





Authors:
Guofeng Mei、Luigi Riz、Yiming Wang、Fabio Poiesi
Paper:
https://arxiv.org/abs/2408.10652
Introduction
3D instance segmentation (3DIS) is a crucial task in computer vision, aiming to identify and label individual objects within a 3D scene. Traditional methods often rely on a predefined set of categories, known as a vocabulary, which limits their flexibility and adaptability to new or unseen objects. Recent advancements have introduced open-vocabulary methods, which allow for a broader range of object recognition. However, these methods still depend on a user-specified vocabulary at test time, restricting their ability to operate in truly open-ended scenarios.
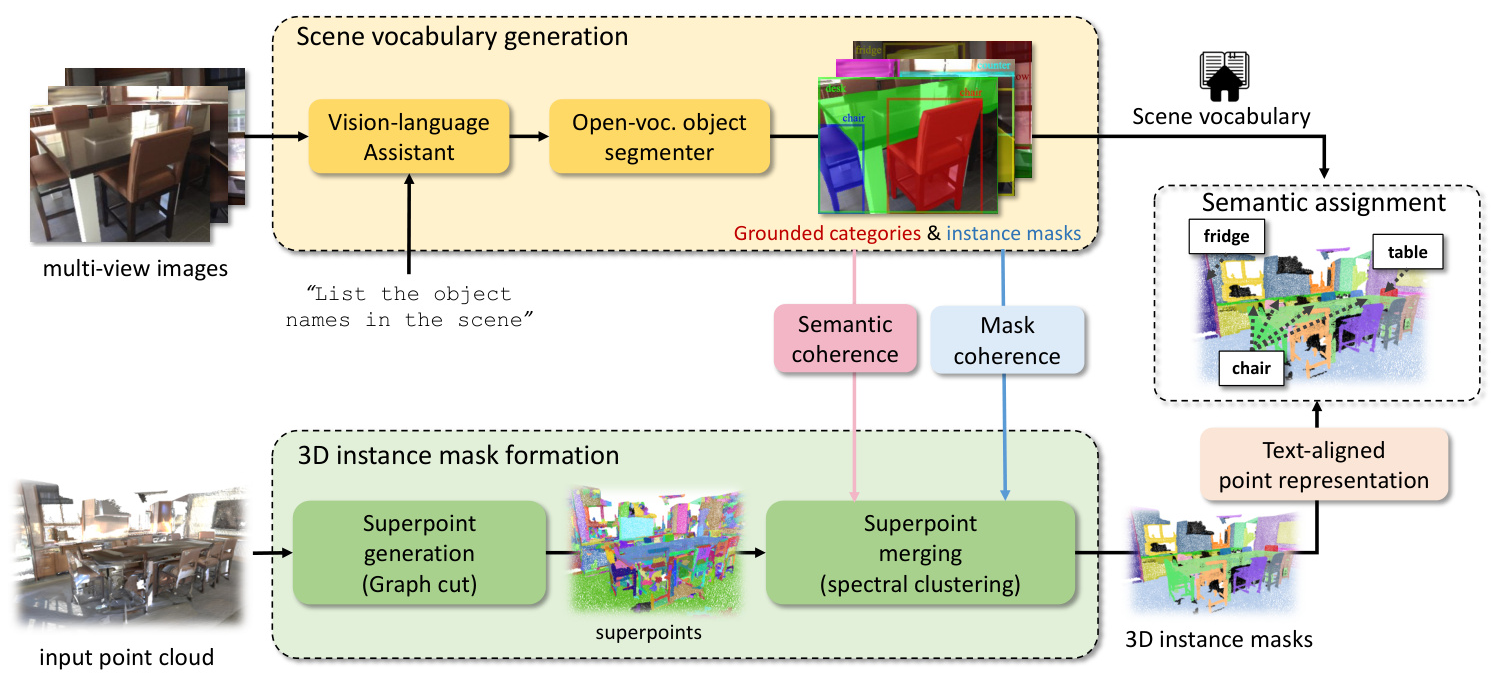
In this study, we introduce a novel approach to 3D instance segmentation that operates without any predefined vocabulary, termed Vocabulary-Free 3D Instance Segmentation (VoF3DIS). Our method leverages a large vision-language assistant and an open-vocabulary 2D instance segmenter to autonomously discover and ground semantic categories in 3D scenes. This approach enables the segmentation and labeling of objects without relying on any vocabulary prior, making it highly adaptable to dynamic and evolving environments.
Related Work
Vocabulary-Free Models
The concept of vocabulary-free models was pioneered by Conti et al. [3], who introduced a method for image classification without relying on a predefined vocabulary. Their approach, named CaSED, retrieves captions from a database and extracts candidate categories through text parsing and filtering. Subsequent works have extended this concept to semantic image segmentation and fine-grained image classification using vision-language assistants.
Open-Vocabulary 3D Scene Understanding
Recent advancements in 3D scene understanding have focused on adapting Vision-Language Models (VLMs) to the 3D domain. Methods such as PLA [7], OpenScene [26], and OV3D [13] have leveraged multi-view images and pixel-to-point correspondences to train text-aligned 3D encoders or directly address open-vocabulary 3D scene understanding tasks. These methods aim to obtain point-level representations aligned with textual descriptions, enabling the recognition of a wide range of objects.
3D Instance Segmentation Methods
Open-vocabulary 3D instance segmentation methods, such as OpenMask3D [33] and OVIR-3D [22], aim to obtain instance-level 3D masks with associated text-aligned representations. These methods often rely on class-agnostic 3D instance mask generators and vision-language models like CLIP to match visual and textual representations. Recent works have also explored superpoint-based approaches to progressively merge 3D instance masks with 2D guidance.
Research Methodology
Definition of VoF3DIS
Vocabulary-Free 3D Instance Segmentation (VoF3DIS) aims to assign semantic labels to 3D instance masks in a point cloud without relying on any predefined vocabulary. Given a point cloud ( P ) and a set of posed images ( V ), the goal is to segment all object instances and assign semantic labels from an unconstrained semantic space.
Challenges
The primary challenges in VoF3DIS include ensuring spatial consistency when assigning labels to points, handling point sparsity and reconstruction noise, and differentiating between objects with similar shapes but different functions. These challenges necessitate robust methods for semantic grounding and instance mask formation.
Experimental Design
PoVo: Proposed Method
Our method, PoVo, leverages a vision-language assistant and an open-vocabulary 2D instance segmenter to identify and ground objects in multi-view images. The process involves the following steps:
- Scene Vocabulary Generation: The vision-language assistant is prompted to list object names in each posed image. An open-vocabulary 2D instance segmenter then grounds these categories with instance masks, forming the scene vocabulary.
- 3D Instance Mask Formation: The point cloud is partitioned into geometrically-coherent superpoints using graph cut. These superpoints are then merged into 3D instance masks via spectral clustering, considering both mask coherence and semantic coherence.
- Text-Aligned Point Representation: For each 3D instance proposal, text-aligned representations are obtained by aggregating visual features from multi-view images and enriching them with superpoint-level textual features.


Datasets and Performance Metrics
We evaluate PoVo on two benchmark datasets: ScanNet200 and Replica. The performance is measured using Average Precision (AP) at various mask overlap thresholds, as well as BERT Similarity to quantify the semantic relevance of predicted labels.
Baselines
We compare PoVo with state-of-the-art methods, including OpenScene, OpenMask3D, OVIR-3D, SAM3D, SAI3D, OVSAM3D, and Open3DIS. Adaptations of these methods to the VoF3DIS setting are also evaluated.
Results and Analysis
Quantitative Results
ScanNet200
PoVo outperforms existing methods in both open-vocabulary and vocabulary-free settings on the ScanNet200 dataset. It achieves strong and stable performance across common and rare class categories, demonstrating its robustness and adaptability.

Replica
On the Replica dataset, PoVo also surpasses other baselines, highlighting its effectiveness in handling unseen categories and leveraging the assistance of vision-language models.

Qualitative Results
PoVo accurately segments and labels various objects in 3D scenes, even those not present in predefined labels. The qualitative results showcase its ability to handle diverse and complex environments.

Ablation Studies
Ablation studies reveal the importance of text embedding enhanced features and superpoint-based average pooling in improving instance segmentation performance. Incorporating text feature similarity for superpoint merging further enhances the accuracy of 3D instance proposals.

Overall Conclusion
We presented PoVo, a novel approach to 3D instance segmentation that operates without a predefined vocabulary. By integrating a vision-language assistant with an open-vocabulary 2D instance segmenter, PoVo autonomously identifies and labels 3D instances in a scene. Our method demonstrates superior performance on benchmark datasets, validating its robust design and adaptability to dynamic environments. Future research directions include exploring new 3D scene understanding tasks and enhancing geometric understanding using recent zero-shot approaches.



