





Authors:
Felipe Yáñez、Xiaoliang Luo、Omar Valerio Minero、Bradley C. Love
Paper:
https://arxiv.org/abs/2408.08083
Confidence-Weighted Integration of Human and Machine Judgments for Superior Decision-Making
Introduction
In today’s information-rich environments, the ability to process vast amounts of data is increasingly challenging for humans. Conversely, machine systems, particularly large language models (LLMs), can leverage extensive information resources and often achieve superhuman performance levels. This raises concerns about whether machines will replace human judgment in critical areas. One potential solution is forming human-machine teams where judgments from both humans and machines are integrated. This paper evaluates the potential of such teams in a knowledge-intensive task where LLMs surpass humans in predicting neuroscience study outcomes.
Key Conditions for Team Complementarity
For human-machine teams to outperform individual members, two key conditions must be met:
1. Calibration of Confidence: Higher confidence in judgments should correlate with greater accuracy.
2. Classification Diversity: Errors made by humans and machines should differ, ensuring diverse perspectives.
Previous work has explored these conditions in object recognition tasks, but the current study extends this to a knowledge-intensive task using a logistic regression framework for integrating confidence-weighted judgments from multiple team members.
Methods
Test Cases
The study utilized BrainBench, a benchmark comprising 100 test cases generated by GPT-4 from abstracts in the Journal of Neuroscience. Each test case includes an original abstract and an altered version, with minimal but significant changes that affect the study’s results. The task is to identify the correct study outcome by choosing between the original and altered abstracts.


Procedure for Human Participants
A total of 171 neuroscience experts participated in an online study, evaluating three out of the 100 test cases. Participants selected the version they believed to be the original and rated their confidence using a slider bar. After applying exclusion criteria, 503 observations were obtained.
Procedure for LLMs
The study considered Llama 2 chat models with 7B, 13B, and 70B weights. LLMs chose the version of the abstract with the lower perplexity (PPL), and confidence was calculated as the absolute difference in PPL between the original and altered versions.
Bayesian Combination Model
The Bayesian framework for human-machine complementarity was adapted to combine human and LLM judgments. The model generates correlated probability confidence scores for human and machine classifiers using a bivariate normal distribution. The predicted classifications and confidence ratings are then compared to actual human predictions and confidence ratings.
Logistic Combination Model
A logistic regression approach was introduced to combine judgments from any number of teammates. This model captures each teammate by a single predictor, with the magnitude of the predictor representing the teammate’s confidence and the sign determined by their choice. The fitted beta weight reflects the teammate’s accuracy and calibration.
Cross-Validation Procedure
A leave-one-out cross-validation (LOOCV) procedure was used to evaluate the model, providing the best bias-variance trade-off for small datasets. This procedure was repeated for all 100 test cases, yielding 503 predictions.
Results
Conditions for Effective Collaboration
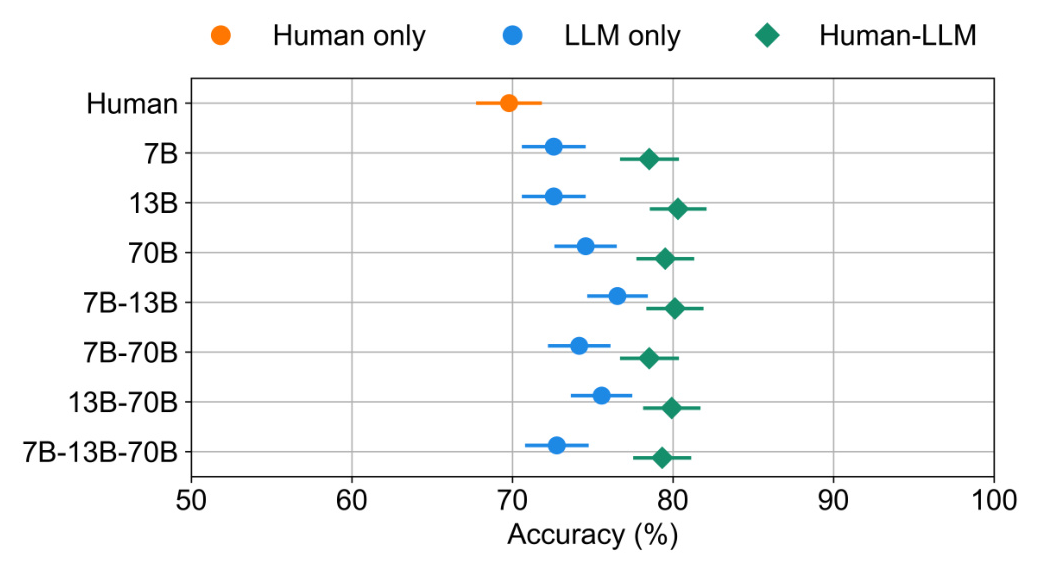
Both humans and LLMs were calibrated, with accuracy positively correlated with confidence. Diversity was also observed, as LLMs and humans differed in which test items led to errors. LLMs surpassed humans in accuracy, but the performance difference was small enough to consider human contributions beneficial.

Team Performance
All possible team combinations, ranging from individual teammates to a 4-way human-LLM team, were evaluated. Adding a human teammate to LLM-only teams consistently improved performance. The confidence-weighted logistic regression approach compared favorably to the Bayesian model, with the logistic model performing better and requiring significantly less computation time.


Discussion
The study demonstrated that human-LLM teams could achieve complementarity, with combined performance surpassing that of individual teammates. This was possible because confidence was well-calibrated and classification diversity was maintained among teammates. The logistic regression approach offered several advantages over the Bayesian model, including ease of implementation, fast runtime, and extendability.
While the study selected LLMs with superhuman performance, vastly superior teammates may hinder complementarity. However, for the foreseeable future, tasks will likely exist where humans and LLMs can effectively team. The method for integrating judgments is general and applies to any set of agents that can report their confidence.
Conclusion
This study explored the potential for human-LLM collaboration in predicting neuroscience outcomes. The confidence-weighted regression method effectively combined human and LLM judgments, demonstrating that humans can still add value to teams with superior machine performance. The findings suggest a promising future for human-machine collaborations in addressing complex challenges.
Data Availability
The human participant data and LLM perplexity scores used in this study are publicly available at BrainBench GitHub Repository.
Code Availability
All computer code associated with this work, including combination model implementations, team evaluations, and analyses, is publicly available at HAICO GitHub Repository.


