





Authors:
Jinming Nian、Zhiyuan Peng、Qifan Wang、Yi Fang
Paper:
https://arxiv.org/abs/2408.08444
Introduction
Open-domain question answering (OpenQA) systems aim to provide natural language answers to user queries. Traditionally, these systems use a “Retriever-Reader” architecture, where the retriever fetches relevant passages, and the reader generates answers. Despite the advancements in large language models (LLMs) like GPT-4 and LLaMA, these models face limitations such as fixed parametric knowledge and the tendency to generate non-factual responses, known as hallucinations.
To address these issues, Retrieval-Augmented Generation (RAG) systems have been explored. RAG systems enhance LLMs by retrieving relevant information from external sources. However, training dense retrievers in RAG systems is challenging due to the scarcity of human-annotated data. This paper introduces W-RAG, a framework that leverages the ranking capabilities of LLMs to create weakly labeled data for training dense retrievers, thereby improving both retrieval and OpenQA performance.
Related Work
Dense Retrieval
Traditional information retrieval methods like BM25 are based on exact term matching but suffer from the lexical gap issue. Dense retrieval (DR) methods, leveraging neural networks, encode questions and passages into embeddings and measure relevance by vector similarity. DR can be supervised or unsupervised, with models like DPR, TAS-B, ColBERT, Contriever, and ReContriever.
RAG for OpenQA
RAG models have shown significant performance improvements in OpenQA. Various RAG models address issues such as retrieving relevant passages, determining when to call the retriever, and reducing computational complexity. Studies have focused on improving retriever quality through better training and prompt engineering.
LLMs for Ranking
Existing work on generating weakly labeled ranking data using LLMs can be categorized into zero-shot listwise ranking, direct relevance rating, and question generation likelihood. This paper’s method aligns with the third approach, ranking passages by the likelihood of generating the ground-truth answer.
Method
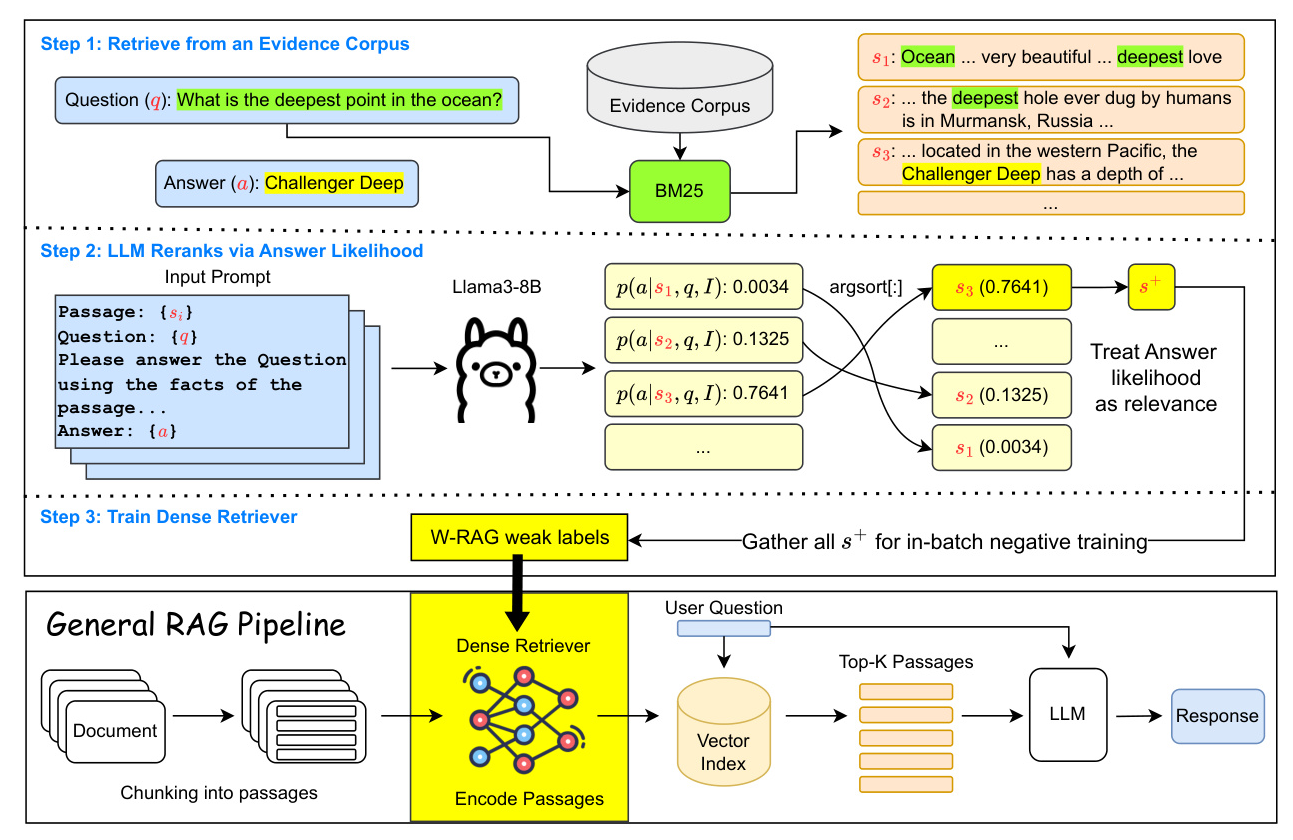
W-RAG introduces a novel approach for training the retrieval component within the RAG pipeline using weakly supervised training. The process unfolds in three stages: retrieving relevant passages, generating weak labels by reranking passages based on answer likelihood, and training the dense retriever using these weak labels.
Weak-label Generation
Given an evidence corpus, a simple retriever (e.g., BM25) retrieves the top-K passages for a question. These passages are then reranked by an LLM based on the likelihood of generating the ground-truth answer. The highest-ranking passage is used as the positive example for training the dense retriever.


Training Dense Retriever
The dense retriever is trained using the weakly labeled data. Two representative dense retrievers, DPR and ColBERT, are investigated. DPR uses a bi-encoder architecture with in-batch negative sampling, while ColBERT employs a bi-encoder architecture with late interaction and pairwise softmax cross-entropy loss.
Experiments
Task and Datasets
Experiments were conducted on four well-known OpenQA datasets: MSMARCO QnA v2.1, NQ, SQuAD, and WebQ. Each dataset was sampled to create training, validation, and test sets. The effectiveness of W-RAG was assessed by evaluating the quality of weak labels, retrieval performance, and overall RAG system performance.
Weak Label Quality
Llama3-8B-Instruct was used as the reranker to generate weak labels for the training set. The reranking performance was evaluated using different prompts and LLMs.
Weakly Trained Retriever
DPR and ColBERT were trained using the weakly labeled data. Two initialization settings were used for DPR: training from scratch and resuming training from an unsupervised dense retriever. ColBERT was trained from scratch for all datasets.
OpenQA Performance
The dense retriever was integrated into the RAG pipeline, and the top-K evidence passages were used to supplement the prompt for the LLM. The impact of different retrievers on OpenQA performance was evaluated.

Results
Main Results
W-RAG trained retrievers showed consistent improvements across all datasets compared to baselines. The gap between weakly supervised and ground-truth trained retrievers was relatively small, indicating that W-RAG data approaches the quality of human-labeled data.

Retrieval Results
W-RAG trained retrievers outperformed unsupervised baselines in most cases. However, better retrieval performance did not always lead to better OpenQA performance, suggesting that traditional relevance definitions may not directly impact answer quality in RAG systems.

W-RAG Labels
The quality of weakly labeled rank lists was examined, showing a significant gap between BM25 and Llama3’s reranking performance. This justified the choice of using the top 1 passage as the positive example for training.

Ablation Study
Different LLMs were evaluated for their reranking performance, with Llama3-8B-Instruct showing consistent trends. The impact of different prompts and the number of evidence passages on OpenQA performance was also studied.

Conclusions and Future Work
W-RAG introduces a general framework for extracting weak labels from question-answer pairs to address the scarcity of training data for dense retrieval in RAG for OpenQA. Extensive experiments demonstrated the effectiveness of W-RAG. Future work will explore the types of passages that most effectively enhance RAG performance, the compression of retrieved passages, and enhancing the robustness of RAG in OpenQA.


Code:
https://github.com/jmnian/weak_label_for_rag


