





Authors:
Zhiyang Lu、Qinghan Chen、Zhimin Yuan、Ming Cheng
Paper:
https://arxiv.org/abs/2408.07825
Introduction
Scene flow estimation is a critical task in dynamic scene perception, providing 3D motion vectors for each point in a source frame from two consecutive point clouds. This foundational component aids in various downstream tasks such as object tracking, point cloud label propagation, and pose estimation. Traditional methods often rely on stereo or RGB-D images, but recent advances in deep learning have led to end-to-end algorithms specifically designed for scene flow prediction. However, these methods face challenges in global flow embedding, handling non-rigid deformations, and generalizing from synthetic to real-world datasets.
Methodology
Problem Definition
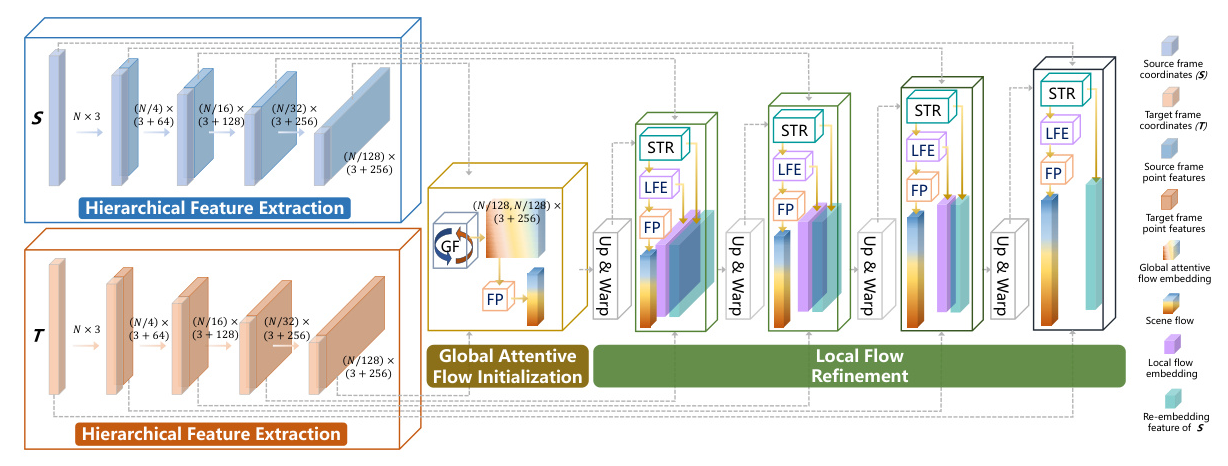
The scene flow task aims to estimate point-wise 3D motion information between two consecutive point cloud frames. The input includes the source frame ( S = {s_i}{i=1}^N = {x_i, f_i}{i=1}^N ) and target frame ( T = {t_j}{j=1}^M = {y_j, g_j}{j=1}^M ), where ( x_i, y_j \in \mathbb{R}^3 ) are 3D coordinates, and ( f_i, g_j \in \mathbb{R}^d ) represent point features. The goal is to predict the 3D motion vector ( SF = {sf_i \in \mathbb{R}^3}_{i=1}^N ) for each source frame point.
Hierarchical Feature Extraction
The proposed network utilizes PointConv as the feature extraction backbone to build a pyramid network. The process involves Farthest Point Sampling (FPS) to extract center points, K-Nearest Neighbor (KNN) to group neighbor points, and PointConv to aggregate local features, resulting in higher-level semantic features.


Global Fusion Flow Embedding
The Global Fusion (GF) module captures the global relation between consecutive frames during flow initialization. After multi-level feature extraction, the highest-level features ( S^ ) and ( T^ ) are used for global fusion flow embedding in both semantic context space and Euclidean space. The Dual Cross Attentive (DCA) Fusion module merges semantic contexts from both frames, enhancing mutual understanding before embedding.

The DCA module employs a cross-attentive mechanism to merge semantic contexts, yielding an attentive weight map for subsequent global aggregation. The initial global flow embedding ( GFE ) is constructed from both fusion semantic context and Euclidean space, and the final global fusion flow embedding ( GFFE ) is aggregated using the attentive weights.

Warping Layer
The warping layer upsamples the coarse sparse scene flow from the previous level to obtain the coarse dense scene flow of the current level. This dense flow is accumulated onto the source frame to generate the warped source frame, bringing the source and target frames closer for subsequent residual flow estimation.
Spatial Temporal Re-embedding
After the warping layer, the spatiotemporal relation between consecutive frames changes. The Spatial Temporal Re-embedding (STR) module re-embeds temporal features between the warped source frame and target frame, along with spatial features within the warped source frame. This re-embedding is performed in a patch-to-patch manner.

Flow Prediction
The Flow Prediction (FP) module combines PointConv, MLP, and a Fully Connected (FC) layer. For each point in the source frame, its local flow embedding feature, warped coordinates, and re-embedded features are input into the module. The final output is the scene flow, regressed through the FC layer.
Training Losses
Hierarchical Supervised Loss
A supervised loss is directly hooked to the ground truth (GT) of scene flow, leveraging multi-level loss functions as supervision to optimize the model across various pyramid levels.
Domain Adaptive Losses
Local Flow Consistency (LFC) Loss
Dynamic objects in real-world scenes typically undergo local rigid motion, manifested through the consistency of local flow. The LFC loss measures the predicted flow difference between each point and its KNN+Radius points group in the source frame.
Cross-frame Feature Similarity (CFS) Loss
The semantic features of points in the warped source frame should be similar to those in the surrounding target frame. The CFS loss penalizes points that exhibit a similarity lower than a specified threshold.
The final loss of the model is a combination of the supervised loss, LFC loss, and CFS loss.
Experiments
Datasets and Data Preprocessing
Experiments were performed on four datasets: the synthetic dataset FlyThings3D (FT3D) and three real-world datasets including Stereo-KITTI, SF-KITTI, and LiDAR-KITTI. These datasets were preprocessed to remove non-corresponding points or retain occluded points using mask labels.

Experimental Settings
The model was implemented with PyTorch 1.9 and trained on an NVIDIA RTX3090 GPU. The AdamW optimizer was used with an initial learning rate of 0.001, decayed by half every 80 epochs. The model was trained for 900 epochs with a batch size of 8. Cross-attention was utilized with head = 8 and ( d_a = 128 ).
Results and Analysis
The method exhibits remarkable generalization across various scenarios, outperforming recent state-of-the-art methods on the FT3Ds and KITTIs datasets. The model achieves significant improvements in real-world datasets, demonstrating exceptional generalization performance.

Ablation Study
Ablation experiments were conducted to investigate the distinct impacts of the GF, STR, and DA Losses modules. The results highlight the importance of the DCA Fusion, external position encoder, and the effectiveness of the LFC and CFS losses.

Conclusion
The SSRFlow network accurately and robustly estimates scene flow by conducting global semantic feature fusion and attentive flow embedding in both Euclidean and context spaces. The Spatial Temporal Re-embedding module effectively re-embeds deformed spatiotemporal features within local refinement. The Domain Adaptive Losses enhance the generalization ability of SSRFlow on various pattern datasets. Experiments show that the method achieves state-of-the-art performance on multiple distinct datasets.


