





Authors:
Yuqing Zhao、Divya Saxena、Jiannong Cao、Xiaoyun Liu、Changlin Song
Paper:
https://arxiv.org/abs/2408.10566
Introduction
Continual learning (CL) is a critical area in machine learning that focuses on enabling models to learn continuously from a stream of data. This is particularly important in dynamic environments such as autonomous vehicles, healthcare, and smart cities, where models need to adapt to new data while retaining previously learned knowledge. However, a significant challenge in CL is the degradation of performance on previously learned tasks when the model’s capacity is increased to accommodate new data. This phenomenon, termed growth-induced forgetting (GIFt), is especially problematic in task-agnostic CL settings where the task label is unavailable, and the entire model, including expanded parameters, is used for inference.
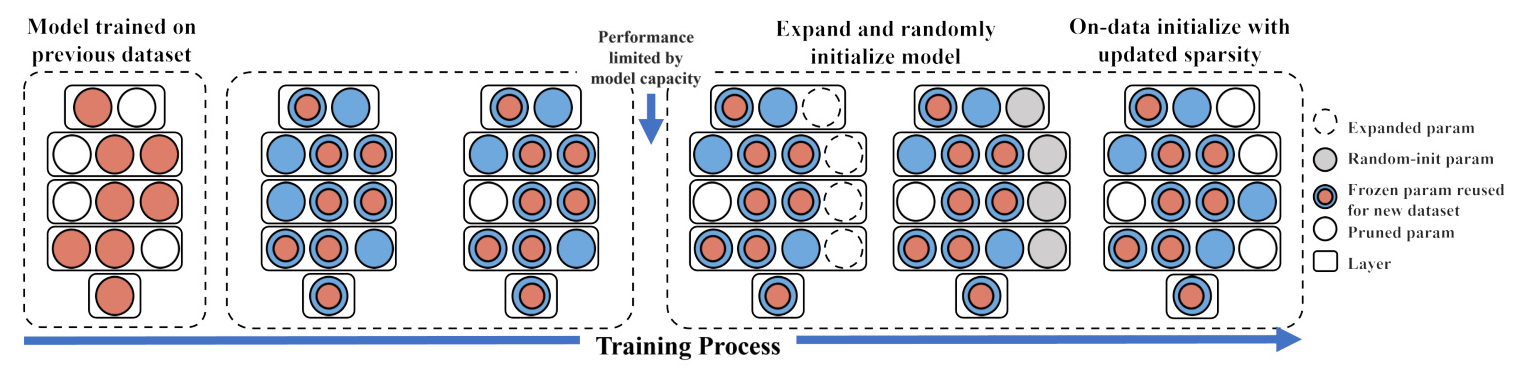
In this study, we introduce SparseGrow, a novel approach to mitigate GIFt while enhancing the model’s adaptability to new data. SparseGrow employs data-driven sparse layer expansion to control parameter usage during model growth, reducing the negative impact of excessive growth and functionality changes. Additionally, it combines sparse growth with on-data initialization at the late stage of training to create partially zero-valued expansions that fit the learned distribution, thereby enhancing retention and adaptability.
Related Work
Growing Approaches
There are three principal model growth methods in CL:
- Layer Expansion (LayerExp): This method grows the model in width by widening each layer.
- Lateral Connection (LatConn): This method introduces new lateral layers connected to adjacent layers, also growing the model in width.
- In-Depth Growth (ID-Grow): This method adds hidden layers to increase the model’s depth.
Lateral Connection
Several studies have explored lateral connections for CL. For instance, Progressive Neural Networks (PNNs) statically grow the architecture with randomly initialized modules while retaining lateral connections to previously frozen modules. Other methods, such as VariGrow, detect new tasks through an energy-based novelty score and grow a new expert module to handle them.
Layer Expansion
Layer expansion has been explored in various contexts. For example, Dynamic Expandable Networks (DEN) grow every layer if the loss does not meet a threshold. Other methods expand the number of filters for new tasks and adopt gradual pruning to compact the model.
In-Depth Growth
In-depth growth methods add new layers atop existing ones. However, deepening the model tends to change the model architecture, making it less general for complex models and often affecting knowledge retention.
Overcoming Growth-Induced Forgetting
Some studies have indirectly addressed GIFt by focusing on preserving knowledge post model growth. For example, Quick Deep Inversion recovers prior task visual features to enhance distillation. Other methods freeze previously learned representations and augment them with additional feature dimensions from a new learnable feature extractor.
Research Methodology
Problem Formulation
The goal is to enhance model adaptation to new data by expanding model capacity while addressing GIFt in task-agnostic scenarios, covering domain-incremental and class-incremental learning. Given a sequence of non-iid datasets {D1, D2, …, Dt} and a model f(·; θt) trained on previous datasets, the objective is to grow the model capacity to improve accuracy on Dt and future datasets while minimizing performance degradation on previous datasets.
Sparse Neural Expansion
Sparse neural expansion consists of layer expansion and dynamic sparse training. It focuses on model expansion to increase capacity, allowing better adaptation to new data. Additionally, dynamic sparse training is integrated within layers to help better control expansion sparsity and granularity using a data-driven approach.
Layer Expansion
Layer expansion enables more general and fine-grained model growth without significantly altering model functionality. For each neural network layer, the expansion technique involves expanding the weight and bias tensors to accommodate the desired expansion.
Dynamic Sparse Training
Dynamic sparse training involves applying a binary mask to each parameter, setting unimportant parameters to 0. This is done using a trainable pruning threshold vector and a unit step function. The training loss function incorporates a sparse regularization term to train a sparse neural network directly using backpropagation.
On-Dataset Frozen Initialization
On-dataset frozen initialization involves employing both random initialization and on-dataset finetuning while freezing learned parameters. This approach ensures less forgetting by adapting the expanded parameters to the current distribution at the final phase of training.
Task-Agnostic Freezing
Task-agnostic freezing involves setting the gradients of masked parameters to zero during the update step of the optimization algorithm. This approach helps preserve certain knowledge within the model, particularly beneficial in scenarios that require task-agnostic adaptation while retaining previously learned information.
Experimental Design
Datasets
The domain-incremental datasets used in this study include Permuted MNIST, FreshStale, and DomainNet. For evaluation in class-incremental settings, the class-incremental MNIST dataset is used.
- Permuted MNIST: A variation of the MNIST dataset with randomly permuted pixel positions.
- FreshStale: A dataset comprising images of fruits and vegetables classified as either fresh or stale.
- DomainNet: A dataset with four domains (real photos, clipart, quickdraw, and sketch) categorized into 345 classes per domain.
Evaluation Metrics
The evaluation metrics used in this study include:
- Average Accuracy (AAC): The average accuracy across all tasks.
- Backward Transfer (BWT): Measures the influence of learning new tasks on the performance of previously learned tasks.
- Forward Transfer (FWT): Measures the influence of learning previous tasks on the performance of new tasks.
Experiment Settings
All baselines are applied on ResNet-18 as the base network for the experiments. The seed value is set to ensure reproducibility, and the PyTorch backends are configured to avoid using non-deterministic algorithms.
Baselines
The baselines for comparison include:
- Classic and recent baselines without model growth: SGD, EWC, LwF, PRE-DFKD, PackNet, AdaptCL.
- Baselines for model growth comparison: SGD+LayerExp, SGD+IDGrow, SGD+LatConn, SGD+LayerExp+ODInit.
- Baselines with layer expansion and on-data initialization: EWC+LayerExp, LwF+LayerExp, PRE-DFKD+LayerExp.
Results and Analysis
Comparison of Model Growth Techniques
The performance evaluation of different model growth methods on the Permuted MNIST dataset is summarized in Table 1. The results show that layer expansion mitigates GIFt and promotes backward knowledge transfer, consequently increasing the overall model accuracy with only a 1.2% rise in parameters. Other growth methods exhibit significant GIFt, leading to reduced average accuracy.


Comprehensive Comparison with More Tasks
Figure 3 depicts the average accuracy fluctuation with an increasing number of tasks or domains for various baseline methods. The comparison between SparseGrow and AdaptCL emphasizes the importance of appropriate model growth in enhancing adaptability facing more domains. SparseGrow achieves the best performance, with its effectiveness improving as the number of domains rises.

Addressing Growth-Induced Forgetting Evaluation
The ability of different CL methods to reduce GIFt across diverse applications is evaluated using the FreshStale and DomainNet datasets. Figures 4 and 5 visualize the epoch-wise average accuracy of different baseline methods on these datasets. The results reveal that SparseGrow consistently demonstrates the most stable reduction in model forgetting, achieving the highest AAC.

Class-Incremental Learning Setting Results
The performance of SparseGrow in class-incremental learning scenarios is depicted in Table 4. SparseGrow excels in preserving accuracy significantly, highlighting its potential in mitigating forgetting in task-agnostic environments.

Overall Conclusion
This study addresses the crucial issue of growth-induced forgetting caused by improper model growth in task-agnostic continual learning. By identifying layer expansion as a promising fundamental model growth technique, we propose SparseGrow to boost adaptability and knowledge retention. Experimental validations demonstrate the effectiveness of SparseGrow in mitigating growth-induced forgetting and improving knowledge retention for incremental tasks. Future research could aim to optimize the timing of model growth and leverage techniques such as neural architecture search to further enhance the model’s adaptability and overall performance with new data.


