





Authors:
Yash Bhalgat、Vadim Tschernezki、Iro Laina、João F. Henriques、Andrea Vedaldi、Andrew Zisserman
Paper:
https://arxiv.org/abs/2408.09860
Introduction
Egocentric videos, which capture the world from a first-person perspective, are gaining significant attention in computer vision due to their applications in augmented reality, robotics, and more. However, these videos present unique challenges for 3D scene understanding, including rapid camera motion, frequent object occlusions, and limited object visibility. Traditional 2D video object segmentation (VOS) methods struggle with these challenges, often resulting in fragmented and incomplete object tracks.
This paper introduces a novel approach to instance segmentation and tracking in egocentric videos that leverages 3D awareness to overcome these obstacles. By integrating scene geometry, 3D object centroid tracking, and instance segmentation, the proposed method achieves superior performance compared to state-of-the-art 2D approaches. Extensive evaluations on the EPIC Fields dataset demonstrate significant improvements across various tracking and segmentation consistency metrics.
Related Work
Video Object Segmentation
Video object segmentation (VOS) has seen significant advancements over the past decade. Traditional methods often relied on frame-by-frame processing, which struggled with maintaining consistent object identities over long sequences. Early approaches like MaskTrack R-CNN and FEELVOS introduced temporal information to improve segmentation consistency. More recent methods, such as STM, AOT, and XMem, leveraged memory networks to handle occlusions and reappearances more robustly.
Point Tracking-Based Methods
Point tracking-based methods have been pivotal in advancing VOS by establishing correspondences across frames. Methods like TAP-Vid, CoTracker, and PIP have focused on tracking physical points in a video. CenterTrack combined object detection with point tracking, leveraging the strengths of both approaches. TAPIR and SAM-PT further refined these techniques using synthetic data and interactive video segmentation, respectively.
3D-Informed Instance Segmentation and Tracking
Recent work has explored lifting and fusing inconsistent 2D labels or segments into 3D models. Methods like Panoptic Lifting, ContrastiveLift, and PVLFF have shown that 3D reconstruction of the scene enables the fusion of unassociated 2D instances. However, exploiting 3D information in egocentric videos has been less explored due to the challenges of reconstructing dynamic objects. EgoLifter and Plizzari et al. have made strides in this area, focusing on 3D tracking of dynamic objects.
Research Methodology
Problem Statement
Given an egocentric video, the objective is to obtain long-term consistent object tracks by leveraging 3D information and an initial set of object segments and tracks obtained from a 2D-only VOS model. The proposed method refines these tracks, correcting errors and achieving more consistent long-term tracking.
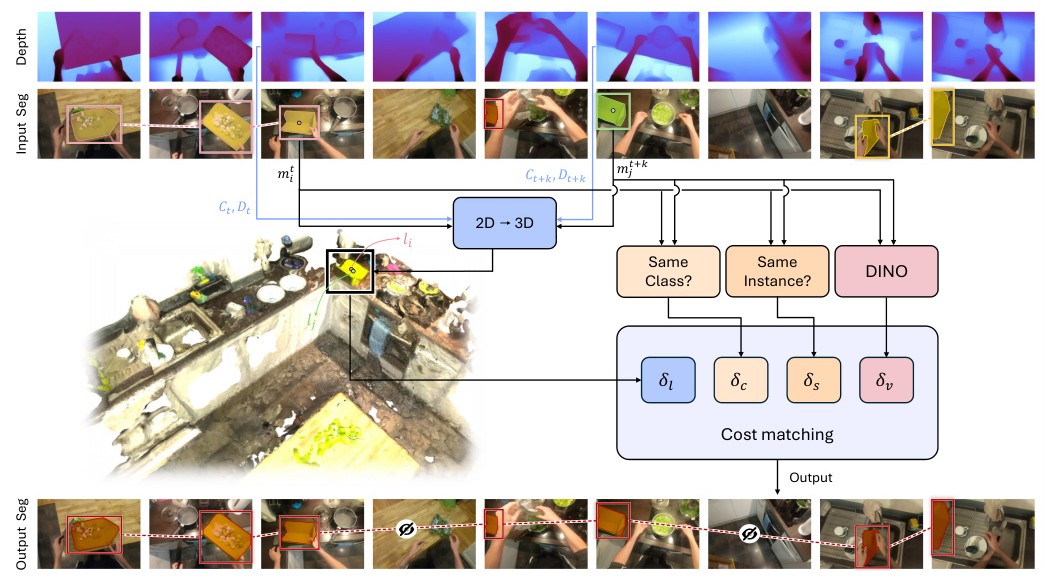
3D-Aware Tracking
The method begins by decomposing the initial tracks into per-frame segments. For each segment, an attribute vector is computed, encoding various characteristics such as initial ID, 3D location, visual features, and category information. These attributes are used to establish correspondences between segments across frames using the Hungarian algorithm. The optimization problem is solved to obtain new refined segment IDs, ensuring temporal consistency.
Attributes for 3D-Aware Cost Formulation
The attributes used for refining the tracks include 3D location, visual features, initial category label, and initial instance label. The 3D location is obtained by projecting the 2D centroid of each segment into 3D using depth maps and camera parameters. Visual features are extracted using a pretrained vision encoder. Initial instance and category labels from the 2D model are used to discourage matching inconsistent segments.
Experimental Design
Benchmark and Baselines
The proposed method is evaluated on 20 challenging scenes from the EPIC Fields dataset, which comprises complex real-world videos with diverse activities and object interactions. The method is compared against DEVA and MASA, two state-of-the-art methods for video object segmentation and tracking.
Metrics
The evaluation uses the HOTA (Higher Order Tracking Accuracy) metric, which combines detection accuracy (DetA), association accuracy (AssA), and localization IoU (Loc-IoU). Additionally, the IDF1 (Identity F1) score is used to measure how well the tracker maintains consistent object identities throughout the sequence.
Results and Analysis
Overall Performance
The proposed method consistently outperforms both DEVA and MASA across various metrics. It achieves an overall HOTA score of 27.72, a notable improvement over DEVA’s 25.14. The method also shows significant improvements in AssA and IDF1 scores, demonstrating superior performance in maintaining consistent object identities throughout the video sequences.


Scene-Specific Analysis
The method shows remarkable improvements in complex scenes, such as P01_01, where it achieves a HOTA score of 41.91 compared to DEVA’s 33.60. Significant improvements are also observed in scenes like P07_101 and P22_117. However, the degree of improvement varies across scenes, suggesting that not all scenes benefit equally from 3D awareness.

Analysis of ID Switches by Object Class
The method consistently and significantly reduces ID switches across various object categories, with improvements ranging from 73% to 80% reduction. This demonstrates the robustness of the 3D-aware approach in maintaining consistent object identities through complex interactions and occlusions typical in egocentric videos.

Ablations
The influence of different components on tracking performance is evaluated by turning off the corresponding cost one at a time. All components contribute positively to the tracking performance, but to varying degrees. The 3D location information proves to be particularly important, with its removal causing a significant drop in the HOTA score.

Sensitivity to Hyperparameters
The method is robust to hyperparameter changes, with 57 out of 81 configurations leading to a HOTA score in the range 27.2 ± 0.2. However, certain configurations, such as when αs = 100 or αc = 100, lead to a degradation in performance.

Metrics Across IoU Thresholds
The method consistently outperforms DEVA across all IoU thresholds for both HOTA and AssA metrics, suggesting that the 3D-aware approach is particularly effective at maintaining consistent object identities throughout the video sequence.

Overall Conclusion
This paper presents a novel 3D-aware approach to instance segmentation and tracking in egocentric videos, addressing the unique challenges of first-person perspectives. By integrating 3D information, the method significantly improves tracking accuracy and segmentation consistency compared to state-of-the-art 2D approaches. The method’s ability to incorporate both initial 2D tracking information and additional 3D cues enables it to handle frequent occlusions, objects moving in and out of view, and rapid camera motion effectively.
Beyond improved tracking, the approach enables valuable downstream applications such as high-quality 3D object reconstructions and amodal segmentation. This work demonstrates the power of incorporating 3D awareness into egocentric video analysis, opening up new possibilities for robust object tracking in challenging first-person scenarios.



