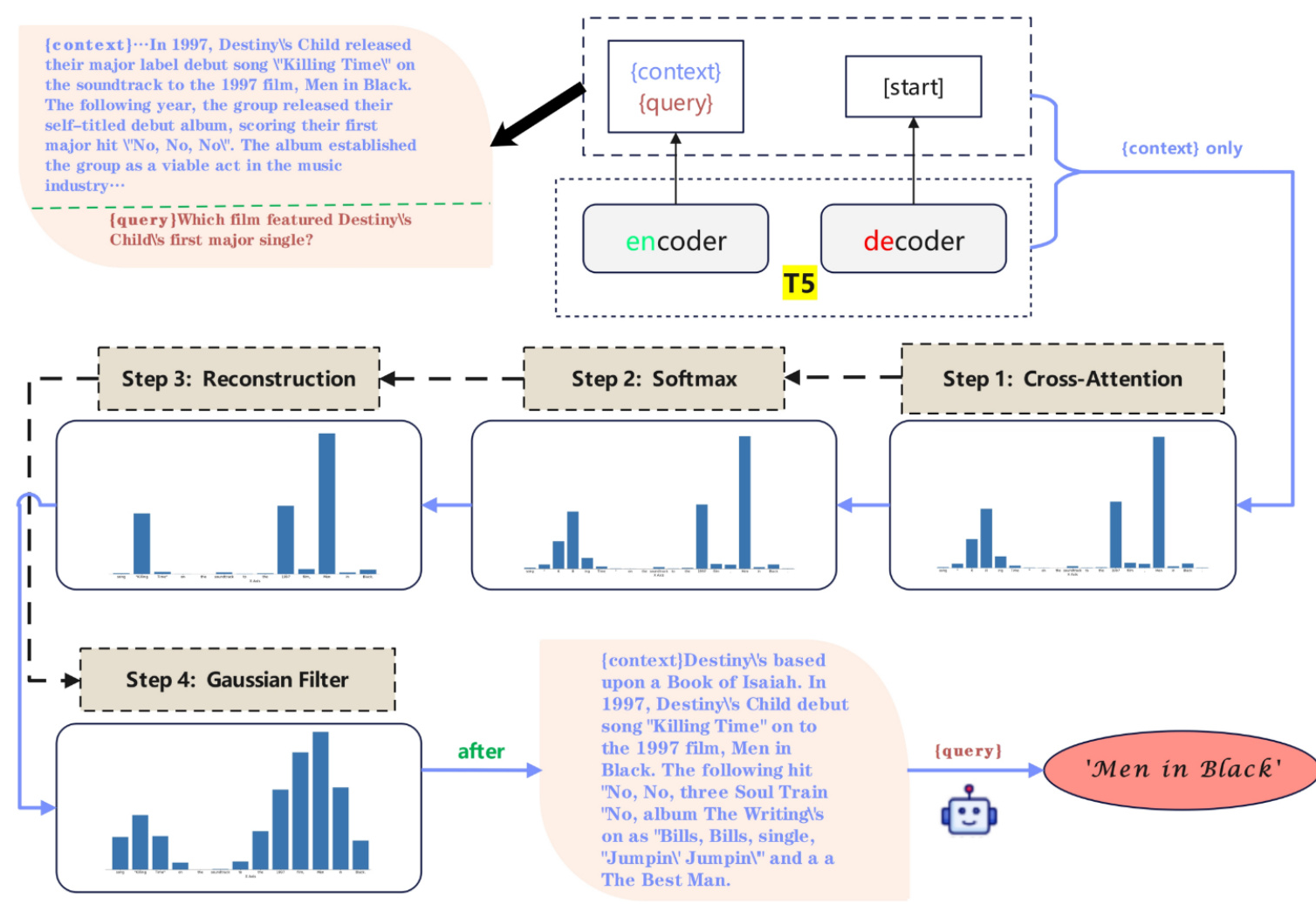
Cross-attention, a variant of the attention mechanism, is often used to exchange information between different types of data, such as between image and text modalities or for translation between different languages. In our work, we use the T5 model, with the prompt and query as the KV pair, and the first token of the answer as Q, to perform cross-attention and determine which tokens in the prompt are most important.
Context Compression
Generative LLMs have achieved strong performance across various tasks but encounter computational challenges when processing long documents and extended conversations due to increased token counts and context truncation. ICL helps mitigate some of these issues by providing task-relevant context directly, reducing the need for specific task Supervised Fine-Tuning (SFT) and lowering costs. However, ICL also increases token numbers and inference costs.
The Selective Context method was developed to address these challenges by compressing input context through the removal of redundant information. This approach reduces token numbers and inference costs while mitigating the “lost in the middle” problem associated with long contexts. The LLMLingua series enhances context compression by optimizing context selection strategies and introducing advanced memory network structures.
QUITO introduces self-attention as a metric for context compression, diverging from traditional methods that rely on perplexity or self-information. However, in the self-attention module of QUITO, the query, key, and value are trained together, which may lead to information mixing between the input and output. In contrast, we employ cross-attention in an encoder-decoder architecture, where the input and output are separated.
Research Methodology
Theorem
The information bottleneck (IB) theory is a simplistic concept: when facing a task, one should try to accomplish it using minimal information. In our case, we want to compress the context while retaining the accuracy of the output answer, making it well-suited for modeling using IB theory. Our objective can be formulated as follows:
[ \operatorname*{min}_{\bar{X}} IB = I(\bar{X};X|Q) – \beta I(\bar{X};Y|Q) ]
where ( \bar{X} ) stands for compressed context, ( Q ) stands for query, and ( Y ) stands for output. ( X = x_1 x_2 x_3 \ldots x_n ), in which ( x_i ) is the ( i )-th token, and ( \beta ) is related to the compressed ratio. The first term serves to enhance efficiency, while the second term serves to retain as much useful information as possible to enable the LLM to generate target outputs.
Algorithm
In practice, we use the word as the smallest unit of compression, following the work of previous researchers. We utilize the T5 model’s cross-attention mechanism to evaluate the importance of each word in the context relative to a given query. The procedure is as follows:
- Concatenation of Context and Query: The context and query are concatenated to form a single input sequence. This sequence is fed into the T5 model’s encoder to generate a feature representation.
- Encoding and Decoding: Leveraging the T5 model’s encoder-decoder architecture, the concatenated input is encoded, and the model begins decoding from a start token [start]. During this decoding process, the model generates output tokens while computing cross-attention scores that highlight the importance of each token in the context with respect to the generated output.
- Get the Cross-Attention Scores: Cross-attention weights from the final layer are extracted, specifically focusing on tokens corresponding to the context. The weights from each attention head are averaged to obtain a more robust representation. These averaged weights are then normalized using a softmax function to produce attention-based importance scores for each token.
- Smoothing with Gaussian Filter: To ensure that tokens adjacent to those with high attention scores also receive appropriate attention, we apply a Gaussian filter to the attention scores. This smoothing process helps to distribute the attention more evenly across nearby tokens, enhancing the model’s ability to capture relevant context.
- Reconstruction Based on Word Importance: The reconstructed context is derived by considering the importance of each word. The ‘reconstruct’ function groups tokens into words and then re-evaluates their importance using the smoothed attention scores. This approach ensures that the semantic integrity of the text is preserved during compression.
- Context Compression: Finally, the context is compressed by selectively retaining words with the highest importance scores. The compression ratio can be adjusted to control the level of detail retained in the compressed context, balancing between context size and information retention.


Experimental Design
Main Experiment: Context Compression on Standard QA Datasets
Datasets and Models
For our main experiment, we utilized the FLAN-T5-small model as the compression model. We conducted this experiment on four widely used QA datasets: CoQA, Quoref, DROP, and SQuAD. This experiment aimed to evaluate the effectiveness of our context compression technique on both accuracy and information retention.
- For CoQA and Quoref, we assessed the accuracy of question-answering models (LongChat-13B-16k and LLaMA3-8B-Instruct) before and after context compression.
- For DROP and SQuAD, we focused on whether key information (i.e., the source of the answer) was preserved after compression, using Exact Match (EM) as the evaluation metric.
Baseline
We compared against the following context compression baselines:
1. Selective Context: Uses GPT-2 to retain context segments based on self-information.
2. LLMLingua: Employs Llama-2-7b with dynamic compression driven by context PPL.
3. LongLLMLingua: Extends LLMLingua for longer contexts, also using Llama-2-7b.
4. LLMLingua2: Utilizes XLM-RoBERTa-large, introducing data distillation for enhanced compression.
5. QUITO: Applies Qwen2-0.5B-Instruct with attention mechanisms to selectively retain query-relevant context.
Implementation Details
We first evaluated model accuracy using the original context and with no context, assessing the models’ ability to summarize with full information and rely on prior knowledge. We then tested the five baseline methods and our approach at compression ratios of 0.75, 0.50, and 0.25, measuring accuracy with the compressed context. For DROP and SQuAD, where the original text always contains the correct answer (EM = 1), we evaluated whether the correct answer remained in the compressed context under the same compression ratios, using the EM score as the metric.

Supplementary Experiment: Addressing Long Texts with Chunking Strategies
Datasets and Models
As a supplementary experiment, we focused on datasets with particularly long texts, where traditional models often struggle with the “lost in the middle” phenomenon, leading to reduced accuracy. We selected subsets from LongBench to evaluate our method, focusing on three datasets known for their long contexts: 2WikiMultiHopQA, HotpotQA, and MuSiQue.
Approach
In this experiment, we compared the performance of LLMLingua2 and our proposed method. Both methods employed a chunking strategy, dividing the context into 512-token segments. We tested two distinct strategies:
1. Concatenating each chunk with the query before compression.
2. Calculating attention scores for each chunk with the query, recombining the attention arrays, and then performing compression.
Objective
This supplementary experiment was designed to evaluate how well each method mitigates the “lost in the middle” issue and preserves relevant information across the chunks, thereby supporting the findings from our main experiment.
Results and Analysis
Main Experiment Analysis
The experimental results demonstrate that our proposed QUITO-X consistently outperforms existing methods, including Selective-Context, LLMLingua, LongLLMLingua, LLMLingua2, and QUITO, across different compression ratios on the Quoref and CoQA datasets. Notably, our method shows superior performance even at higher compression ratios, where significant portions of the context are removed. This indicates the robustness and effectiveness of our approach in retaining critical information despite reduced context sizes.
An interesting observation is that in some cases, our method not only retains information effectively under compression but also surpasses the performance of the original uncompressed context. This could be attributed to the method’s ability to focus on the most relevant portions of the context, thereby reducing noise and improving model predictions.
The information retention graphs for the SQuAD and DROP datasets further support these findings. Our method maintains a higher retention of information (measured by Exact Match scores) across all compression ratios. As the ratio decreases, and more context is compressed, our method’s advantage becomes more pronounced compared to other approaches. This demonstrates that our compression strategy is particularly effective in scenarios where only a limited amount of context can be preserved, thus ensuring that the most critical information is retained.

Supplementary Experiment Analysis
The supplementary experiments on long-text datasets validate the efficacy of our proposed strategies. Notably, our methods consistently outperform the baseline (LLMLingua2) across various compression ratios.
In 2WikiMultiHopQA, Strategy 1 achieves the highest performance at a 0.75 compression ratio, while Strategy 2 excels at a 0.50 ratio, showcasing the adaptability of our approach to different compression levels. For HotpotQA, both strategies significantly enhance performance as the compression ratio decreases, with Strategy 2 reaching the highest scores at 0.50 and 0.25 ratios. Finally, in MuSiQue, Strategy 2 outperforms all others at lower compression ratios, demonstrating robust information retention even with aggressive compression.
These results emphasize the effectiveness of our long-context handling strategies, particularly in scenarios where the context needs to be significantly compressed while maintaining critical information.

Overall Conclusion
In this paper, we endeavor to address the challenge of query-based context compression in Retrieval-Augmented Generation (RAG) scenarios. Leveraging the information bottleneck theory, we meticulously analyzed the properties required for metrics that measure token importance. Our approach employs cross-attention and achieves state-of-the-art (SOTA) results across several commonly used datasets. Notably, our method demonstrates superior performance on long texts, sometimes even outperforming the original, which may be attributed to the redundancy inherent in natural language. Our model significantly surpasses strong baselines in both inference latency and performance. The effectiveness of our chunking strategy for longer texts, as well as the reasons behind the exceptional performance of cross-attention, are left for future exploration.



