





Authors:
Zeyuan Chen、Haiyan Wu、Kaixin Wu、Wei Chen、Mingjie Zhong、Jia Xu、Zhongyi Liu、Wei Zhang
Paper:
https://arxiv.org/abs/2408.09439
In the ever-evolving landscape of search engines, relevance modeling plays a pivotal role in enhancing user experience by accurately identifying items that align with users’ queries. Traditional models often fall short by relying solely on semantic congruence, which is insufficient for capturing the full spectrum of relevance. This blog delves into a novel approach that leverages user interactions and advanced prompting techniques to boost relevance modeling driven by Large Language Models (LLMs).
Introduction
Background
Search engines are indispensable tools for navigating the vast expanse of online content. The core functionality of these engines hinges on relevance modeling, which ensures that the results displayed are pertinent to the user’s query. Traditional relevance models primarily focus on semantic matching, which, while useful, often fails to capture the nuanced search intentions of users.
Problem Statement
Even with the advent of powerful LLMs, accurately judging the relevance of a query and an item remains challenging. This is primarily due to the absence of domain-specific knowledge and the inadequacy of isolated prompts. Additionally, the high costs associated with deploying LLMs in real-world scenarios pose significant obstacles.
Related Work
Semantics-driven Methods
Current semantics-driven approaches can be broadly classified into feature-based and deep learning-based methods. Feature-based approaches, such as TF-IDF and BM25, rely on manual-crafted features but suffer from limited generalization. Deep learning-based methods, including representation-based and interaction-based models, have shown promise but still face challenges in modeling complex relationships.
Behavior-driven Methods
Incorporating user behavior data into relevance models has been explored to some extent. Methods like MASM leverage historical behavior data for model pre-training, while others use click graphs to enhance search systems. However, these approaches often fail to fully integrate LLMs with user behavior data comprehensively.
Research Methodology
Problem Formulation
The core objective is to predict the relevance degree between a target query and a target item using LLMs. This involves designing prompts that guide LLMs to determine the likelihood of relevance based on user behavior data and domain-specific knowledge.
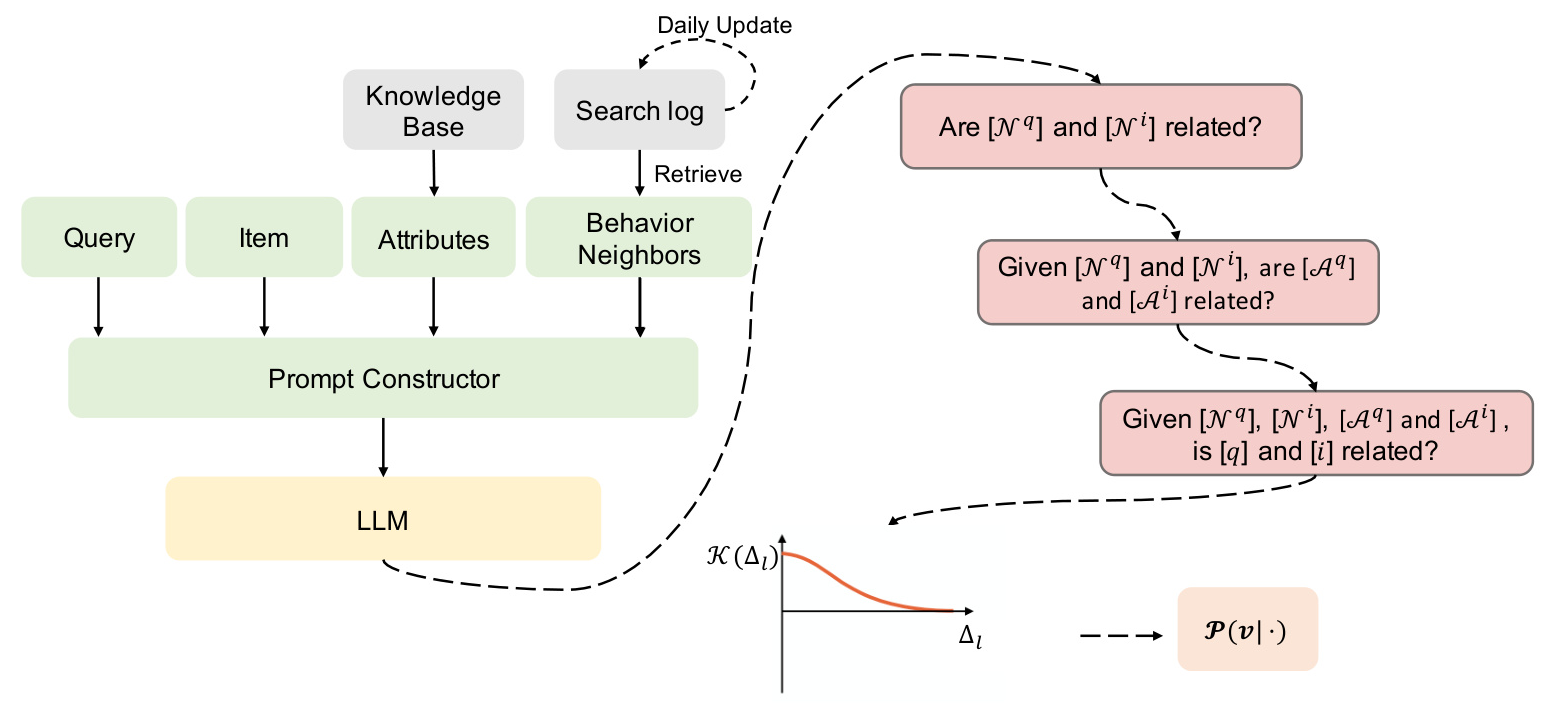
Proposed Framework: ProRBP
The ProRBP framework integrates search scenario-oriented knowledge with LLMs through two novel plug-in modules:
1. User-driven Behavior Neighbor Retrieval: This module retrieves domain-specific knowledge from daily updated search logs, identifying behavior neighbors that reflect users’ expectations.
2. Progressive Prompting and Aggregation: This module employs advanced prompting techniques to progressively improve LLM outputs, followed by aggregation to form a holistic relevance model.
Experimental Design
User-driven Behavior Neighbor Retrieval
This module filters high-confidence logs from daily search logs and calculates click-through rates to identify behavior neighbors. These neighbors are then used to construct daily prompts that guide LLMs in relevance modeling.


Progressive Prompting and Aggregation
Progressive prompting involves decomposing prompts into least-to-most steps, enhancing LLM sensitivity to relevance judgment. The aggregation process uses a kernel function to model the incremental importance of sub-tasks, leading to a unified relevance score.

Industrial Implementation
To handle the high volume of search traffic efficiently, an online and offline collaborative service is proposed. This involves using larger LLMs for offline inference and smaller distilled LLMs for online serving, ensuring cost-effectiveness and low latency.

Results and Analysis
Performance Comparison
The ProRBP framework was evaluated against several baseline models, including DSSM, ReprBert, Bert, MASM, TextGNN, AdsGNN, and BARL-ASe. The results demonstrated that ProRBP significantly outperformed these models across key metrics such as AUC, F1-score, and False Negative Rate (FNR).

Ablation Study
An ablation study was conducted to assess the contributions of the key modules in ProRBP. The results indicated that both the behavior neighbor retrieval and progressive prompting and aggregation modules significantly enhance model performance.
Parameter Sensitivity
The impact of various hyper-parameters, including the number of behavior neighbors, the type of kernel functions, and the strength of sub-tasks, was analyzed. The findings highlighted the importance of these parameters in optimizing model performance.

Online A/B Testing
The ProRBP framework was deployed in the Alipay search platform, demonstrating significant performance gains in online A/B testing. The model improved valid PV-CTR by 0.33% and reduced the rate of irrelevant results by 1.07% points on average.
Overall Conclusion
The ProRBP framework represents a significant advancement in relevance modeling by effectively integrating LLMs with user behavior data. The novel modules for behavior neighbor retrieval and progressive prompting and aggregation enable the model to capture dynamic search intentions and provide stable, accurate relevance judgments. The industrial implementation ensures that the framework can handle large-scale search traffic efficiently, making it a valuable tool for enhancing user experience in search engines.
By leveraging the strengths of LLMs and user behavior data, ProRBP sets a new benchmark for relevance modeling, promising improved performance and user satisfaction in real-world search scenarios.


