





Authors:
Zijian Dong、Yilei Wu、Zijiao Chen、Yichi Zhang、Yueming Jin、Juan Helen Zhou
Paper:
https://arxiv.org/abs/2408.10567
Introduction
In the realm of neuroimaging, the advent of large-scale, self-supervised pre-trained models for functional magnetic resonance imaging (fMRI) has shown significant promise in enhancing performance across various downstream tasks. However, fine-tuning these models is computationally intensive and time-consuming, often leading to overfitting due to the scarcity of training data. This study introduces Scaffold Prompt Tuning (ScaPT), a novel framework designed to efficiently adapt large-scale fMRI pre-trained models to downstream tasks with minimal parameter updates and improved performance.
Related Work
Fine-Tuning in fMRI Models
Fine-tuning involves updating all pre-trained parameters using target task training data. While effective, this approach is computationally demanding and prone to overfitting, especially with limited data. Additionally, it can distort the learned feature space, reducing the model’s generalizability.
Prompt Tuning in NLP
In natural language processing (NLP), soft prompt tuning has emerged as an efficient alternative for adapting large language models (LLMs). This technique keeps the original model frozen and only trains soft prompts prepended to the input. Despite its efficiency, prompt tuning often results in decreased task performance compared to fine-tuning and fails to leverage the extensive knowledge embedded in high-resource tasks.
Multitask Transfer Learning
Several works in NLP have designed prompt tuning strategies under a multitask transfer learning framework, transferring knowledge from high-resource tasks to low-resource ones. However, these methods either overlook the intricate relationship between prompts and input or fail to capture the input’s different aspects for various tasks, making them suboptimal for clinical applications.
Research Methodology
Problem Setup
Given an fMRI pre-trained model ( f(\cdot) ) with parameters ( \theta ) and a high-resource fMRI dataset ( D ), the goal is to learn a new low-resource task ( T_{target} ) by efficiently updating a small subset of parameters ( \phi ) using the target task dataset ( D’ ).
Scaffold Prompt Tuning (ScaPT)
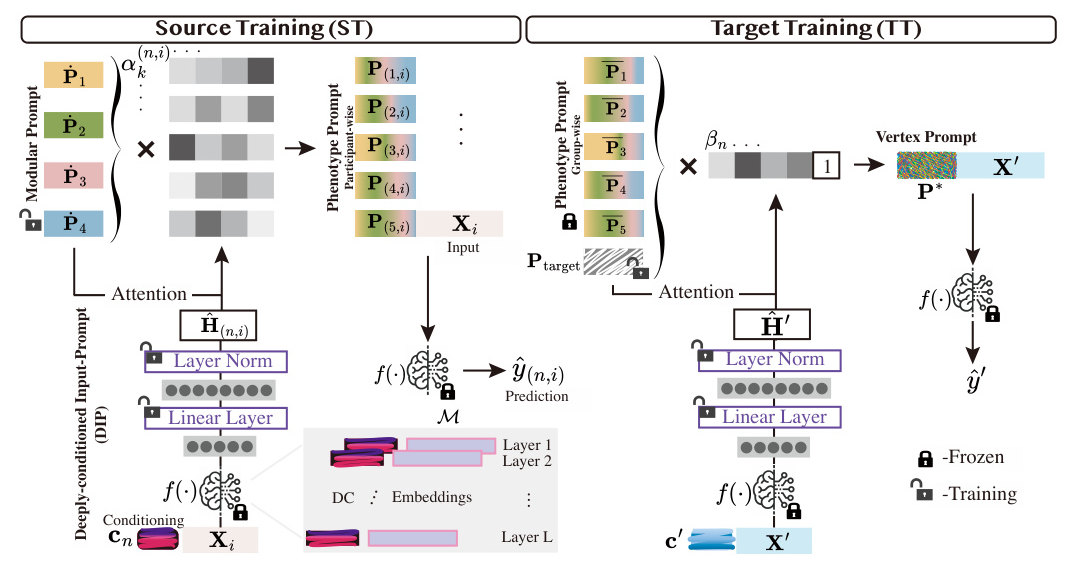
ScaPT operates in two stages: Source Training (ST) and Target Training (TT). In ST, modular prompts are interpolated to create participant-wise phenotype prompts, which are then averaged to formulate group-wise phenotype prompts. In TT, these group-level phenotype prompts are combined with a new target prompt to create a participant-wise vertex prompt for the target task.
Deeply-conditioned Input-Prompt (DIP) Mapping
To address the mismatch between soft prompts and input embedding spaces, ScaPT introduces a Deeply-conditioned Input-Prompt (DIP) mapping module. This module uses learnable deep conditioning tokens to guide the pre-trained model in mapping the input to an appropriate prompt space, enhancing the reliability of attention between inputs and prompts.
Experimental Design
Datasets
- Source Training (ST): Resting state fMRI data from 656 participants of the Lifespan Human Connectome Project Aging (HCP-A) were analyzed to predict 38 phenotypes, alongside sex and age.
- Target Training (TT): ScaPT was assessed on two classification tasks for neurodegenerative disease diagnosis/prognosis using the Alzheimer’s Disease Neuroimaging Initiative (ADNI) and a regression task for personality trait prediction using the UK Biobank (UKB).
Training Details
The state-of-the-art fMRI language model with a causal sequence modeling structure was used for downstream adaptation. The pre-trained model contains 4 GPT-2 layers with 12 attention heads in each self-attention module. The input must be parcellated by Dictionaries of Functional Modes (DiFuMo).
Results and Analysis
Main Results
ScaPT demonstrated superior performance over fine-tuning and other prompt tuning methods across various sizes of training datasets, scaling well with the number of training data. This underscores ScaPT’s effectiveness in transferring knowledge from high-resource tasks to those with scarce resources.
Classification and Regression Performance
- CN vs. MCI Classification: ScaPT outperformed fine-tuning and other prompt tuning methods in accuracy and F1 score across different training dataset sizes.
- Amyloid Positive vs. Negative Classification: ScaPT showed significant improvement in both accuracy and F1 score compared to other methods.
- Neuroticism Score Prediction: ScaPT achieved lower mean absolute error (MAE) and higher Pearson correlation (ρ) than other methods, demonstrating its effectiveness in regression tasks.



Prompt Interpretation
In the ST stage, phenotype prompts naturally formed clusters corresponding to different brain-behavior associations, such as Personality, Social Emotion, and Cognition. During the TT stage, attention scores between input and phenotype prompts provided semantic interpretation for target tasks, aligning well with the literature.

Ablation Study and Parameter Efficiency
ScaPT outperformed its ablations, demonstrating the importance of high-resource task knowledge and the effectiveness of the DIP module. Despite updating only 2% of total parameters, ScaPT significantly outperformed fine-tuning and other prompt tuning methods, highlighting its parameter efficiency.
Overall Conclusion
Scaffold Prompt Tuning (ScaPT) is a novel framework for efficiently adapting large-scale fMRI pre-trained models to downstream tasks with limited training data. By leveraging a hierarchical prompt structure and a Deeply-conditioned Input-Prompt (DIP) mapping module, ScaPT achieves superior performance and parameter efficiency. Future studies could expand ScaPT’s application to longitudinal data and explore its potential for prompting vision models.
This study was supported by various grants from the Singapore National Medical Research Council, A*STAR, Ministry of Education, and the Yong Loo Lin School of Medicine Research Core Funding, National University of Singapore. The authors have no competing interests to declare.


