





Authors:
Mengkang Hu、Tianxing Chen、Qiguang Chen、Yao Mu、Wenqi Shao、Ping Luo
Paper:
https://arxiv.org/abs/2408.09559
Introduction
In recent years, Large Language Models (LLMs) have demonstrated significant potential in various domains, including software development, robotic planning, and simulating human behavior. These LLM-based agents operate as interactive systems that process environmental observations to generate executable actions for target tasks. A critical component of these agents is their memory mechanism, which records historical experiences as sequences of action-observation pairs. Memory can be categorized into two types: cross-trial memory, accumulated across multiple attempts, and in-trial memory (working memory), accumulated within a single attempt.
While considerable research has optimized performance through cross-trial memory, the enhancement of agent performance through improved working memory utilization remains underexplored. Existing approaches often involve directly inputting entire historical action-observation pairs into LLMs, leading to redundancy in long-horizon tasks. Inspired by human problem-solving strategies, this paper introduces HIAGENT, a framework that leverages subgoals as memory chunks to manage the working memory of LLM-based agents hierarchically.
Related Work
Large Language Model-Based Agents
LLM-based agents have revolutionized the field of language agents, enabling them to tackle intricate challenges through a logical sequence of actions. Various applications of LLM-based agents include code generation, web browsing, robotics, tool use, reasoning, planning, and conducting research. However, most current research focuses on managing long-term memory, with limited exploration of working memory optimization.
Planning
Planning is a cornerstone of human intelligence, involving breaking down complex tasks into manageable sub-tasks, searching for potential solutions, and achieving desired goals. Previous works have proposed decomposing complex questions into a series of sub-questions, but these approaches often lead to context inefficiency. HIAGENT distinguishes itself by using subgoals as memory chunks to manage working memory hierarchically, bringing context efficiency and surpassing methods that rely solely on planning.
Memory
The memory module in LLM-based agents is analogous to the human memory system, responsible for encoding, storing, and retrieving information. Most current research focuses on managing long-term memory, while our study investigates how optimizing the management of working memory can enhance agent performance. Existing research has identified that LLMs encounter attention loss issues with lengthy texts, highlighting the need for more efficient working memory management.
Research Methodology
Overview
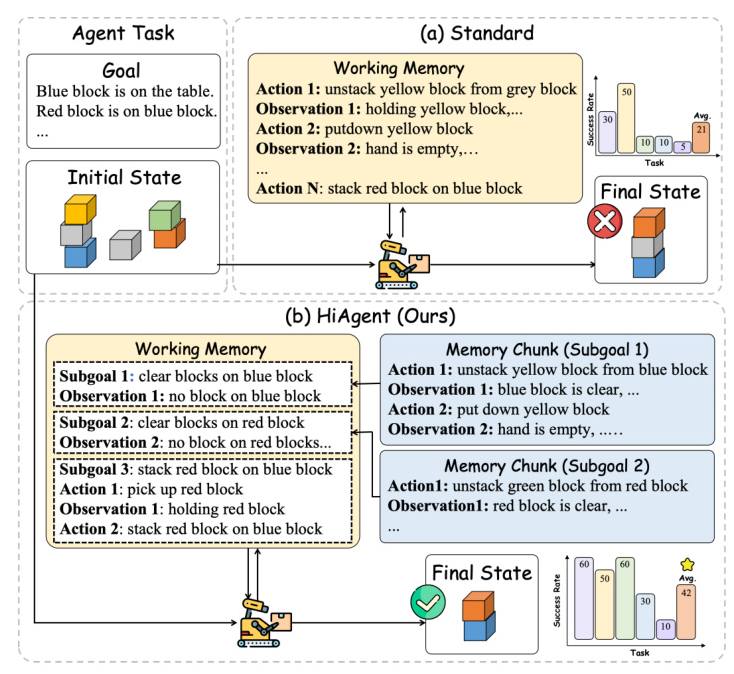
The core idea of HIAGENT is to employ subgoals for hierarchical management of working memory. The process of HIAGENT can be described as follows:
- Subgoal Formulation: Before generating specific grounded actions, the LLM is prompted to formulate a subgoal. Each subgoal serves as a milestone within the overall task.
- Action Generation: The LLM generates precise actions to accomplish the subgoal.
- Observation Summarization: Upon fulfilling a subgoal, the corresponding action-observation pairs are synthesized into a summarized observation. The detailed action-observation pairs are obscured, and only the summarized observation is retained in the working memory.
- Trajectory Retrieval: A retrieval module facilitates flexible memory management by allowing the agent to access detailed historical data on-demand without consistently carrying the full context.
Subgoal-Based Hierarchical Working Memory
At each time step, the LLM can either generate the next action for the current subgoal or generate a new subgoal when the existing subgoal has been accomplished. For the current subgoal, the agent retains all action-observation pairs, providing a detailed context for immediate decision-making. For past subgoals, only a summarized version of the observations is kept. This subgoal-based hierarchical management approach is deeply motivated by cognitive science principles, drawing parallels with human cognition and problem-solving strategies.
Observation Summarization
The process of observation summarization can be formalized as ( s_i = S(g_i, o_0, a_0, …, o_t) ), where ( S ) can be implemented using either a Large Language Model (LLM) or alternative text summarization models. This function encapsulates the synthesis of historical observations and actions, contextualized by the current subgoal, to produce a concise representation of the agent’s state. A crucial component of the summarized observation is assessing whether the current subgoal has been achieved.
Trajectory Retrieval
Despite the summarization, there may be instances where detailed past trajectory information becomes crucial for immediate decision-making. The trajectory retrieval module allows the agent to access detailed historical data on-demand without consistently carrying the full context. This selective retrieval enables the agent to identify errors in previous actions and review past successful experiences to increase the likelihood of success when facing novel challenges and scenarios.
Experimental Design
Experimental Setup
We conducted experiments on five long-horizon agent tasks from AgentBoard, which typically require more than 20 steps:
- Blocksworld: Arrange blocks into a specified target configuration.
- Gripper: Move objects between different rooms.
- Tyreworld: Simulate changing a car tire.
- Barman: Emulate a bartender’s tasks in mixing cocktails.
- Jericho: Navigate and interact with fictional worlds in text-based adventure games.
Evaluation Metrics
We used multiple metrics to evaluate both the effectiveness and efficiency of LLM-based agents in solving long-horizon tasks:
- Progress Rate: Proportion of goal conditions fulfilled by the model out of the total number of goal conditions.
- Success Rate: Percentage of successful task completions.
- Average Steps: Steps taken to complete the task.
- Context Efficiency: Mean number of tokens in the in-trial context across all steps required to complete a given task.
- Run Time: Time required to complete tasks.
Baselines
The STANDARD prompting strategy is a predominantly used method in current LLM-based agent literature. It operates by taking one action followed by one observation, providing a comparative baseline for evaluating the performance of HIAGENT.
Implementation Details
The implementation of evaluation tasks is based on AgentBoard. We set a maximum step limit of 30 for task configuration and provide one in-context example for each task. We employ GPT-4 (gpt-4-turbo) as the LLM backbone for our experiments, serving both as the agent policy and the observation summarization model. The temperature hyperparameter for LLM inference is set to 0 and topp to 1.
Results and Analysis
Main Results
As shown in Table 1, HIAGENT demonstrated substantial advancements over STANDARD. Overall, in terms of effectiveness, it increased the success rate by 21% and the progress rate by 23.94%. Regarding task execution efficiency, it reduced the average number of steps to completion by 3.8, decreased the number of context tokens consumed by 35%, and reduced the run time by 19.42%. In certain tasks, HIAGENT achieved more than double the progress rate improvement while maintaining efficiency.


Ablation Study
To explore the effectiveness of individual modules in HIAGENT, we conducted an ablation study:
- Observation Summarization: Removing this module resulted in a significant decline in performance across all metrics, indicating its importance in comprehensively aggregating detailed information within a trajectory.
- Trajectory Retrieval: Removing this module also led to a decrease in success rate and an increase in average steps, highlighting its role in flexible memory management.
- Combined Modules: Removing both modules resulted in a noticeable performance decline, emphasizing the combined effectiveness of Observation Summarization and Trajectory Retrieval.

Performance at Different Steps
HIAGENT consistently achieved a higher progress rate at each step than STANDARD. Additionally, HIAGENT benefited more from an increased number of steps, whereas STANDARD did not. This further demonstrates HIAGENT’s advantage in handling long-horizon agent tasks.

Task Decomposition
To determine if the performance improvement was solely due to task decomposition, we implemented a method that prompts the LLM to generate subgoals without obscuring detailed trajectory information of previous subgoals. The results indicated that while task decomposition led to a performance improvement, HIAGENT was more efficient and effective than task decomposition alone.

Executability of Actions
HIAGENT was more likely to generate executable actions than STANDARD, further demonstrating its effectiveness. STANDARD was more prone to generating non-executable actions when the steps were longer, while HIAGENT maintained high executability even with longer steps.

Statistical Significance
We validated the statistical significance of the improvements in both effectiveness and efficiency using the Wilcoxon signed-rank test. The results confirmed that the observed improvements were not due to random variation, underscoring the superiority of HIAGENT.
Overall Conclusion
This paper proposes HIAGENT, a hierarchical framework that utilizes subgoals to manage the working memory of LLM-based agents. HIAGENT addresses the poor performance of LLM-based agents when handling long-horizon tasks. Experimental results from five long-horizon agent tasks demonstrate that HIAGENT outperforms the baseline model across all tasks, with an overall success rate more than double that of the baseline model. Furthermore, HIAGENT is more efficient, accomplishing tasks with fewer steps, in less runtime, and using shorter context. We believe HIAGENT is an effective and flexible framework that can be integrated into other agent frameworks, inspiring more creative ideas on effectively managing the working memory of LLM-based agents.
Code:
https://github.com/hiagent2024/hiagent


