





Authors:
Cristian Sestito、Shady Agwa、Themis Prodromakis
Paper:
https://arxiv.org/abs/2408.10243
Introduction
Convolutional Neural Networks (CNNs) have become the cornerstone of various AI applications, from computer vision to speech recognition. However, the computational and memory demands of CNNs, especially for high-resolution images, pose significant challenges. The VGG-16 CNN, for instance, requires substantial memory and computational resources to process its multi-dimensional feature maps (fmaps). This paper introduces TrIM, a novel dataflow architecture designed to address these challenges by reducing memory accesses and enhancing energy efficiency.
Related Work
Systolic Arrays and Dataflows
Systolic Arrays (SAs) are a promising solution to mitigate the Von Neumann bottleneck by maximizing data utilization. They consist of an array of Processing Elements (PEs) that perform Multiply-Accumulate (MAC) operations. Various dataflows have been proposed to optimize SAs, including Input-Stationary (IS), Weight-Stationary (WS), and Output-Stationary (OS) dataflows. However, these traditional dataflows often require data redundancy, which increases memory capacity and access costs.
Conv-to-GeMM and GeMM-Free Approaches
To handle the convolutional layers (CLs) of CNNs, many architectures convert convolutions into matrix multiplications (Conv-to-GeMM). While this approach simplifies the computation, it introduces data redundancy. GeMM-free SAs, such as Eyeriss, propose alternative dataflows like Row Stationary (RS) to avoid this redundancy. However, these approaches still face challenges in terms of memory access and energy efficiency.
Triangular Input Movement (TrIM)
The TrIM dataflow introduces a triangular movement of inputs while keeping weights stationary at the PE level. This innovative approach significantly reduces memory accesses and improves throughput compared to traditional dataflows. The TrIM-based architecture is designed to handle multi-dimensional CLs efficiently, making it a promising candidate for CNN acceleration.
Research Methodology
TrIM-Based Hardware Architecture
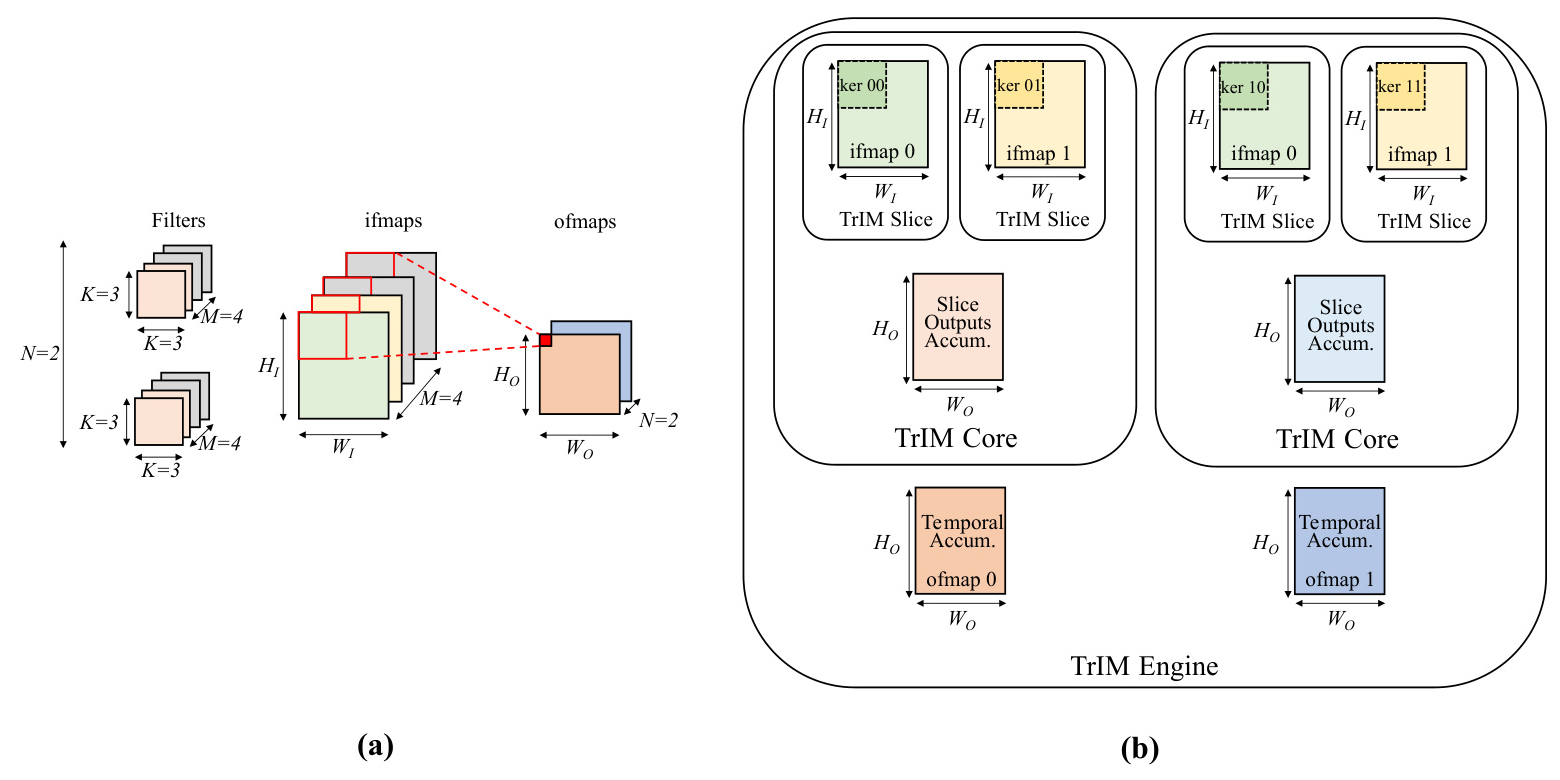
The TrIM-based architecture is organized hierarchically into three levels:
- TrIM Slice: Performs 2-D K × K convolutions with stationary weights and triangular input movement.
- TrIM Core: Accommodates multiple slices and accumulates their outputs to generate one output feature map (ofmap).
- TrIM Engine: Consists of multiple cores, each processing independent 3-D filters and generating multiple ofmaps in parallel.
Reconfigurable Shift Register Buffers (RSRBs)
The RSRBs handle different input feature map (ifmap) sizes for optimal SA utilization. They are equipped with run-time reconfigurability to manage various ifmap sizes, ensuring efficient data movement and storage.
Experimental Design
Design Space Exploration
To evaluate the TrIM-based architecture, a design space exploration was conducted using the VGG-16 CNN as a case study. The exploration considered metrics such as throughput, psums buffer size, and I/O bandwidth. The analysis spanned various configurations of slices and cores to identify the optimal parameters for the architecture.
FPGA Implementation
The TrIM Engine was synthesized and implemented on the AMD Zynq UltraScale+ XCZU7EV-2FFVC1156 MultiProcessor System-on-Chip (MPSoC). The design aimed to balance on-chip memory usage and I/O bandwidth to achieve high throughput and energy efficiency.
Results and Analysis
Performance Comparison
The TrIM-based architecture achieved a peak throughput of 453.6 GOPs/s and demonstrated significant improvements in memory access and energy efficiency compared to state-of-the-art architectures like Eyeriss. The triangular input movement effectively reduced memory accesses by approximately 5.1× and improved energy efficiency by up to 12.2×.
Resource Utilization
The FPGA implementation of the TrIM-based architecture utilized 193.42K LUTs, 89.47K FFs, and 10.21 Mb of BRAMs. Despite using more PEs, the architecture maintained a lower power consumption and higher energy efficiency compared to other FPGA-based accelerators.
Overall Conclusion
The TrIM-based architecture presents a significant advancement in the design of energy-efficient hardware accelerators for CNNs. By leveraging the triangular input movement dataflow, the architecture reduces memory accesses and enhances throughput. The FPGA implementation of the TrIM Engine showcases its potential for real-world applications, achieving superior performance and energy efficiency compared to existing solutions.
Future Work
Future research will focus on reducing the footprint of shift register buffers through resource sharing, investigating ifmap tiling to minimize area requirements, and designing an ASIC implementation to further enhance energy efficiency and scalability.
The TrIM-based architecture represents a promising direction for the development of high-performance, energy-efficient hardware accelerators for CNNs, paving the way for more efficient AI applications in various domains.


