





Authors:
Yuyang Ye、Zhi Zheng、Yishan Shen、Tianshu Wang、Hengruo Zhang、Peijun Zhu、Runlong Yu、Kai Zhang、Hui Xiong
Paper:
https://arxiv.org/abs/2408.09698
Introduction
The rapid advancements in Large Language Models (LLMs) have significantly bolstered the capabilities of Recommendation Systems (RSs). These models have demonstrated exceptional proficiency in understanding and summarizing complex user preferences, thereby enhancing personalization and accuracy in recommendations. However, the traditional LLM-based recommendation paradigm primarily relies on textual data, which limits its effectiveness in multimodal contexts where data from images, text, and other sources are integrated. This paper introduces the Multimodal Large Language Model-enhanced Sequential Multimodal Recommendation (MLLM-MSR) model, which aims to address these challenges by leveraging Multimodal Large Language Models (MLLMs) to enhance sequential multimodal recommendations.
Related Work
Multimodal Sequential Recommendation
Sequential Recommenders (SRs) have evolved from matrix-based models to sophisticated neural architectures. Early models like Factorizing Personalized Markov Chains (FPMC) combined matrix factorization with Markov chains to model sequential behavior. The transition to neural models began with GRU4Rec, which employed gated recurrent units for session-based recommendations. Subsequent models like SASRec and BERT4Rec utilized self-attention mechanisms and transformers, respectively, to handle long-term dependencies in user-item interactions.
In the realm of multimodal information-enhanced SRs, various fusion methods have been employed to integrate data from different sources. These methods are categorized into early, late, and hybrid fusion approaches, each offering unique advantages in enhancing the quality of recommendations by leveraging additional contextual information.
LLM for Recommendation
The integration of LLMs into recommendation systems has been significantly influenced by foundational models like BERT and GPT-3. These models have demonstrated the potential of LLMs in processing vast amounts of textual data to understand user behaviors deeply. Current LLM applications in recommendation systems are categorized into embeddings-based, token-based, and direct model applications. Additionally, there has been an emergence of multimodal LLM-based recommendation frameworks designed to handle scenarios involving multimodal information, thereby enhancing the accuracy and user experience of recommendation systems.
Research Methodology
Problem Definition
The Sequential Multimodal Recommendation problem involves predicting the probability of the next interacted item for a user based on their historical behavior sequence, which includes both textual and visual data. Formally, given a user ( u ) with a historical behavior sequence ( S_u ) and a candidate item ( I_c ), the objective is to predict the probability of the next interacted item ( I_{n+1} ) for the user ( u ).
Effectiveness of Multiple Images Summary
To address the challenges of processing multiple image inputs in MLLMs, the paper introduces an image summary approach that leverages MLLMs to convert and summarize image content. This approach was evaluated using the GRU4Rec model on real-world datasets, demonstrating that image summaries preserve necessary semantic information in sequential modeling.
Experimental Design
Multimodal User Preferences Inference
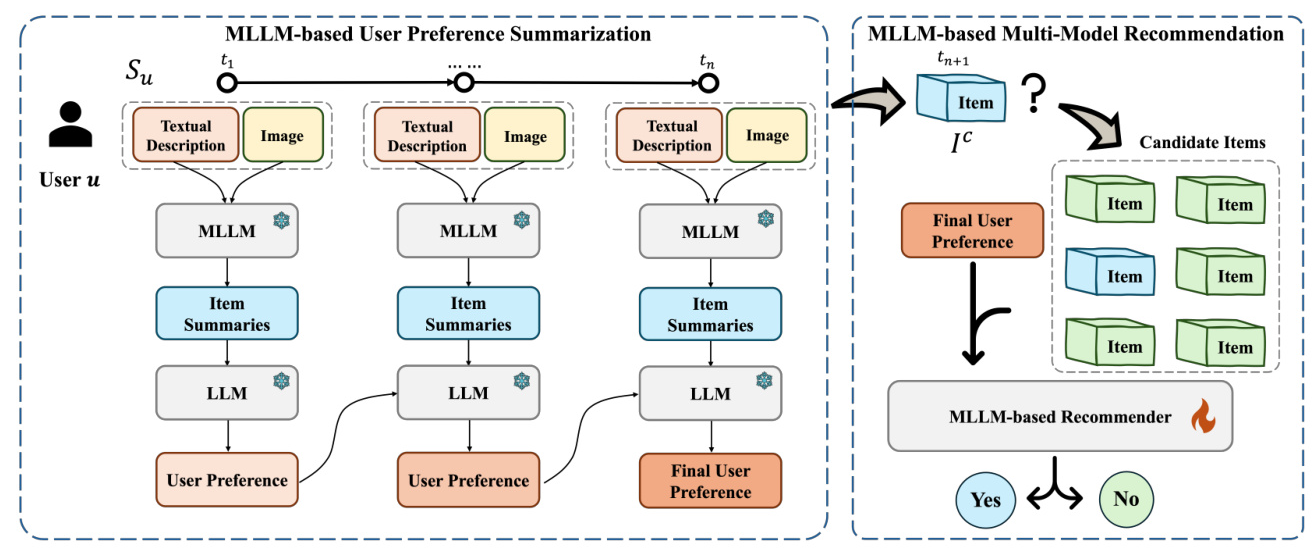
The proposed MLLM-MSR framework consists of two main components: Multimodal User Preferences Inference and Tuning MLLM-based Recommender. The Multimodal User Preferences Inference component employs MLLMs to transform visual and textual data of each item into cohesive textual descriptions. This is followed by a recurrent method to infer user preferences, capturing the temporal dynamics of these preferences.
Multimodal Item Summarization
The Multimodal Item Summarization approach simplifies the processing by summarizing multimodal information of images into unified textual descriptions. This is achieved by designing effective prompts to integrate the multimodal data of items, ensuring a thorough comprehension and detailed feature extraction from each modality.
Recurrent User Preference Inference
Inspired by Recurrent Neural Networks (RNNs), the method employs prompted sequence modeling to iteratively capture user preferences through interaction sequences. This segmentation enables the approach to dynamically represent user preferences, effectively overcoming the limitations of MLLMs in processing sequential and multimodal data.
Tuning MLLM-based Recommender
The fine-tuning process involves adjusting the model to minimize the discrepancy between predicted and actual user interactions. This is achieved through supervised fine-tuning (SFT) on an open-source MLLM, utilizing a carefully designed set of prompts that integrate enriched item data, inferred user preferences, and the ground-truth of user-item interactions.
Results and Analysis
Experimental Setup
The experimental evaluation utilized three open-source, real-world datasets from diverse recommendation system domains: Microlens Dataset, Amazon-Baby Dataset, and Amazon-Game Dataset. The datasets were preprocessed to ensure user history sequences met minimum length criteria, and negative sampling was implemented during training and evaluation.
Performance Analysis
The performance of the proposed MLLM-MSR model was compared with various baseline methods, including basic SR models, multimodal recommendation models, multimodal feature-enhanced SR models, and LLM-based SR models. The evaluation metrics included AUC, HR@5, and NDCG@5.
The results demonstrated that MLLM-MSR consistently outperformed all other methods in terms of both classification and ranking, underscoring the personalization accuracy of the recommendation system. The integration of multimodal and sequential processing capabilities was shown to be essential for optimal effectiveness in SR tasks.
Ablation Study
An ablation study was conducted to evaluate the individual contributions of certain components within the MLLM-MSR framework. Variants of MLLM-MSR were developed, each omitting specific components such as the recurrent method or image summarization. The results confirmed the essential roles of these key components in achieving superior performance.
Parameter Analysis
The optimal block size for the recurrent user preference inference component was analyzed, highlighting the importance of balancing block size to ensure efficient processing of sequential data. Additionally, the impact of context length on predictive performance was evaluated, demonstrating the importance of selecting a proper context length to maximize information utility without incurring unnecessary computational complexity.
Overall Conclusion
The Multimodal Large Language Model-enhanced Multimodal Sequential Recommendation (MLLM-MSR) model effectively leverages MLLMs for multimodal sequential recommendation. Through a novel two-stage user preference summarization process and the implementation of SFT techniques, MLLM-MSR showcases a robust ability to adapt to and predict dynamic user preferences across various datasets. The experimental results validate the outstanding performance of MLLM-MSR compared to existing methods, particularly in its adaptability to evolving preferences. This paper introduces an innovative use of MLLMs that enriches the recommendation process by integrating diverse modalities and enhances the personalization and accuracy of the recommendations, while providing added interpretability through detailed user preference analysis.
Illustrations:
-
The schematic framework of MLLM-MSR
!
-
An example of MLLM-based sequential recommendation
!
-
The statistics of datasets
!
-
The performance of different methods
!
-
The performance of MLLM-MSR and its variants
!
-
Performance of MLLM-MSR under different block sizes
!
-
Performance of MLLM-MSR under different user preference summary lengths
!



