





Authors:
Paper:
https://arxiv.org/abs/2408.08437
Introduction
Vision Transformers (ViTs) have emerged as a powerful alternative to Convolutional Neural Networks (CNNs) for various image recognition tasks. They offer significant improvements in computational efficiency and accuracy. However, ViTs are complex and memory-intensive, making them unsuitable for resource-constrained mobile and edge systems. To address this challenge, the paper introduces PQV-Mobile, a combined pruning and quantization toolkit designed to optimize ViTs for mobile applications.
PQV-Mobile Tool
The PQV-Mobile tool supports various structured pruning strategies and quantization methods to optimize ViTs for mobile deployment. The tool’s workflow is illustrated in Figure 1.


Pruning Method
PQV-Mobile supports several structured pruning strategies, including:
- Magnitude Importance Based Grouping: Applies L1 or L2 norm regularization to penalize non-zero parameters, dropping connections below a certain threshold.
- Taylor Importance Based Grouping: Uses a Taylor expansion to approximate the importance of parameters, allowing for faster computation.
- Hessian Importance Based Grouping: Utilizes a second-order metric to identify insensitive parameters, pruning those with relatively small sensitivity.
In structured pruning, a ‘Group’ is defined as the minimal unit that can be removed. PQV-Mobile uses a dependency graph to model these dependencies and find the right groupings for parameter pruning.
Quantization Method
PQV-Mobile supports post-training quantization of both weights and activations from FP32 to FP16 and int8. The quantization process involves:
- Quantizing Models for Specific Backends: Creating a quantization engine based on backends like x86, FBGEMM, QNNPACK, and ONEDNN.
- Converting Pytorch Models to Torchscript Format: Exporting models to production environments through Torchscript.
- Optimizing Models for Mobile Applications: Using Pytorch’s mobile optimizer and Lite Interpreter to create deployable and lightweight models.
Experimental Results
The effectiveness of PQV-Mobile is demonstrated through experiments on Facebook’s Data Efficient Image Transformers (DeiT). The experiments evaluate latency-memory-accuracy trade-offs for different pruning and quantization levels.
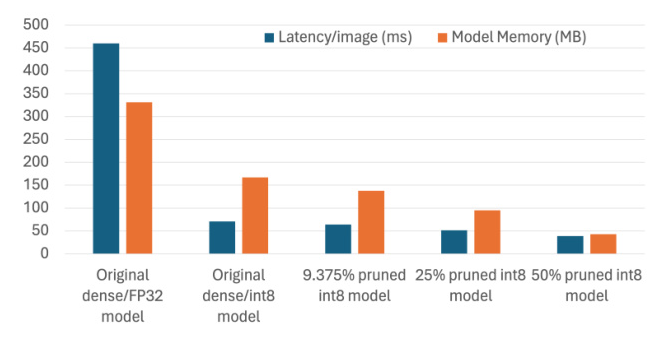
Latency and Memory Results
Figure 2 shows the latency and memory results for the DeiT base patch16 model with varying pruning and quantization levels. Quantizing the original dense model to int8 leads to a 6.47× reduction in latency. Pruning the quantized model by 9.375% further reduces latency by 9.8%, resulting in an overall 7.14× latency reduction.

Accuracy Results
Figure 4 illustrates the accuracy results for the DeiT base patch16 model with varying pruning and quantization levels. Pruning the model by 9.375% results in a 1.25% accuracy loss, while further quantizing it to int8 leads to an additional 0.99% loss in accuracy.

Structured Pruning Groupings
Figure 5 compares the accuracy results for different structured pruning groupings. Taylor pruning outperforms L1-norm and Hessian-based pruning, making it the preferred method for all experiments.

Comparison of DeiT Models
Figure 6 compares the latency and accuracy of pruning and quantizing the DeiT base patch16 model with the DeiT3 medium patch16 model. The latter shows latency improvements by 18.65% and 13.55% over the former when pruned to the same levels.

Hardware Backend Evaluation
Figure 7 evaluates the latency for different int8 quantization hardware backends using the 9.375% pruned DeiT3 medium patch16 model. The x86 and FBGEMM backends perform the best, with FBGEMM slightly outperforming x86.

Conclusion and Future Work
PQV-Mobile is a powerful tool for optimizing ViTs for mobile applications through combined pruning and quantization. It supports various structured pruning strategies and quantization methods, demonstrating significant improvements in latency and memory with minimal accuracy loss. Future work includes extending PQV-Mobile to int4 quantization and targeting large language models.
Acknowledgements
This work was performed under the auspices of the U.S. Department of Energy by LLNL under contract DE-AC52-07NA27344 (LLNL-CONF-865054).


