





Authors:
Zhihao Lin、Zhen Tian、Qi Zhang、Ziyang Ye、Hanyang Zhuang、Jianglin Lan
Paper:
https://arxiv.org/abs/2408.08242
Introduction
Roundabouts have become a significant feature in urban roadways, enhancing vehicle distribution and road capacity. However, the safety and efficiency of autonomous vehicles (AVs) in roundabouts, especially in mixed traffic with human-driven vehicles (HDVs), remain a challenge. This paper introduces a learning-based algorithm designed to ensure safe and efficient driving behaviors in roundabouts. The proposed system employs a deep Q-learning network (DQN) enhanced by a Kolmogorov-Arnold Network (KAN) to robustly learn and execute driving strategies. Additionally, an action inspector and a route planner are integrated to avoid collisions and optimize lane selection, respectively. Model predictive control (MPC) is used to ensure stability and precision in driving actions.
Problem Statement and System Structure
Problem Statement
Navigating roundabouts presents unique challenges due to their complex network of entrances and exits. AVs must interact with HDVs, which can be unpredictably distributed and exhibit varied behaviors. The goal is to ensure safe and efficient navigation by minimizing conflicts and optimizing travel time. The study focuses on a double-lane roundabout without signal lights, involving both HDVs and AVs. Three potential collision scenarios are identified:
- An AV at an entrance with an HDV approaching the same entrance.
- An AV navigating towards an entrance while an HDV attempts to merge.
- An AV exiting from the inner lane encountering an HDV in the outer lane.
These scenarios illustrate the complexity and uncertainty AVs face in roundabouts.


System Structure
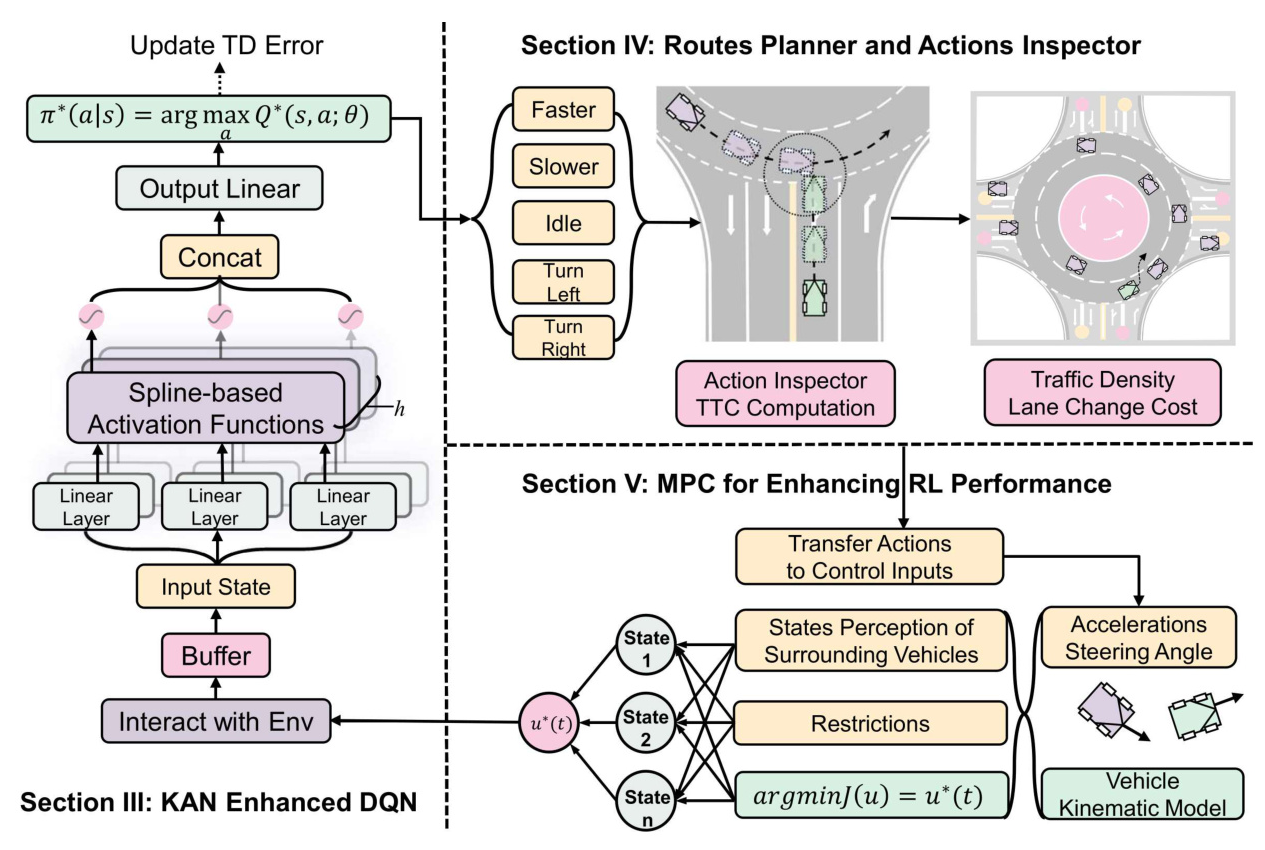
The proposed system comprises four key components: the environment, decision network, safety and efficiency mechanism, and robust control. The environment module updates the state of AVs and generates rewards. The decision network makes safe and efficient decisions. The safety and efficiency mechanism includes a route planner and an action inspector. The route planner guides initial lane selection and path planning, while the action inspector assesses and mitigates collision risks. MPC translates planned actions into safe and smooth control commands.

KAN-Enhanced DQN Method
Basic DQN
DQN combines deep learning with Q-learning to handle high-dimensional state spaces. It uses experience replay and target networks to stabilize the learning process. The Q-value update rule is given by:
[ Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left( r_t + \gamma \max_a Q(s_{t+1}, a) – Q(s_t, a_t) \right) ]
Structure of KAN
KAN uses spline-based activation functions to enhance the learning process. The activation function is defined as:
[ f(x_i; \theta_i, \beta_i, \alpha_i) = \alpha_i \cdot \text{spline}(x_i; \theta_i) + \beta_i \cdot b(x_i) ]
KAN employs regularization strategies to prevent overfitting and parameter sharing among neurons to reduce model complexity.
KAN Enhanced DQN
The integration of KAN within DQN (K-DQN) improves the approximation of the Q-function, especially in complex scenarios. The state space includes the positions, velocities, and headings of the ego vehicle and surrounding vehicles. The action space is discrete, consisting of five high-level actions. The reward function encourages safe and efficient driving.

Routes Planner and Actions Inspector
Driving Rules of HDVs
HDVs follow specific rules to maintain traffic flow and enhance safety. These include yielding to vehicles already in the roundabout and adjusting speeds according to the Intelligent Driver Model (IDM).
Route Planner
The route planner includes initial-lane selection, path planning, and lane-change selection. Initial-lane selection uses the Time to Collision (TTC) metric to ensure safety. Path planning employs a modified Breadth-First Search (BFS) algorithm considering both distance and traffic density. Lane-change selection is based on traffic density and lane-change costs.

Action Inspector
The action inspector predicts the trajectories of neighboring vehicles and replaces dangerous actions with safer alternatives. It calculates safety margins and ensures that the AV selects the safest possible action while maintaining efficiency.

MPC for Enhancing DRL Performance
MPC considers vehicle dynamics, collision avoidance, and other constraints in its optimization process. It predicts future states and corrects any imperfections in the DRL agent’s decisions. The state of the AV is updated using the vehicle dynamic model, and optimal control inputs are obtained by solving an optimization problem.

Simulation Results
Functional Mechanism Validation
The proposed K-DQN is compared with K-DQN without a safety inspector and without MPC. The results show that the proposed K-DQN achieves higher rewards, faster convergence, more stable speed control, and fewer collisions.




Normal Mode Validation
The proposed K-DQN is compared with benchmark algorithms (PPO, A2C, ACKTR, and DQN) in normal mode. The results demonstrate that K-DQN outperforms the benchmarks in terms of training convergence, speed stability, collision rate, and reward values.


Hard Mode Validation
In hard mode, the proposed K-DQN is again compared with benchmark algorithms. The results show that K-DQN maintains superior performance in terms of training efficiency, speed stability, collision rate, and reward values.



Conclusion
The proposed K-DQN algorithm enhances the safety and efficiency of AVs in roundabouts. By integrating KAN, an action inspector, and MPC, the system achieves robust and precise decision-making. The simulation results demonstrate the algorithm’s superior performance compared to state-of-the-art benchmarks. Future research will focus on testing the algorithm in more unpredictable scenarios, enhancing driving strategies, and expanding its applicability to collaborative multi-agent operations.


