





Authors:
Xixi Wang、Zitian Wang、Jingtao Jiang、Lan Chen、Xiao Wang、Bo Jiang
Paper:
https://arxiv.org/abs/2408.08078
Introduction
Remote sensing image change detection is a critical task that involves identifying variable pixel-level regions between two images taken at different times. This task has numerous applications, including damage assessment, urban studies, ecosystem monitoring, agricultural surveying, and resource management. Despite the progress made in this field, challenges remain, especially in extreme scenarios.
Existing methods often rely on Convolutional Neural Networks (CNN) and Transformers to build their backbones for remote sensing image change detection. However, these methods typically focus on extracting multi-scale spatial features and often overlook the importance of temporal information and residual differences between image pairs. This paper introduces a novel Coarse-grained Temporal Mining Augmented (CTMA) framework to address these issues by leveraging motion cues, residual differences, and multi-scale information for improved change detection.
Related Work
Remote Sensing Image Change Detection
Remote sensing image change detection aims to detect changes in surface features by comparing images from different periods. Traditional methods often involve direct pairwise differences or splicing of images. Recent advancements include:
- VcT: Enables consistent representation between two images by mining spatial contextual information.
- A2Net: Recognizes changes by combining network-extracted features with progressive feature aggregation and supervised attention.
- CANet: Mines cross-image contextual information to enhance contextual representation within a single image.
However, specialized modeling of time has been neglected. Methods focusing on the time dimension include Recurrent Neural Networks (RNN) and attention-based methods. For example:
- ReCNN: Combines CNN and RNN to learn joint spectral-spatial-temporal feature representations.
- SiamCRNN: Uses a multilayer recurrent neural network stacked with Long Short-Term Memory (LSTM) units for change detection in multi-temporal images.
- Attention Mechanism: Improves performance by selectively focusing on important parts of the input data.
Spatial-Temporal Feature Learning
Spatial-Temporal feature learning captures dynamic behavior at different locations and times, providing comprehensive analysis. Notable works include:
- STLFL: An improved linear discriminant analysis technique for extracting high-level features of brain potentials.
- STF: Learns implicit neural representations from spatial-temporal coordinates and features.
- ESTF: Uses spatial and temporal Transformer networks for event-based action recognition.
Inspired by these works, this paper exploits spatial-temporal features to enhance change detection performance.
The Proposed Method
Overview
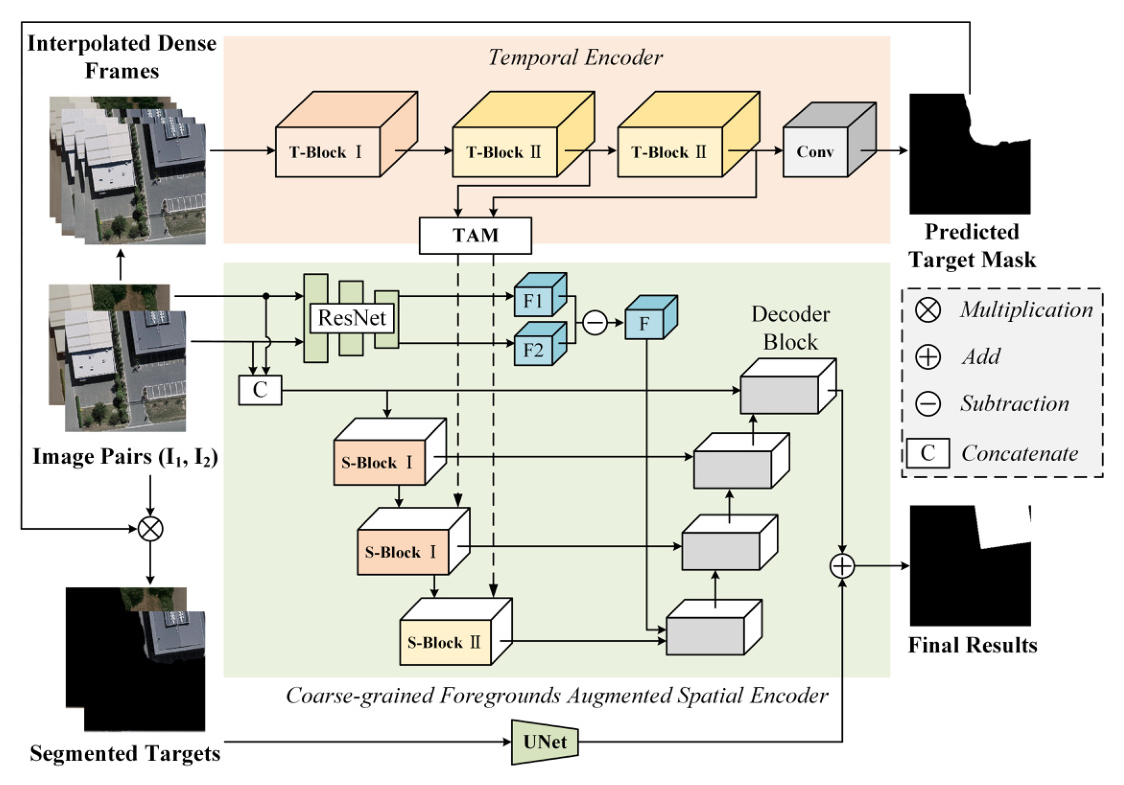
The CTMA framework consists of two main components: Temporal Encoder (TE) and Coarse-grained Foregrounds Augmented Spatial Encoder (CFA-SE). The process involves transforming bi-temporal images into video frame sequences, extracting temporal information, and generating a preliminary mask. The CFA-SE module integrates global and local information, motion cues, and mask-augmented strategies to produce accurate change detection results.
Temporal Encoder
The Temporal Encoder (TE) constructs a pseudo-video frame sequence from bi-temporal images using interpolation. This sequence enhances temporal information extraction. The TE consists of:
- T-Block I: A streamlined CNN for downsampling feature maps.
- T-Block II: Captures dynamic motion information using 3D ResBlock modules.
- Temporal Aggregation Module (TAM): Aggregates temporal and spatial information to produce a final feature representation.
Coarse-grained Foregrounds Augmented Spatial Encoder
The CFA-SE module combines global and local information using two complementary strategies:
- ResNet Branch: Extracts difference features between two images.
- Unet Branch: Combines channel dimensions of two images to extract change information.
The CFA-SE module also incorporates motion-augmented and mask-augmented strategies to enhance change detection accuracy.
Loss Function
The model uses a weighted Binary Cross-Entropy (BCE) loss for supervision and constraint. The total loss is a combination of the losses from the TE and CFA-SE modules, balanced by a hyper-parameter.
Experiments
Dataset Description
The experiments use three well-known remote sensing image datasets:
- SVCD: Consists of 11 pairs of remote sensing images with diverse spatial resolutions.
- LEVIR-CD: Designed for detecting building changes, consisting of 637 pairs of high-resolution images.
- WHU-CD: Focuses on building changes, consisting of two high-resolution aerial images.
Evaluation Metric
The performance is evaluated using Precision, Recall, and F1 scores. These metrics provide a comprehensive overview of the algorithm’s performance.
Implementation Details
The models are implemented using the PyTorch framework and trained on an Intel Xeon CPU and NVIDIA GeForce RTX 3090 GPU. Different learning rates and iterations are used for each dataset, with a step decay strategy to adjust the learning rate.
Comparison with State-of-the-Art Methods
The proposed method is compared with 10 state-of-the-art change detection models on three datasets. The results demonstrate significant improvements in accuracy, recall, and F1 scores, validating the effectiveness of the CTMA framework.


Ablation Study
The ablation study analyzes the contributions of different components, hyper-parameter settings, mask thresholds, and interpolated video frames. The results validate the rationale and necessity behind the design of each component in the CTMA method.

Visualization
Dense Video Frames
The interpolation algorithm generates a high-density frame sequence between two images, accurately modeling the progressive process of regional change.

Feature Maps
Feature map visualization on the WHU-CD dataset shows that each module focuses on different perspectives, capturing key change information in the images.

Change Detection Results
The visual experiment on the WHU-CD dataset demonstrates the effectiveness of the mask-augmented strategy and the CTMA model in improving change detection accuracy.

Limitation Analysis
The model faces challenges in scenarios with too many or too few regions of change. Future work will explore improving the temporal encoder’s accuracy and integrating global and local information more effectively.

Conclusion
The CTMA framework introduces a novel approach to remote sensing change detection by leveraging motion cues, residual differences, and multi-scale information. Extensive experiments validate its effectiveness, and the source code is made available for further research. Future work will focus on adopting lightweight networks and introducing semantic information perception modules to enhance performance.

Code:
https://github.com/event-ahu/ctm_remote_sensing_change_detection


