





Authors:
Karl El Hajal、Ajinkya Kulkarni、Enno Hermann、Mathew Magimai.-Doss
Paper:
https://arxiv.org/abs/2408.10771
Introduction
In recent years, neural text-to-speech (TTS) synthesis has made significant strides, achieving a level of naturalness that closely mimics human speech. This progress has enabled a wide range of expressive outputs. However, the development of zero-shot multi-speaker TTS systems, which can synthesize speech in an unseen speaker’s voice based on short reference samples, remains a challenging task. Traditional approaches often require extensive transcribed speech datasets from numerous speakers and complex training pipelines.
Self-supervised learning (SSL) speech features have emerged as effective intermediate representations for TTS, enabling straightforward and robust voice cloning. This study introduces SSL-TTS, a lightweight and efficient zero-shot TTS framework trained on transcribed speech from a single speaker. SSL-TTS leverages SSL features and retrieval methods for simple and robust zero-shot multi-speaker synthesis, achieving performance comparable to state-of-the-art models that require significantly larger training datasets.
Related Work
Recent zero-shot multi-speaker TTS models, such as XTTS and HierSpeech++, have demonstrated impressive quality and similarity to unseen speakers. However, these models require end-to-end training on thousands of hours of transcribed audio data from a large number of speakers to generalize effectively. Simultaneously, kNN-VC has emerged as a promising any-to-any voice conversion method, leveraging SSL features for zero-shot conversion. It uses a kNN algorithm to match frames from the source speaker with the target speaker’s representations, adjusting the speaker identity while preserving speech content.
Building on these insights, SSL-TTS proposes a lightweight framework for multi-speaker zero-shot TTS that leverages SSL features encapsulating both speaker and linguistic information. This approach modifies the target voice in a non-parametric manner and obviates the need for multi-speaker transcribed data for training.
Research Methodology
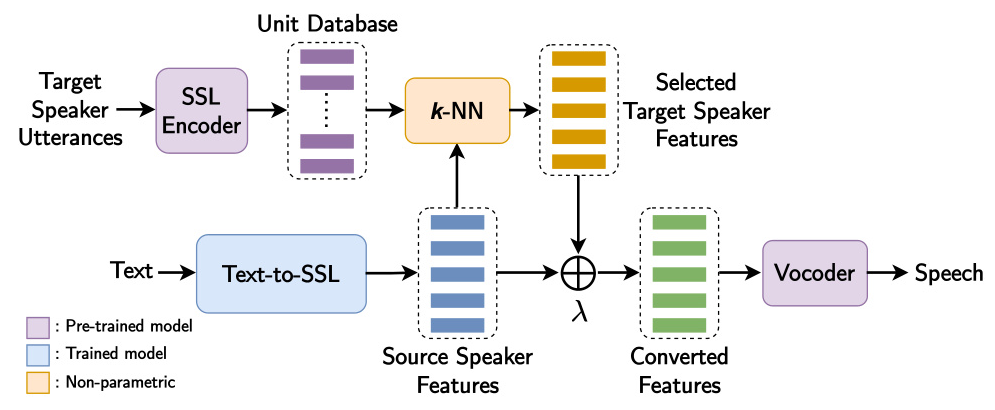
SSL-TTS Framework
The SSL-TTS framework begins with a Text-to-SSL model that generates source speaker features from text input. A kNN retrieval algorithm then matches these generated features to units in a target speaker’s unit database, which contains features pre-extracted from the target speaker’s recordings using a pre-trained, general-purpose SSL encoder. The selected target speaker features are linearly interpolated with the source speaker features to obtain the converted features. Finally, these converted features are decoded back into a waveform using a pre-trained vocoder.


Components of the Framework
-
SSL Encoder: The SSL encoder provides intermediate audio representations that encompass both linguistic and speaker-specific information. These features should exhibit similar phonetic properties while preserving speaker identity and should be decodable back to waveform without loss of information.
-
Text-to-SSL Model: This model generates corresponding SSL features from a given text input. It is the only component that requires audio data paired with text transcriptions for training, and it can be trained on the speech of a single speaker.
-
kNN Retrieval: The kNN algorithm selects units from the target speaker unit database to replace corresponding frames from the source speaker features. This process maintains the phonetic information while replacing the voice characteristics with those of the target speaker.
-
Vocoder: The vocoder decodes the SSL features back into a waveform. It should be pre-trained on a large and diverse dataset to ensure robust generalization across different speakers and contexts.
Experimental Design
Model Implementation
-
SSL Encoder: The pre-trained WavLM-Large encoder is used to derive representations from speech utterances. Features are extracted from the 6th layer of the model, which encapsulates both phonetic and speaker characteristics.
-
Text-to-SSL Models: Two implementations are evaluated: GlowTTS and GradTTS. Both models are trained on the LJSpeech dataset, which comprises 24 hours of single-speaker English speech. GlowTTS is trained for 650k steps, and GradTTS for 2M steps.
-
kNN Retrieval: For each source frame, its cosine distance with every target speaker frame within the unit database is computed. The k closest units are selected and averaged with uniform weighting. A value of k = 4 is used.
-
Vocoder: A pre-trained HiFi-GAN V1 model is used to reconstruct 16kHz waveforms from WavLM-Large layer 6 features. The model checkpoint was trained on the LibriSpeech train-clean-100 set.
Baselines
The proposed models are compared with the best performing open models for zero-shot multi-speaker TTS: YourTTS, XTTS, and HierSpeech++. These models employ various speaker encoders to convert a reference utterance into a style embedding and are trained on large datasets of transcribed speech from numerous speakers.
Evaluation
-
Objective Analysis: Performance is evaluated in terms of naturalness using UTMOS, intelligibility using word error rate (WER) and phoneme error rate (PER), and speaker similarity using speaker encoder cosine similarity (SECS).
-
Subjective Evaluation: A listening test is conducted to assess naturalness and similarity mean opinion scores (N-MOS and S-MOS). Each utterance is rated by 10 raters on naturalness and similarity to a ground-truth recording.
-
Model Efficiency: Models are compared based on the number of parameters, peak GPU memory usage during test sample synthesis, and real-time factor (RTF).
-
Controllability: The interpolation parameter is used to compute the SECS of the model’s output with the target speaker’s ground truth data for various values of λ.
Results and Analysis
Objective and Subjective Metrics
Results reveal that the SSL-TTS models demonstrate the best speaker similarity, XTTS excels in intelligibility, and HierSpeech++ achieves the highest naturalness. Subjective evaluations show that listeners rated HierSpeech++ highest for naturalness and similarity, while the SSL-TTS models and XTTS performed similarly. These models’ results fall within each other’s confidence intervals, suggesting comparable performance.

Model Efficiency
SSL-TTS models have the fewest parameters and lowest memory requirements among the top performers. Notably, GlowTTS-SSL requires 3× less memory than HierSpeech++ with comparable speed. GradTTS-SSL’s memory usage and RTF are higher due to the 100 iterations used in the diffusion decoder. Further, the SSL-TTS models are trained on 100× less transcribed data than HierSpeech++ and 1000× less data than XTTS.
Controllability
The speaker similarity matrix illustrates the results of the controllability experiment. The similarity of the outputs to the target speaker gradually increases as λ rises, demonstrating the framework’s ability to blend source and target styles in a fine-grained manner.

Ablation Studies
Ablation studies evaluate the models’ outputs with varying amounts of reference utterances. Approximately 30 seconds of reference utterances are needed to achieve suitable intelligibility, while naturalness improves up to 5 minutes. The baselines benefit less from increasing the amount of reference utterances beyond 10 to 30 seconds.

Overall Conclusion
State-of-the-art zero-shot multi-speaker TTS models rely on large datasets of transcribed speech from thousands of speakers for training. This study demonstrated that by combining SSL features and kNN retrieval methods, a lightweight TTS system can be developed that achieves a comparable level of naturalness and similarity to other approaches while requiring transcribed data from only a single speaker. The simplicity of the training process, where only the Text-to-SSL model requires training, is one of the main advantages of this approach. This simplicity, in conjunction with the kNN approach’s cross-lingual capability, is particularly appealing for extending the model to new languages and domains with fewer resources.
Future work will explore techniques to address the limitation of fixed pronunciation durations and further optimize the retrieval process. The framework’s ability to implement different Text-to-SSL model architectures allows for model swapping to leverage different benefits, making it a versatile and efficient solution for zero-shot multi-speaker TTS.


