





Authors:
Yu Liu、Baoxiong Jia、Yixin Chen、Siyuan Huang
Paper:
https://arxiv.org/abs/2408.06697
Introduction
The paper “SlotLifter: Slot-guided Feature Lifting for Learning Object-centric Radiance Fields” introduces a novel approach to learning object-centric representations in 3D scenes. This method, named SlotLifter, aims to address the challenges of scene reconstruction and decomposition by leveraging slot-guided feature lifting. The approach integrates object-centric learning representations with image-based rendering methods, achieving state-of-the-art performance in scene decomposition and novel-view synthesis on both synthetic and real-world datasets.
Background
Object-centric Learning
Object-centric learning focuses on disentangling visual scenes into object-like entities for reasoning and manipulation. Traditional methods have primarily focused on 2D images, which limits their ability to capture 3D attributes such as shape, geometry, and spatial relationships. Recent advancements have attempted to combine object-centric methods with 3D representations, but these approaches often struggle with real-world scenarios due to the complexity of aggregating multi-view information.
Neural Radiance Fields (NeRFs)
NeRFs have shown significant success in novel-view synthesis and 3D scene reconstruction. However, they require long training times for each scene and lack generalization capabilities. Generalizable NeRF methods aim to synthesize novel views based on given images without per-scene optimization, but they still face challenges in efficiently encoding 3D complex scenes.
SlotLifter Model
Overview
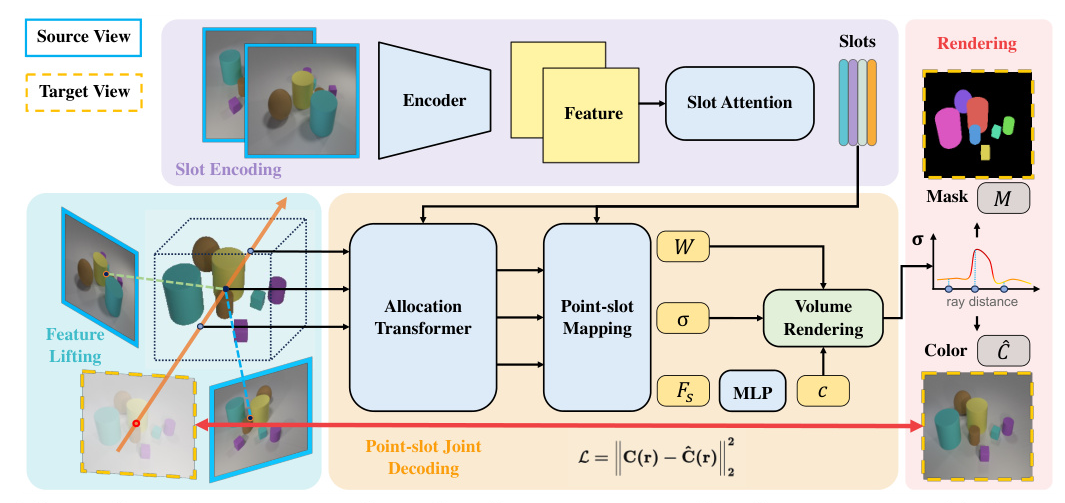
SlotLifter combines object-centric learning modules with image-based rendering techniques to effectively learn scene reconstruction and decomposition. The model leverages lifted 2D input-view features to initialize 3D point features, which interact with learned slot representations via a cross-attention-based transformer for predicting volume rendering parameters. This design enhances the granularity of details for novel-view synthesis while providing explicit guidance for slot learning.


Scene Encoding
SlotLifter uses Slot-Attention to encode scene representations from source views and lifts 2D features to 3D for approximating the latent feature field. The process involves extracting 2D feature maps from each source view, obtaining object-centric scene features via Slot-Attention, and constructing a 3D scene feature field by lifting 2D input-view features.
Point-slot Mapping
After scene encoding, SlotLifter employs a point-slot joint decoding process to leverage both point and slot features for rendering. This involves calculating the point-slot mapping, identifying the points that a slot contributes to, and using a cross-attention-based allocation transformer to allocate slots to 3D points. The model predicts density values and colors for rendering novel-view images and segmentation masks via volume rendering.
Training
SlotLifter is trained using the mean squared error (MSE) between the rendered rays and the ground truth colors. To avoid degenerate scenarios where the model relies solely on lifted features, a random masking scheme is employed during training. This enforces alignment between slots and 3D point grids.
Experiments
Datasets and Metrics
SlotLifter is evaluated on four synthetic and four real-world datasets. The quality of novel-view synthesis is measured using LPIPS, SSIM, and PSNR metrics, while scene decomposition quality is assessed using Adjusted Rand Index (ARI), FG-ARI, NV-ARI, and NV-FG-ARI.
Results
Synthetic Scenes
SlotLifter outperforms existing 3D object-centric learning methods on synthetic datasets, achieving the best performance across all metrics. The model handles occlusion between objects better and offers more complete segmentation compared to baseline models.



Real-world Scenes
SlotLifter demonstrates significant improvements in object-centric learning and novel-view synthesis on real-world datasets. The model renders segmentation masks with higher quality and achieves more accurate segmentation masks compared to existing methods.


Ablative Studies
Ablative studies highlight the effectiveness of SlotLifter’s design choices, including scene encoding, random masking, slot-based density, and the number of slots and source views. The feature lifting design is crucial for establishing the mapping between slots and 3D points, while random masking prevents the model from degenerating.








Conclusion
SlotLifter presents a novel approach to unsupervised 3D object-centric representation learning, achieving state-of-the-art performance in scene decomposition and novel-view synthesis. The model’s slot-guided feature lifting design enhances the interaction between lifted input view features and learned slots, resulting in significant improvements on both synthetic and real-world datasets. SlotLifter’s efficiency and effectiveness demonstrate its potential to advance 3D object-centric learning techniques for complex scenes.


