





Authors:
Huafeng Chen、Dian Shao、Guangqian Guo、Shan Gao
Paper:
https://arxiv.org/abs/2408.10777
Introduction
Camouflaged Object Detection (COD) is a challenging task in computer vision that involves identifying objects that blend seamlessly into their surroundings. This task is not only difficult for models but also for human annotators, as it requires precise pixel-wise annotations, which are labor-intensive and time-consuming. Traditional methods demand extensive annotation efforts, often taking up to 60 minutes per image. To address this issue, the authors propose a novel approach that leverages point-based supervision, significantly reducing the annotation burden while maintaining high detection accuracy.
Related Work
Weakly Supervised Camouflaged Detection
Recent research has explored weakly supervised methods to reduce the annotation cost in COD. For instance, CRNet uses scribble annotations instead of pixel-wise labels. However, scribble annotations can be inconsistent and challenging to control, leading to suboptimal model performance.
Point Annotation
Point annotations have been explored in various segmentation tasks, including weakly-supervised segmentation and instance segmentation. These methods focus on class-specific categories, which differ from the COD task. PSOD, a weakly-supervised Salient Object Detection (SOD) method, uses point supervision but requires additional edge detectors and computationally intensive algorithms, making it unsuitable for COD.
Contrastive Learning
Contrastive learning aims to learn robust feature representations by attracting positive sample pairs and repulsing negative ones. Methods like Moco, BYOL, and SimSiam have demonstrated the effectiveness of unsupervised contrastive learning (UCL) in achieving strong generalization and representation capabilities.
Research Methodology
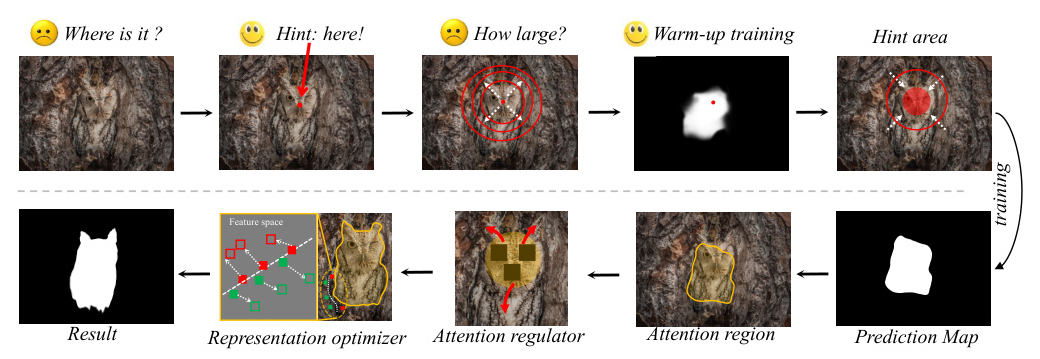
The proposed framework consists of three main components: a hint area generator, an attention regulator, and a representation optimizer. These components work together to enhance the model’s ability to detect camouflaged objects using point-based supervision.
Hint Area Generator
The hint area generator expands a single point annotation into a larger region, providing more supervision while minimizing noise. This process involves initializing a small square area around the annotated point and then estimating the pseudo area size of the camouflaged object using a trained encoder. The final hint area is a circular region around the point, ensuring accurate and effective supervision.
Attention Regulator
The attention regulator addresses the issue of partial detection by scattering the model’s attention across the entire object. This is achieved by randomly masking the annotated region, forcing the model to explore and recognize surrounding areas. This approach helps the model focus on the whole object rather than just the most discriminative parts.
Representation Optimizer
The representation optimizer uses UCL to enhance the feature representation of camouflaged objects. By applying different visual transformations to the input images, the model learns invariant patterns and stable representations, improving its ability to distinguish camouflaged objects from the background.
Experimental Design
Dataset
The experiments are conducted on three COD benchmarks: CAMO, COD10K, and NC4K. The authors relabeled 4040 images (3040 from COD10K and 1000 from CAMO) to create the Point-supervised Dataset (P-COD) for training. The remaining images are used for testing.
Evaluation Metrics
The performance of the proposed method is evaluated using four metrics: mean absolute error (MAE), S-measure (Sm), E-measure (Em), and weighted F-measure (Fwβ).
Implementation Details
The method is implemented using PyTorch and trained on a GeForce RTX4090 GPU. The training process involves using the stochastic gradient descent optimizer with a momentum of 0.9, a weight decay of 5e-4, and a triangle learning rate schedule with a maximum learning rate of 1e-3. The batch size is set to 8, and the training epoch is 60.
Results and Analysis
Quantitative Comparison
The proposed method outperforms existing weakly-supervised and fully-supervised COD methods across multiple datasets. It achieves significant improvements in MAE, Sm, Em, and Fwβ, demonstrating its effectiveness in detecting camouflaged objects with minimal supervision.


Qualitative Evaluation
The visual comparison shows that the proposed method produces clearer and more complete object regions with sharper contours, outperforming state-of-the-art weakly supervised COD methods in various challenging scenarios.

Parameter Complexity
The proposed model has lower parameter complexity and computational cost compared to fully supervised methods, while still achieving superior performance.

Ablation Studies
The ablation studies demonstrate the effectiveness of each component of the proposed framework. The hint area generator, attention regulator, and representation optimizer all contribute to the model’s improved performance.

Overall Conclusion
The proposed point-supervised COD method significantly reduces the annotation burden while achieving high detection accuracy. By leveraging a hint area generator, attention regulator, and representation optimizer, the method effectively detects camouflaged objects with minimal supervision. The experimental results demonstrate that the proposed method outperforms existing weakly-supervised and fully-supervised COD methods, showcasing its potential for real-world applications.

The research provides a promising direction for future work in camouflaged object detection, highlighting the importance of efficient and effective annotation strategies.


