





Authors:
Tatjana Legler、Vinit Hegiste、Ahmed Anwar、Martin Ruskowski
Paper:
https://arxiv.org/abs/2408.09556
Introduction
Federated Learning (FL) is a collaborative learning approach that enables the training of models across multiple decentralized devices or servers holding local data samples, without exchanging their data. This is achieved by training multiple clients on their local data, computing model updates, and then aggregating them on a central server. By keeping data on local devices and only sharing model updates, FL minimizes the risk of data breaches and preserves user privacy. Techniques such as differential privacy and secure multi-party computation can be applied to further enhance security and privacy.
In addition to data sovereignty and privacy, employing an FL model circumvents the need for training a new model from scratch at each location, thereby enhancing energy efficiency. Due to its inherent distributed approach, FL is also better able to scale and respond to the failures of individual participants, making it more robust. Moreover, FL models are adept at generalizing across diverse scenarios, further underscoring their practical utility in distributed learning environments.
Since the global server lacks information about the clients, heterogeneity such as varying data distributions must be addressed differently than in the centralized case, leading to new challenges and therefore new approaches to solving them. Section 2 explores the various types of heterogeneity relevant in the context of FL. Subsequently, Section 3 identifies those that are particularly significant in the production environment and presents preliminary methods for addressing them.
State of the Art
First, some different types of heterogeneity are outlined briefly before exploring potential strategies to mitigate them, as these strategies frequently address multiple issues simultaneously. The literature lists various types that are not consistently defined or clearly differentiated, but they generally encompass the following categories:
Device Heterogeneity
Device heterogeneity in FL describes variations in computational power, network connectivity, and energy constraints or other hardware restrictions among participating clients. This type of heterogeneity challenges the uniform application of methods as clients range from powerful servers to resource-limited mobile and IoT devices. Clients with limited computational capabilities and energy constraints may not perform complex computations or frequent communications, impacting the overall learning process. Additionally, disparities in network connectivity can result in uneven data transmission rates, further complicating model synchronization and convergence.
Model Heterogeneity
Model heterogeneity occurs when clients use different model architectures, making it difficult to collaborate on a common model. Traditional FL methods are limited to training models with the same structures, as the simple aggregation of weights is only feasible when each weight has a counterpart in other clients. This hinders applicability in scenarios with different hardware and communication networks, where otherwise the models could be selected according to the available computing power. To overcome this challenge, much more sophisticated approaches than simple averaging are required and often are based on knowledge distillation.
Participation Heterogeneity
Participation heterogeneity can occur due to unstable internet connections, leading to some clients frequently joining and leaving the FL system, resulting in irregular participation. Depending on the volume of new data generated and the selection criteria for participation, some clients may not produce sufficient new data to qualify for participation in a communication round, resulting in a fluctuating frequency that can affect the consistency and convergence of the global model.
Data Heterogeneity
Data heterogeneity refers to variability in data distribution across clients that can lead to biases and affect model performance. Independent and Identically Distributed (IID) variables refer to a sequence of random variables that are statistically independent and follow the same underlying probability distribution. Although these assumptions are crucial for constructing and validating statistical models, real-world problems seldom exhibit true uniform distribution. There are different types of shifting the relationship between the input (features) and output data (labels):
- Covariate shift: Feature distribution skew
- Prior probability shift: Label distribution skew
- Concept shift: Same label, different features or vice versa
Systems that are actively deployed may encounter temporal shifts in newly generated data over time, diverging from the original training dataset, a phenomenon known as dataset shift. Therefore, considerations for continual learning become essential, such as incorporating strategies to learn new information while retaining previously acquired knowledge (i.e., preventing catastrophic forgetting). Additionally, there might be significant disparities in the volume of data that each client contributes to the global model, often referred to as quantity skew or “unbalancedness”. Data availability can vary greatly among clients, especially when initializing the system; some may have a large amount of historical data, while others may just have started with data acquisition.
Addressing Heterogeneity in a Production Environment
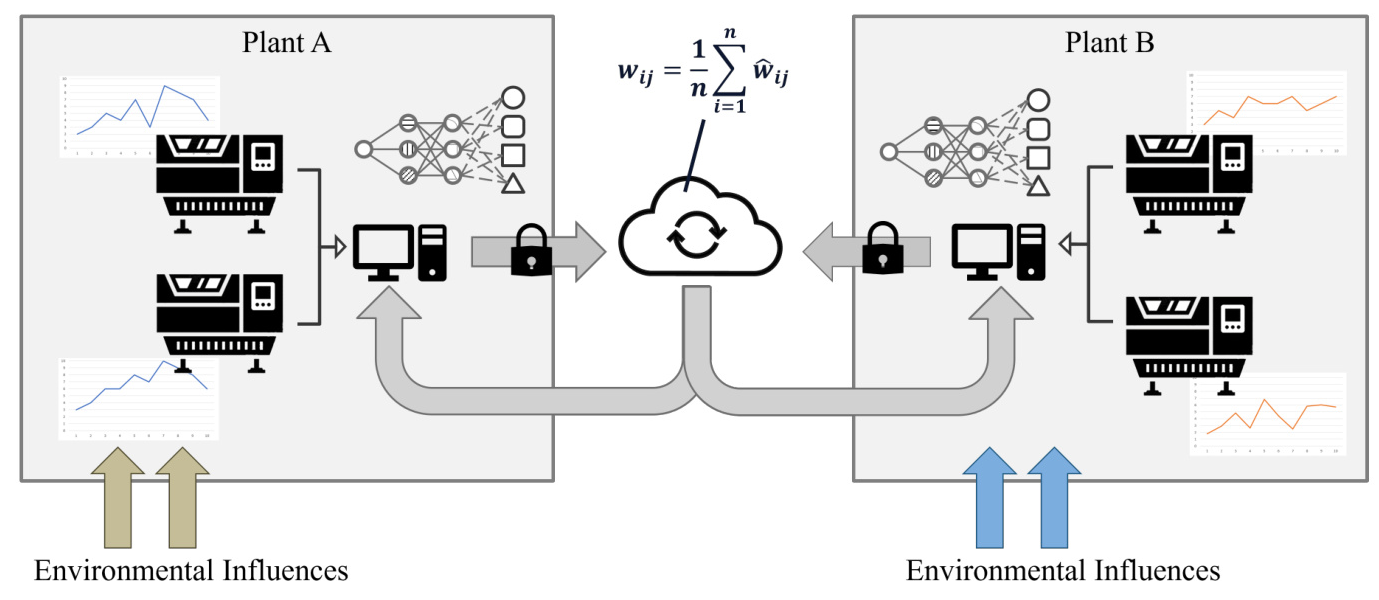
As described in preliminary work, we are looking at a shared production scenario in which companies can offer and request services. These services can include hardware services such as milling or drilling of parts, as well as software services like quality inspection solutions. While we assume that security aspects are covered through the use of a common platform, and none of the participants have malicious ulterior motives (e.g., planning data poisoning attacks), all the usual requirements for FL, such as not sharing any production data, still apply. Our assumptions correspond to a cross-silo setting, in which a small number of clients, e.g., from different organizations, tend to participate.
In contrast to cross-device, where system and model heterogeneity is also important, organizations or companies are likely to have sufficient computing resources and stable network connections. We therefore focus on data heterogeneity, e.g., handling highly non-IID data across different clients. The quality and statistical properties of data can significantly vary across clients due to diverse data collection methods, environments, or noise levels. Issues such as noisy data, which may contain errors, irrelevant information, or noise, can degrade model performance. Incomplete data, characterized by missing values or incomplete records, impacts the training process and the resultant model quality. Outliers or extreme values in the data can skew model training, particularly if they are not adequately addressed. Additionally, statistical heterogeneity manifests through variations in the mean and variance of features across clients, posing challenges in data standardization. Differences in correlation structures among different clients can further complicate the model’s ability to generalize effectively across diverse data landscapes.
A tiered (also: hierarchical or grouped) training approach, where clients with similar system capabilities will be grouped and perform a model aggregation within this group before a common model is sent to the next tier or global server. This can make particular sense if a company has many of its own machines or devices that already benefit from the participation of a (local) FL system. For example, a machine manufacturer supplies a customer with 100 machines, 20 of which are located in a hall. Although the machines are identical in construction and possibly produce the same part, there are always small deviations due to tolerances. This group of 20 machines will have similar environmental conditions and will probably also be equipped and maintained with the same or similar resources. Creating an FL system on their data alone will lead to a somewhat more stable and better-generalized model, but integrating the other groups will bring in more data diversity and thus unlock more of the potential.
Even more of the benefits of FL can be leveraged when the next step is to go beyond corporate boundaries. Many companies keep their production data heavily protected, including how many units of each product have been produced in a given time. The mere possibility of disclosing the number of machines to a competitor can be an exclusion criterion for participation in a system. In such a case, however, the company can implement FL at least within its own locations. Given that data protection regulations across national borders also affect information flow within a company, this allows various sites to be interconnected.
In a tier-based approach, the number of machines does not need to correlate with the number of FL clients, since even a single model update can be sent to the next higher tier. This has the advantage of disclosing even less information than traditional approaches when participating in the FL system. However, a disadvantage is that the central servers are unaware of the weighting of these model updates and may need to rely on alternative client-selection techniques (e.g., performance-/loss-based). A more robust aggregation can be achieved by modifying the standard FedAvg algorithm to account for data heterogeneity, such as by weighting updates based on data size or quality.
The initial approach to client selection was to sample a random fraction of clients for the next communication round. Current client selection techniques investigate which parameters can be used to determine the next participants. Rather than clustering clients into tiers as previously described, clustering approaches can also be employed to temporarily identify clusters and use them to select a client from each. This method ensures a more comprehensive coverage of the entire spectrum. Other approaches utilize training metrics such as local accuracy and training loss to identify and select the worst-performing clients, as these clients have the greatest potential for improvement and can therefore add the most to the global model.
The concept of Contribution-Based Selection refers to methods that utilize the impact of a client on the global model as a criterion for selecting clients in subsequent communication rounds. Generally speaking, the less information that needs to be shared in manufacturing, the better. Therefore, processes that operate solely based on weights or weight changes are preferred. As the production of defects is highly costly, every company strives to eliminate them as effectively as possible. This naturally results in a significant discrepancy in the dataset, as data with good parts is significantly more likely than data with errors. To counteract this class imbalance, various techniques can be used, especially locally at the client. These include artificially enlarging the data set and changing the weighting of the classes. Synthetic data generation can be used particularly in use cases where there is a high imbalance or where it would be very costly to collect new real data. It can be used to either fill in gaps in the real dataset, by creating new data points or augment the existing dataset to improve generalization. Furthermore, a local resampling of sparse data points can also mitigate the imbalance.
Conclusion
In conclusion, the exploration of heterogeneity in FL within a shared production environment has unveiled a complex landscape of challenges and potential solutions that could significantly advance the field of decentralized machine learning. Our review highlights the crucial need for robust, adaptive methods that can accommodate the unique constraints and characteristics of each client in the federated network. Strategies such as personalized modeling, advanced aggregation techniques, and thoughtful client selection have shown promise in mitigating the adverse effects of heterogeneity, thereby enhancing model performance and fairness across various settings.
Furthermore, the discussion emphasizes the importance of continued research into scalable, flexible solutions that can handle the dynamic and evolving nature of data and system architectures in real-world applications. By fostering a deeper understanding of these issues and continuously innovating on the solutions, the full potential of FL in industrial and commercial applications can be realized. In overcoming these barriers, FL will not only improve model accuracy and training efficiency but will also pave the way for more secure, privacy-preserving, and collaborative machine learning endeavors in globally distributed networks. This study sets the stage for future research directions, urging a sustained commitment to addressing these challenges within the landscape of Industrie 4.0 and beyond.


