





Authors:
Antonis Maronikolakis、Ana Peleteiro Ramallo、Weiwei Cheng、Thomas Kober
Paper:
https://arxiv.org/abs/2408.08907
Evaluating Conversational Agents in the Fashion Domain: What Should I Wear to a Party in a Greek Taverna?
Introduction
The advent of large language models (LLMs) and generative artificial intelligence has significantly transformed natural language processing, both in academia and industry. LLMs, developed through large-scale pretraining and reinforcement learning from human feedback, have demonstrated remarkable proficiency in language comprehension. This has led to their widespread use in customer support services, particularly in e-commerce and healthcare. In this study, we focus on the domain of online fashion retail and the use of conversational agents for customer support.
Fashion is not just about clothing; it enables individuals to express themselves, communicate their identity and values, and foster a sense of community. Online fashion retailers offer customers the convenience of browsing a wide range of assortments, inspiring them to develop their personal taste and empowering them to make confident decisions. LLM-powered conversational agents present an opportunity to revolutionize online fashion retail by allowing customers to describe and refine their wants interactively, using their own words and fashion ideas.
In this study, we evaluate the capabilities of conversational agents to interact with customers and interface with a backend search engine. We developed a multilingual evaluation dataset of 4,000 conversations between customers and a fashion assistant on a large e-commerce fashion platform. This dataset is used to measure the capabilities of LLMs to serve as an assistant between customers and a backend engine, facilitating iterative development of tools.
Related Work
Considerable work has been done towards the evaluation of text generation, from early textual overlap metrics to methods based on the similarity of contextualized representations. State tracking evaluation methods offer a structured way to evaluate the capabilities of models to converse in desirable patterns and produce appropriate responses at each stage of the conversation. Traditional metrics have often been shown to be uninterpretable due to the highly stochastic and subjective nature of text generation and its evaluation. Consequently, there have been efforts to develop systems involving humans and manual quality assessment.
With the rise of LLMs and their advanced conversational and reasoning capabilities, evaluation of text generation models is moving towards the development of leaderboards based on benchmarks of a series of tasks and evaluations for more reproducible comparison of powerful models.
Research Methodology
Data Creation
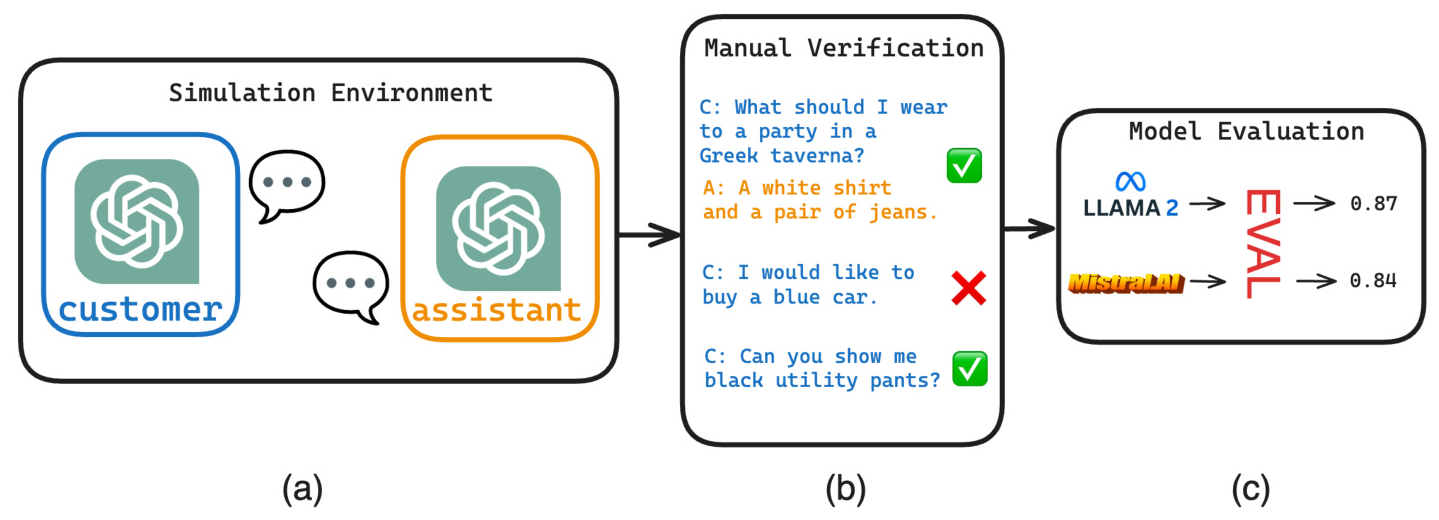
To ensure robust evaluation of conversational agents, we created our dataset in two steps: conversation generation through a simulation environment and manual quality verification.
Fashion Attributes
We focused on six fashion attributes: color, type, material, fit, brand, and size. Additionally, we covered eight apparel types: pants, trousers, shoes, jacket, coat, sweatshirt, hoodie, and jeans. We also included nine open-ended themes that customers might be shopping for, such as hiking, Christmas dinner, football in winter, rooftop summer party, techno club in Berlin, coffee house in Vienna, party in a Greek taverna, sports in the summer, and eccentric timelord book bazaar.
Generation of Conversations
Conversations were generated in a simulation environment using the generative capabilities of GPT. We simulated customer and assistant interactions on three levels: template-based customer interactions, LLM-based customer given the description of an item to purchase, and LLM-based customer given an abstract theme to shop for. The assistant was a production-level GPT-3.5 model prompted to aid customers through their fashion shopping journey.
Manual Verification of Conversations
We manually verified every conversation to ensure high quality. Conversations that did not meet our quality standards were removed. We also translated the curated conversations to German, French, and Greek using GPT-4, ensuring high-quality translations.
Data Description
Each conversation in the dataset is broken down into pairs of messages between customer and assistant agents, as well as metadata for each interaction. The dataset includes fields such as conversation-level unique identifier, goal description, properties, customer message, assistant message, queries, and action taken by the assistant.
Evaluation Details
For the evaluation of performance, we used BERTScore to compare the expected query with the output query. For open-ended themes, we evaluated generated queries based on semantic similarity using contextualized embeddings.
Models
We evaluated a series of models using our dataset, including Llama2, Mistral, and GPT-based models (GPT-3.5 and GPT-4). We also compared these models with a low-cost, off-the-shelf unsupervised keyword extractor, Yake, and provided a popularity and a random baseline.
Experimental Design
AssistantEval Task
We benchmarked conversational agents as fashion shopping assistants, evaluating their capabilities to translate customer wants into concrete queries to interface with a backend search engine. We found that open-source models struggled with producing formatted output, while GPT-4 performed the best across all languages.
Fashion Attribute Performance Analysis
We performed a qualitative analysis of GPT-4’s performance across different fashion attributes. Performance was adequate for attributes with clear definitions, such as color, material, and fit, but lower for more open-ended attributes like type and apparel. Performance for the size attribute was particularly low, potentially due to deficiencies in extracting correct size labeling.
Open-ended Themes
We compared GPT models in aiding customers shop for a theme instead of concrete item descriptions. GPT-4 performed the best overall, especially in the English set.
QueryGenEval Task
We evaluated the query generation capabilities of models, assuming that the customer had given all the necessary information. GPT-4 performed the best in English, while GPT-3.5 performed marginally better in German, French, and Greek.
Results and Analysis
AssistantEval Results
GPT-4 outperformed other models in the AssistantEval task, demonstrating superior capabilities in translating customer wants into concrete queries. The cost analysis showed that while GPT-4 was the most expensive, it provided the best performance.
Fashion Attribute Performance
Performance varied across different fashion attributes, with clear definitions yielding better results. The size attribute had the lowest performance, highlighting the need for improvement in extracting correct size labeling.
Open-ended Themes
GPT-4 excelled in aiding customers shop for open-ended themes, with the highest Precision@3 scores. The cost analysis confirmed that GPT-4’s superior performance came at a higher cost.
QueryGenEval Results
GPT-4 again performed the best in the QueryGenEval task, with the highest F1 scores. The cost analysis showed that while GPT-4 was the most expensive, it provided the best performance.
Overall Conclusion
The study highlights the potential of LLM-powered conversational agents to revolutionize online fashion retail by enabling interactive and personalized customer interactions. Our multilingual evaluation dataset and methodology facilitate the iterative development of assistant agents, ensuring fair and reproducible evaluation. GPT-4 consistently outperformed other models, demonstrating superior capabilities in both the AssistantEval and QueryGenEval tasks. However, the higher cost associated with GPT-4 underscores the need for balancing performance and cost in practical applications.
By leveraging the power of LLMs, online fashion retailers can enhance customer experience, inspire personal taste development, and empower customers to make confident decisions. The study provides a robust framework for evaluating and developing conversational agents in the fashion domain, paving the way for future advancements in this field.











