





Authors:
Huifa Li、Jie Fu、Xinpeng Ling、Zhiyu Sun、Kuncan Wang、Zhili Chen
Paper:
https://arxiv.org/abs/2408.10511
Single-cell Curriculum Learning-based Deep Graph Embedding Clustering: A Detailed Interpretive Blog
Introduction
The rapid advancement of single-cell RNA sequencing (scRNA-seq) technologies has revolutionized our ability to investigate cellular-level tissue heterogeneity. This technology allows for the measurement of gene expressions in individual cells, providing detailed and high-resolution insights into the complex cellular landscape. The analysis of scRNA-seq data is crucial in various biomedical research areas, including identifying cell types and subtypes, studying developmental processes, investigating disease mechanisms, exploring immunological responses, and supporting drug development and personalized therapy.
However, the analysis of scRNA-seq data presents significant challenges due to its intricate and indeterminate data distribution, characterized by a substantial volume and a high frequency of dropout events. Traditional clustering methods often produce suboptimal results due to the sparsity of scRNA-seq data. To address these challenges, the authors propose a novel approach called single-cell curriculum learning-based deep graph embedding clustering (scCLG).
Related Work
scRNA-seq Clustering
Traditional clustering methods such as K-means, spectral clustering, hierarchical clustering, and density-based clustering have been applied to scRNA-seq data. However, these methods often struggle with the sparsity and high dropout rates of scRNA-seq data. Several methods have been developed to address these limitations:
- CIDR, MAGIC, and SAVER: These methods address the issue of missing values (dropouts) and then cluster the imputed data. However, they face challenges in capturing the intricate inherent structure of scRNA-seq data.
- SIMLR and MPSSC: These methods utilize multi-kernel spectral clustering to acquire robust similarity measures but are hindered by computational complexity and fail to account for crucial attributes of transcriptional data.
Deep Learning Approaches
Recent deep learning clustering methods have shown promise in modeling the high-dimensional and sparse nature of scRNA-seq data:
- scziDesk, scDCC, and scDeepCluster: These models implement auto-encoding architectures but often ignore cell-cell relationships, making clustering more challenging.
- Graph Neural Networks (GNNs): Emerging GNNs like scGNN and scGAE combine deep autoencoder and graph clustering algorithms to preserve neighborhood relationships. However, their training strategies largely ignore the importance of different nodes in the graph and how their orders can affect optimization.
Curriculum Learning
Curriculum learning (CL) is an effective training strategy that mimics the human learning process by gradually guiding model learning in tasks with varying difficulty levels. CL has applications in natural language processing, computer vision, and other fields requiring complex data processing. However, its application in scRNA-seq data clustering remains unexplored.
Research Methodology
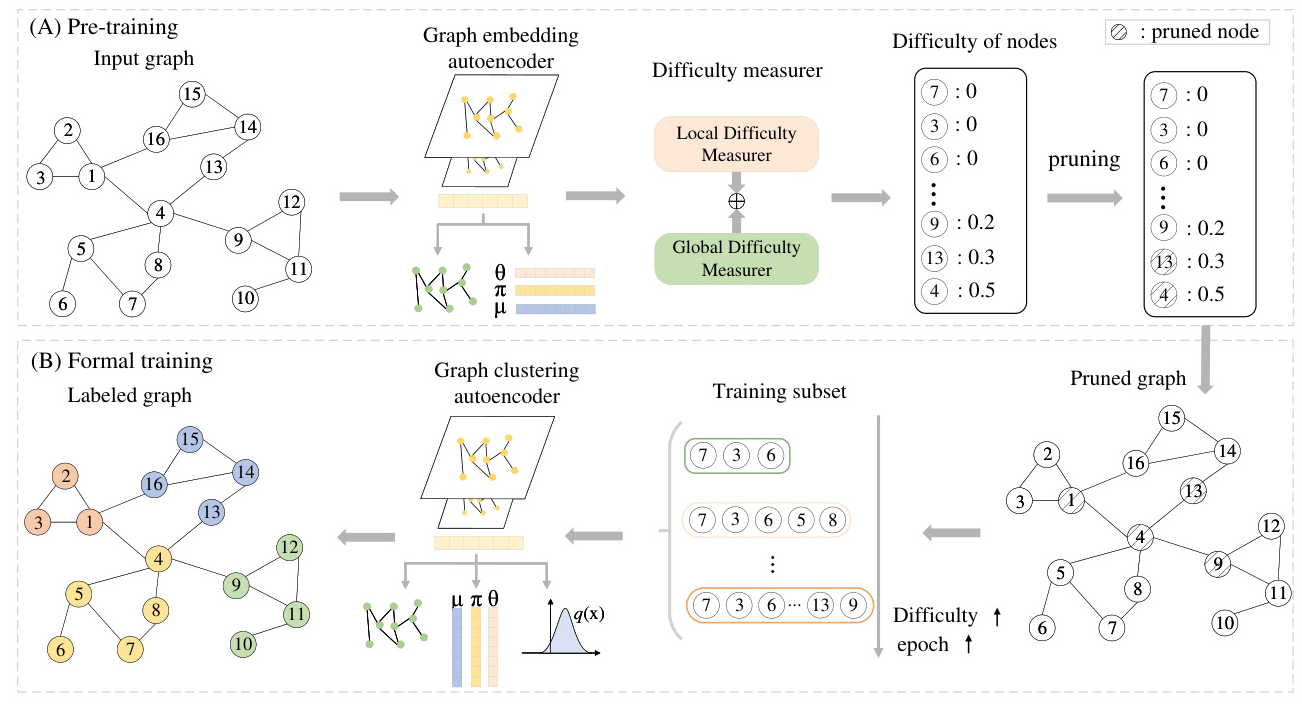
Chebyshev Graph Convolutional Autoencoder with Multi-Decoder (ChebAE)
The authors propose a Chebyshev graph convolutional autoencoder with multi-decoder (ChebAE) to preserve the topological structure of cells in a low-dimensional latent space. The ChebAE combines three optimization objectives corresponding to three decoders:
- Topology Reconstruction Loss: Preserves the cell-cell topology representation.
- Zero-Inflated Negative Binomial (ZINB) Loss: Captures the global probability structure of scRNA-seq data.
- Clustering Loss: Optimizes cell clustering label allocation.
Selective Training Strategy
The authors employ a selective training strategy to train the GNN based on the features and entropy of nodes. They prune difficult nodes based on difficulty scores to maintain a high-quality graph. The hierarchical difficulty measurer consists of two components:
- Local Difficulty Measurer: Identifies difficult nodes based on the diversity of their neighbors’ labels.
- Global Difficulty Measurer: Identifies difficult nodes by calculating node entropy and graph entropy.
Experimental Design
Dataset and Baselines
The authors evaluate their model on seven real scRNA-seq datasets from different organisms, with cell numbers ranging from 870 to 9519 and cell type numbers varying from 2 to 9. They compare the performance of scCLG with traditional clustering methods (K-means and Spectral) and several state-of-the-art scRNA-seq data clustering methods, including scziDesk, scDC, scDCC, scGMAI, scTAG, scGAE, and scGNN.
Implementation Details
The cell graph is constructed using the KNN algorithm with the nearest neighbor parameter ( k = 20 ). The hidden fully connected layers in the ZINB decoder are set at 128, 256, and 512. The model undergoes a two-phase training process: pre-training for 1000 epochs and formal training for 500 epochs. The pruning rate ( \alpha ) is set to 0.11. The model is optimized using the Adam optimizer with a learning rate of ( 5e-4 ) during pre-training and ( 1e-4 ) during formal training.
Results and Analysis
Clustering Performance
The results demonstrate that scCLG outperforms all baseline methods in terms of clustering performance on the seven scRNA-seq datasets. The model achieves the best Normalized Mutual Information (NMI) and Adjusted Rand Index (ARI) on all datasets, indicating its superior ability to learn key representations of scRNA-seq data in a meaningful order.


Parameter Analysis
The authors analyze the impact of different parameters on the model’s performance:
- Neighbor Parameter ( k ): The best performance is achieved with ( k = 20 ).
- Number of Variable Genes: The performance is optimal with 500 highly variable genes.
- Data Pruning Rate: The best performance is achieved with a pruning rate of ( \alpha = 0.11 ), indicating the effectiveness of pruning difficult nodes.

Ablation Study
The ablation study shows that each component of the scCLG method contributes to its overall performance. The hierarchical difficulty measurer and the pruning strategy significantly improve clustering performance.

Overall Conclusion
The proposed single-cell curriculum learning-based deep graph embedding clustering (scCLG) method effectively addresses the challenges of scRNA-seq data analysis. By integrating a Chebyshev graph convolutional autoencoder with a multi-decoder and employing a selective training strategy, scCLG preserves the topological structure of cells and optimizes cell clustering label allocation. The empirical results demonstrate that scCLG outperforms state-of-the-art methods, providing strong evidence of its ability to tackle difficult nodes and improve clustering performance.






