





Authors:
Tianwei Lin、Jiang Liu、Wenqiao Zhang、Zhaocheng Li、Yang Dai、Haoyuan Li、Zhelun Yu、Wanggui He、Juncheng Li、Hao Jiang、Siliang Tang、Yueting Zhuang
Paper:
https://arxiv.org/abs/2408.09856
Introduction
In the realm of Natural Language Processing (NLP) and multi-modal understanding, fine-tuning large language models (LLMs) has proven to be highly effective. However, the substantial memory and computational resources required for full fine-tuning (FFT) of models with over a billion parameters pose significant challenges. Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), have emerged to address these issues by fine-tuning a small subset of parameters. Despite their efficiency, these methods often fall short in multidimensional task scenarios due to catastrophic forgetting and interference between tasks.
To overcome these limitations, the study introduces TeamLoRA, an innovative PEFT method that leverages expert collaboration and competition to enhance both efficiency and effectiveness in multi-task learning. TeamLoRA integrates a novel knowledge-sharing mechanism and a game-theoretic interaction mechanism to balance the trade-offs between training speed, inference speed, and performance.
Related Work
Mixture-of-Experts (MoE)
Mixture-of-Experts (MoE) models integrate multiple sub-models (experts) using a token-based routing mechanism. Notable advancements include the sparsely-gated top-k mechanism, which activates a subset of experts for each input token, significantly reducing resource consumption. Techniques like GShard and OpenMoE ensure fair load distribution among experts, addressing issues such as tail dropping and early routing learning. Recent research has explored the potential of MoE in terms of the number of experts and multimodal fusion.
Parameter-Efficient Fine-Tuning (PEFT)
PEFT methods reduce the dependency on computational costs by introducing additional modules to replace updates to large-scale pre-trained weights. Techniques such as Adapters, Prefix Tuning, and Low-Rank Adaptation (LoRA) have shown exceptional performance. Multi-LoRA architectures, which dynamically combine multiple LoRA experts, have also garnered attention for their robust performance in handling complex tasks.
Research Methodology
Problem Formulation
In multi-task learning scenarios, PEFT adapts to various applications through a lightweight auxiliary module shared among tasks. This approach maintains model compactness while addressing multiple task requirements. The input sequence is processed by the pre-trained layer and auxiliary module, with only the parameters of the auxiliary module being updated during training. This strategy maintains knowledge stability and reduces computational overhead.
Preliminaries
Low-Rank Adaptation (LoRA)
LoRA captures downstream data features by introducing a pair of low-rank matrices as auxiliary modules for the pre-trained weights. The auxiliary weight matrix is decomposed into two matrices, reducing the number of learnable parameters. This approach ensures that LoRA does not affect the original output at the start of training.
Mixture of Experts (MoE)
MoE expands the model scale while activating only a small number of parameters. It duplicates the Feed-Forward Network (FFN) to create a collection of experts, facilitating the transfer of specific knowledge to downstream tasks. The router dynamically allocates a set of weights for token participation, enhancing model performance without significantly increasing training time and inference latency.
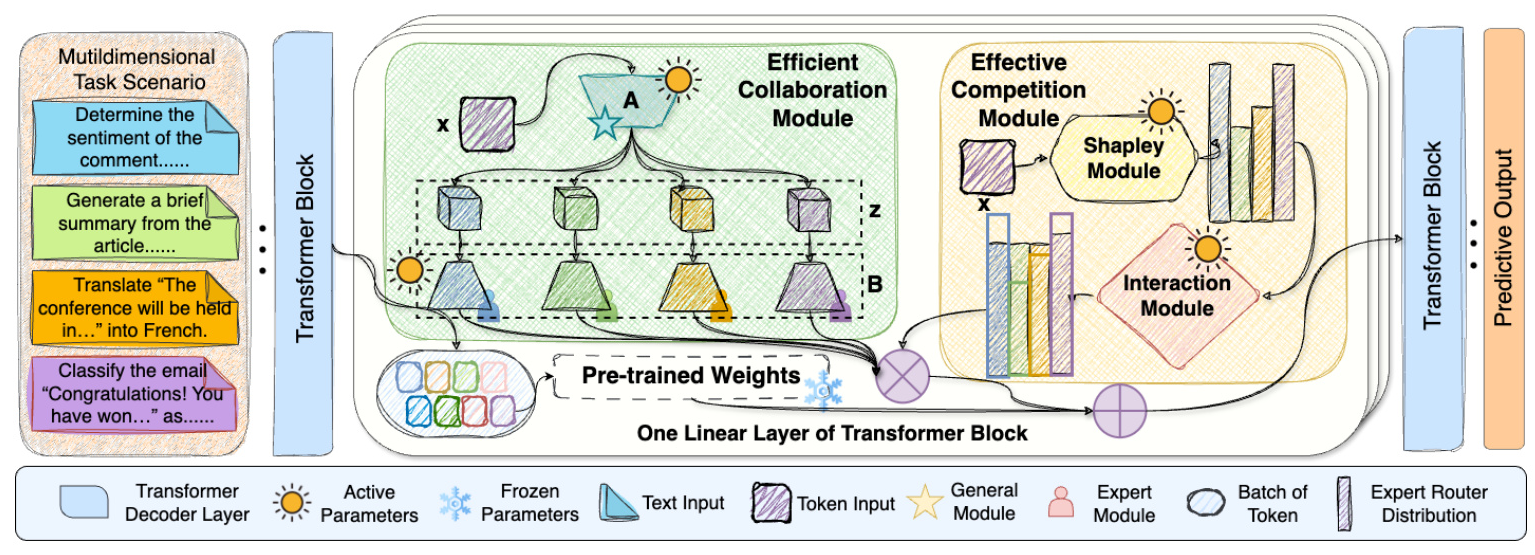
TeamLoRA
TeamLoRA comprises two key components: the Efficient Collaboration Module and the Effective Competition Module.
Efficient Collaboration Module
This module facilitates hierarchical collaboration between the general module (matrix A) and expert modules (matrix B). The general module captures homogeneous features across tasks, while the expert modules provide specialized knowledge supplementation. This asymmetric knowledge expression strategy enhances training and inference efficiency through fewer matrix calculations.
Effective Competition Module
Inspired by game theory, this module introduces a competitive interaction mechanism to boost expert participation based on diverse task-aware inputs. By dynamically adjusting input distribution and expert responsibilities, the competition module ensures more effective and equitable knowledge transfer across tasks.
Experimental Design
Benchmark and Setting
The study used a comprehensive multi-task evaluation (CME) benchmark containing 2.5 million samples across various domains and task types. The LLaMA-2 7B model was selected as the base model, with continued pre-training on an expanded Chinese LLaMA-2-7B corpus to enhance knowledge capacity and multilingual capability. All experiments were conducted on 8×A800 GPUs, using the same hyperparameter settings.
Comparison of Methods
Several prominent PEFT methods were selected for comparison, including Prompt-Tuning, IA3, LoRA, MoSLoRA, and AdaLoRA. The study also compared methods utilizing MoE mechanisms, such as MoELoRA and HydraLoRA.
Results and Analysis
Overall Performance
TeamLoRA demonstrated superior performance in multi-task learning scenarios using the CME benchmark. It achieved the best or second-best performance across multiple tasks, with an average score significantly higher than other PEFT methods. Despite a slightly longer training time, TeamLoRA achieved competitive average scores with efficient parameter utilization. It also showed significant performance improvements and reduced training costs compared to other multi-LoRA architectures.


Quantitative Analysis
Analysis of Parameter Scales
TeamLoRA consistently exhibited superior performance across various parameter configurations. It effectively alleviated knowledge collapse, reflecting the stability of its adaptive mechanisms.

Ablation Analysis
Both the collaboration and competition modules enhanced the model’s expressive and adaptive capabilities in multi-task scenarios. The collaboration module promoted knowledge integration and transfer among experts, while the competition module adjusted the model’s preferences for transferring specific knowledge to downstream tasks.

In-Depth Analysis
Stability Analysis
TeamLoRA’s performance improved progressively as the number of expert modules increased, thanks to its hierarchical knowledge structure and effective “plug-in” knowledge sharing and organization. It also maintained efficient domain knowledge transfer across varying data scales.

Computational Costs and Loss Convergence
TeamLoRA reduced training time by 30% and increased inference speed by 40% compared to MoELoRA. It also achieved lower loss values more quickly, highlighting its optimization in training efficiency.

Expert Load Analysis
TeamLoRA demonstrated better load balancing compared to MoELoRA, ensuring greater model stability. It effectively learned task-specific models by assigning different expert modules as plug-ins for knowledge combinations.

Performance Comparison of Different Base Models
TeamLoRA maintained its advantages in multi-task learning across different base models, consistently demonstrating the best performance.

Performance Analysis of MLLM
TeamLoRA achieved the best performance on the majority of benchmarks in multimodal scenarios, indicating its strong generalizability.

Overall Conclusion
TeamLoRA introduces an innovative PEFT approach by integrating collaborative and competitive modules, significantly improving the efficiency and effectiveness of multi-task learning. In the proposed CME benchmark tests, TeamLoRA not only achieves faster response speed but also outperforms existing multi-LoRA architectures in performance. Future research will further explore the game-theoretic framework based on competition and collaboration in multi-LoRA architectures, expanding the potential of PEFT.
Code:
https://github.com/lin-tianwei/teamlora
Datasets:
GLUE、IMDb Movie Reviews、Natural Questions、MMLU、ANLI、VizWiz、MM-Vet


